This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is why the Dynatrace Software Intelligence Platform is recognized as a market leader not only for monitoring coverage, but also, very importantly, for providing the shortest time-to-value. OperatingSystems are not always set up in the same way. Recent improvements in OneAgent runtime-data handling. See details below.
According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operativesystems via SLOs and tracking business success.
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. This leads to a more efficient and streamlined experience for users.
Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operatesystems, and develop new functionality.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. You can ask for the best configuration to reduce latency or improve the user experience.”
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
But with the benefits also come concerns about observability, and how to monitor and manage ever-expanding cloud software stacks. As a bonus, operations staff never needs to update operatingsystems or hardware, because AWS manages servers with no stoppage of application functionality. The Amazon Web Services ecosystem.
Caches are very useful software components that all engineers must know. It is a transversal component that applies to all the tech areas and architecture layers such as operatingsystems, data platforms, backend, frontend, and other components.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). One use case for STM is to model the behavior of a customer in the form of a flow of transactions along the buyer’s journey.
To answer these questions for the business as well as work with your mobile developers to prioritize efforts and implement changes, it’s critical to have a single source of truth that provides the operational and business answers you need. When it comes to mobile app development, it’s vital that owners get the full picture.
You can often do this using built-in apps on your operatingsystem. There are also online optimization tools available like Tinify , as well as advanced image editing software like Photoshop or GIMP : Image format is also a key consideration. Its a good idea to resize images to make them physically smaller.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. DNS query time indicates the average response times of DNS requests across the system.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Most teams approach this like traditional software development but quickly discover it’s a fundamentally different beast. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges? Whats worse: Inputs are rarely exactly the same.
Uniting multidisciplinary teams of researchers and educators from 17 universities, IRIS-HEP will receive $5 million a year for five years from the NSF with a focus on producing innovative software and training the next generation of users. SCM slots between DRAM and flash in terms of latency, cost, and density. They're generally right.
Software-defined far memory in warehouse-scale computers Lagar-Cavilla et al., ” This paper describes a “far memory” system that has been in production deployment at Google since 2016. .” ” This paper describes a “far memory” system that has been in production deployment at Google since 2016.
Build evolvable systems. Almost from day one, we knew that the software we were building would not be the software that would be running a year later. We needed to build such an architecture that we could introduce new software components without taking the service down. Expect the unexpected. Automation is key.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency.
This meeting was hosted by the University of Applied Sciences of Upper Austria , RISC Software GmbH , Softwarepark Hagenberg Upper Austria , Dynatrace , and Count It Group. Note: For definitions of language safety and software security and similar terms, see my 2024 essay C++ safety, in context.
Nowadays, the source code to old operatingsystems can also be found online. For everyone familiar with other operatingsystems and their CPU load averages, including this state is at first deeply confusing. **Why?** Here's an example: on an idle 8 CPU system, I launched tar to archive some uncached files.
Customers want to focus on their unique application logic and business needs – not on the undifferentiated heavy lifting of provisioning and scaling servers, keeping software stacks patched and up to date, handling fleet-wide deployments, or dealing with routine monitoring, logging, and web service front ends.
In this article, we will explore what RabbitMQ is, its mechanisms to facilitate message queueing, its role within software architectures, and the tangible benefits it delivers in real-world scenarios. Stepping back, it’s clear how RabbitMQ has become an essential tool in modern software architecture.
Customers have been asking to add file system functionality to our set of solutions as much of their traditional software required a broad accessible shared file system. Amazon EFS file systems can automatically scale from small file systems to petabyte-scale without needing to provision storage or throughput.
The success of our early results with the Dynamo database encouraged us to write Amazon's Dynamo whitepaper and share it at the 2007 ACM Symposium on OperatingSystems Principles (SOSP conference), so that others in the industry could benefit. This was the genesis of the Amazon Dynamo database.
Such solutions also incorporate features like disaster recovery and built-in safeguards that ensure data integrity across diverse operatingsystems. This includes zero-day vulnerabilities and software weaknesses that are not yet known and can be exploited without warning. What is an example of a workload?
Here are five considerations every software architect and developer needs to take into account when setting the architectural foundations for a fast data platform. A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible.
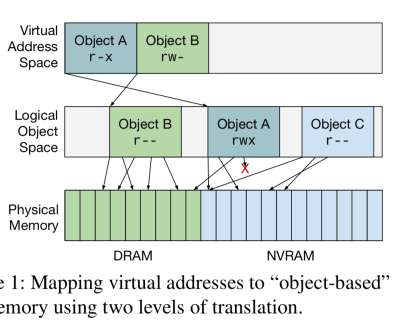
…softwareoperating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
A three-tier system is a software application architecture that consists of a presentation layer, application layer, and data, or core, layer. The benefit of this system is that each tier runs independently from the other tiers, so they can be updated or scaled without impacting the other tiers. Big systems cost big money.
Speedier access to stored information within distributed storage is achieved by leveraging software-defined storage solutions and strategies like sharding or distributing sections of large databases and improving scalability by dividing tasks among many servers.
This is a standalone software program which doesn’t depend on any internet connectivity for its working and its performance is not impacted because of any network related latencies. Any network-related latencies result in performance hindrances in these types of applications.
With the ScaleOut Digital Twin Streaming Service , an Azure-hosted cloud service, ScaleOut Software introduced breakthrough capabilities for streaming analytics using the real-time digital twin concept. This simplifies the installation process and ensures portability across operatingsystems.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operatingsystems are designed, and the way applications operate on data. This means that the overheads of system calls become much more noticeable. in front of that memory , as we saw last week).
Modern software usually involves running tasks that invoke services. Apache Kafka - High-Throughput, Low-Latency, Uses Apache ZooKeeper for Distribution, Written in Scala and Java. If the service is subjected to intermittent heavy loads, it can cause performance or reliability issues.
AWS Developer Relations on how the shift from Robot OperatingSystem (ROS) 1 to ROS 2 will change the landscape for all robot lovers. Join Lee Packham, AWS Solutions Architect and Enrico Huijbers, AWS Software Development Engineer to find out how easy it is.
AWS Developer Relations on how the shift from Robot OperatingSystem (ROS) 1 to ROS 2 will change the landscape for all robot lovers. Join Lee Packham, AWS Solutions Architect and Enrico Huijbers, AWS Software Development Engineer to find out how easy it is.
I don’t need more bandwidth for video conferences or movies, but I would like to be able to download operatingsystem updates and other large items in seconds rather than minutes. There are impressive estimates for latency for 5G, but reality has a tendency to be harsh on such predictions.
Just as today’s systems offer memory protection, they call this time protection. The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. Requirement 4 : State flushing must be padded to its worst-case latency.
This proposal seeks to define a standard for real-time carbon and energy data as time-series data that would be accessed alongside and synchronized with the existing throughput, utilization and latency metrics that are provided for the components and applications in computing environments.
Infrequent failures exercise poorly tested capabilities that tend to amplify problems in unexpected ways rather than mitigate them, so it’s important to carefully exercise the system to ensure that design controls are well tested and operating correctly. This discussion focuses on hardware, software and operational failure modes.
Infrequent failures exercise poorly tested capabilities that tend to amplify problems in unexpected ways rather than mitigate them, so it’s important to carefully exercise the system to ensure that design controls are well tested and operating correctly. This discussion focuses on hardware, software and operational failure modes.
We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Testing Scale-Up Performance.
In this blog post, we will discuss the best practices on the MongoDB ecosystem applied at the OperatingSystem (OS) and MongoDB levels. OperatingSystem (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content