This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing. Go and sign up.
While Microsoft offers their own Azure Database product, there are other alternatives available that may be able to help you improve your MySQL performance. In this blog post, we compare Azure Database for MySQL vs. ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latencyperformance.
The Multicore Era Over the past ~15 years, server processors from Intel and AMD have evolved from the early quad-core processors to the current monsters with over 50 cores per socket. What about single-core performance? The example below is for a 2005-era processor with 60 ns memory latency and 6.4 cache lines -> 5.6
You can use it to visualize CPU utilization across your hosts, disk space used, server-side response time, web request/service failure rates, or any other area where you need to spot outliers immediately. This is useful for identifying performance bottlenecks and understanding the overall user experience.
This extends Dynatrace visibility into Citrix user experience and Citrix platform performance. Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace Extension: SAP ABAP platform performance. SAP server.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
Benefits of Caching Improved performance: Caching eliminates the need to retrieve data from the original source every time, resulting in faster response times and reduced latency. Reduced server load: By serving cached content, the load on the server is reduced, allowing it to handle more requests and improving overall scalability.
Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. The latency table for test D is as below.
These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. Automating Performance Tuning with Autoscalers Tuning the performance of our Apache Flink jobs is currently a manual process. This queue ensures we are consistently capturing raw events from our global userbase.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. These include Quality-of-Experience(QoE) measurements at the customer device level, Service-Level-Agreements (SLAs), and business-level Key-Performance-Indicators(KPIs).
Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination.
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. To launch Phase 1 safely, we used AB Testing.
High performance. Does it affect latency? Yes, you can see an increase in latency. So, if you’re hosting your application in AWS or Azure and move your database to DigitalOcean, you will see an increase in latency. Meltdown Performance Impact on MongoDB: AWS, Azure & DigitalOcean. Simple pricing.
When it comes to network performance, there are two main limiting factors that will slow you down: bandwidth and latency. Latency is defined as…. Where bandwidth deals with capacity, latency is more about speed of transfer 2. and reduction in latency. and reduction in latency. Bandwidth is defined as….
A lot of people surmise that TTFB is merely time spent on the server, but that is only a small fraction of the true extent of things. The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. But what else is TTFB?
By Jose Fernandez , Sebastien Dabdoub , Jason Koch , Artem Tkachuk The Compute and Performance Engineering teams at Netflix regularly investigate performance issues in our multi-tenant environment. Traditional performance analysis tools such as perf can introduce significant overhead, risking further performance degradation.
Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.
When serving and storing files on the web, there are a number of different things we need to take into consideration in order to balance ergonomics, performance, and effectiveness. Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? That’s almost 22× more!
When organizations implement SLOs, they can improve software development processes and application performance. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. SLOs improve software quality.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Platform performance —get visibility into the performance of the Citrix platform to optimize application delivery. Dynatrace Extension: SAP ABAP platform performance.
Sure, cloud infrastructure requires comprehensive performance visibility, as Dynatrace provides , but the services that leverage cloud infrastructures also require close attention. Well-defined APIs are required for managing such microservices and tracking changes in their performance. High latency or lack of responses.
By having appropriate indexes on your MySQL tables, you can greatly enhance the performance of SELECT queries. During this time, you are also likely to experience a degraded performance of queries as your system resources are busy in index-creation work as well. Performance Benefits of Rolling Index Creation. EC2 instance m4.large
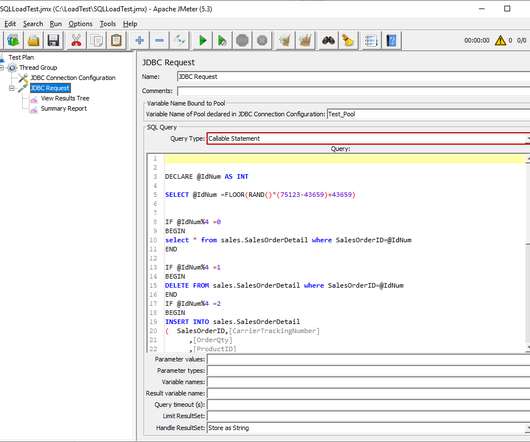
In this article, we will learn how to use Apache JMeter to perform a load test on SQL Server. This test type enables us to measure the application behaviors under specific conditions so that it enables us to observe a variety of resource consumptions (CPU, memory, latency, response times, etc) and it also helps to […].
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
You get all the multicore Anna performance you want, but you don’t pay for what you don’t need. Just to throw out some numbers, we measured Anna providing 355x the performance of DynamoDB for the dollar. Each storage server collects statistics about the requests it serves, the data it stores, etc.
So, for the last several years, I, along with other performance engineers like me, have been recommending that our clients move over from Gzip and to Brotli instead. Taking a very reductive and simplistic view of how files are transmitted from server to client, we need to look at TCP. Browser Support: A brief interlude. packet loss).
Critical assets are far too valuable to leave on someone else’s servers. Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. Risk: Service Shutdowns. to just 3.6s.
Despite the name, serverless computing still uses servers. This means companies can access the exact resources they need whenever they need them, rather than paying for server space and computing power they only need occasionally. If servers reach maximum load and capacity in-house, something has to give before adding new services.
Furthermore, tools like LangChain leverage large language models (LLM) as one of their basic building blocks for creating AI agents (think of AI agents as APIs that perform a series of chat interactions that target a desired outcome) which perform complex and potentially large queries against an LLM like GPT-4.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. Optimizing Lambda for performance. What is AWS Lambda? Data entering a stream.
Too many concurrent server requests can lead to website crashes if youre not equipped to deal with them. How To Design For High-Traffic Events Lets take a look at six ways to design websites for high-traffic events, without worrying about website crashes and other performance-related issues. Lets jump right in!
As an engineer, you probably know that serverperformance under heavy load is crucial for maintaining the availability and responsiveness of your services. In this post, we'll explore both strategies through a simple simulation in Colab, allowing you to see the impact of changing parameters on system performance.
The network latency between cluster nodes should be around 10 ms or less. – A Dynatrace customer, Head of Performance Engineering. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions.
By Karthik Yagna , Baskar Odayarkoil , and Alex Ellis Pushy is Netflix’s WebSocket server that maintains persistent WebSocket connections with devices running the Netflix application. Finally, the device receives the message, and the action, such as “Show me Stranger Things on Netflix”, is performed.
Dynatrace is a launch partner in support of AWS Lambda Response Streaming , a new capability enabling customers to improve the efficiency and performance of their Lambda functions. Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes.
Validation tasks are then extended left to cover performance testing and release validation in a pre-production environment. More precisely, this team uses AWS Fault Injection Simulator (FIS) to run fault injection to improve the application’s performance and resiliency. The queries are depicted below (sensitive data has been removed).
Reduced tail latencies In both our GRPC and DGS Framework services, GC pauses are a significant source of tail latencies. That’s particularly true of our GRPC clients and servers, where request cancellations due to timeouts interact with reliability features such as retries, hedging and fallbacks.
When the server receives a request for an action (post, like etc.) from a client it performs two parallel operations: i) persisting the action in the data store ii) publish the action in a streaming data store for a pub-sub model. When the server receives a request for an action (post, like etc.) High Level Design. Architecture.
AI model observability plays a crucial role in achieving this by addressing these key aspects: Model performance and reliability: Evaluating the model’s ability to provide accurate and timely responses, ensuring stability, and assessing domain-specific semantic accuracy. Maintained under the Apache 2.0
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
With so many of their transactions occurring online, customers are becoming more demanding, expecting websites and applications to always perform perfectly. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability.
An AI observability strategy—which monitors IT system performance and costs—may help organizations achieve that balance. AI performs frequent data transfers. AI observability is the use of artificial intelligence to capture the performance and cost details generated by various systems in an IT environment.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content