This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. We formulate the problem as a Mixed Integer Program (MIP). can we actually make this work in practice?
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. As a bonus, operations staff never needs to update operatingsystems or hardware, because AWS manages servers with no stoppage of application functionality. AWS continues to improve how it handles latency issues.
Remember that these are calls to the operatingsystem – kernel calls. I also don’t know why right-clicking on other programs’ icons on the task bar is also a bit slow – it’s apparently a different issue, or an odd design decision. That is an average read of 68 bytes each time. Think about that for a moment.
Because of that big servers and other memory systems need to have another kind of memory in the hierarchy. SCM slots between DRAM and flash in terms of latency, cost, and density. IBM still dominates mainframes and Microsoft still dominates PC operatingsystems and productivity software. They're generally right.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Relatedly, P1494R4 Partial program correctness by Davis Herring adds the idea of observable checkpoints that limit the ability of undefined behavior to perform time-travel optimizations. Note: This is the second time contracts has been voted into draft standard C++. It was briefly part of draft C++20, but was then removed for further work.
AWS handles all the administration of the underlying compute resources, including server and operatingsystem maintenance, capacity provisioning and automatic scaling, code and security patch deployment, and code monitoring and logging. You can go from code to service in three clicks and then let AWS Lambda take care of the rest.
Nowadays, the source code to old operatingsystems can also be found online. For everyone familiar with other operatingsystems and their CPU load averages, including this state is at first deeply confusing. **Why?** 90491 N|rnberg (Germany) Consulting+Networking+Programming+etc'ing 42.
With a few clicks in the AWS Management Console, customers can use Amazon EFS to create file systems that are accessible to EC2 instances and that support standard operatingsystem APIs and file system semantics. Synchronous events operate with low latency so you can deliver dynamic, interactive experiences to your users.
Such solutions also incorporate features like disaster recovery and built-in safeguards that ensure data integrity across diverse operatingsystems. Computer workload refers to the combination of computing power, memory, storage, and network resources required to complete a task or run a program.
Desktop Application – Desktop application is a name coined for a general program used to run on a personal computer or laptop. This is a standalone software program which doesn’t depend on any internet connectivity for its working and its performance is not impacted because of any network related latencies.
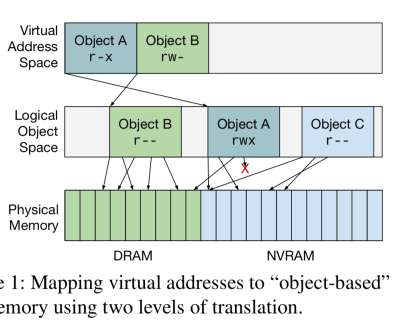
Drawing inspiration from work on single-address-space (SAS) operatingsystems a single system-wide mapping is maintained by the OS which all devices use for accessing memory. It’s the job of the operatingsystem to manage the global and logical object space abstractions. A prototype implementation.
The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. The top line shows the change in tail latency across a set of monolithic applications as operating frequency decreases. Hardware implications.
In such a situation I’d expect to see unusually high latencies, but normal throughput). I was only partially right (there is a steady-state queue involved)… Plus, although it’s not described, the performance degradation observed in this case would almost certainly be poor latency and poor throughput. Hence convoys will occur.
RabbitMQ’s compatibility with various programming languages makes it versatile for developers, who can select the language that perfectly aligns with their project requirements. Nevertheless, RabbitMQ prioritizes system stability and may halt incoming messages from producers should available disk space drop below a critical threshold.
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. The low-level streaming implementations of the mentioned engines require specialized knowledge in order to program new applications.
On the last morning of the conference Daniel Bittman presented some of the work being done in the context of the Twizzler OS project to explore new programming models for NVM. The starting point is a set of three asumptions for an NVM-based programming model: Compared to traditional persistent media, NVM is fast.
With the rapid advancements in web application technologies, programming languages, cloud computing services, microservices, hybrid environments, etc., monitoring distributed systems becomes much more difficult to carry out and manage. This also includes latency, or the time it takes for data or a request to get through a network.
To me this positions Fugaku as the first of a new mainstream, rather than a special purpose system. I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available.
When running a single user thread, you will often get the advertised single-core Turbo frequency, but if the operatingsystem enables more cores to handle (even very short-lived) background processes, your frequency may drop unexpectedly. RDTSCP can still be executed later than expected, but not earlier.
When running a single user thread, you will often get the advertised single-core Turbo frequency, but if the operatingsystem enables more cores to handle (even very short-lived) background processes, your frequency may drop unexpectedly. RDTSCP can still be executed later than expected, but not earlier.
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. SQL Server always checks I/O completion status for any operatingsystem error conditions and proper data transfer size and then handles errors appropriately. The data transfer size is not valid.
Subsystem / Path The I/O subsystem or path includes those components that are used to support an I/O operation. SQL Server copy-on-write actions are used to maintain snapshot databases in SQL Server 2005.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content