This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In modern containerized environments, teams often deploy Kubernetes across mixed operatingsystems, creating a situation where both Linux and Windows nodes reside in the same cluster. This inconsistency leads to gaps in monitoring and alerting, making it difficult to maintain a unified view of the cluster’s health.
OperatingSystems are not always set up in the same way. Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Another consequence of the recent discontinuation of support for 32-bit operatingsystems is the new default location of OneAgent for Windows.
The optimization goal was to improve the application efficiency, that is to improve the ratio between service throughput and cloud costs while not increasing the application latency (e.g. JVM, databases, middleware, operatingsystem, cloud instances, etc) by also taking advantage of Dynatrace full-stack observability.
User demographics , such as app version, operatingsystem, location, and device type, can help tailor an app to better meet users’ needs and preferences. By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operativesystems via SLOs and tracking business success. Performance typically addresses response times or latency aspects and contributes to the four golden signals.
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. This leads to a more efficient and streamlined experience for users.
This means that Dynatrace continues full operation when a majority of nodes are up and a maximum of two nodes are down at a time. The network latency between cluster nodes should be around 10 ms or less. Additionally, a Linux operatingsystem with support for cgroups and systemd (for example, RHEL/CentOS 7+), is required.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operatesystems, and develop new functionality.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. You can ask for the best configuration to reduce latency or improve the user experience.” It’s not just a cost-reduction tool.
As a bonus, operations staff never needs to update operatingsystems or hardware, because AWS manages servers with no stoppage of application functionality. AWS continues to improve how it handles latency issues. One factor that dissuades many from using Lambda is the need to restart containers.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
It is a transversal component that applies to all the tech areas and architecture layers such as operatingsystems, data platforms, backend, frontend, and other components. Caches are very useful software components that all engineers must know.
For example, teams can further segment the telemetry data captured from a mobile app based on operatingsystem, device, region, app version, and other custom metrics, to provide more granular insights on users and their behavior. When it comes to mobile app development, it’s vital that owners get the full picture.
Remember that these are calls to the operatingsystem – kernel calls. With a bit of column rearranging we get this impressive result: What this says is that, over the course of two right-mouse clicks, RuntimeBroker.exe , thread 10,252, issued 229,604 ReadFile calls, reading a total of 15,686,586 bytes. Think about that for a moment.
You can often do this using built-in apps on your operatingsystem. This means that you can reduce latency and speed up your content delivery times , regardless of where your customers are based. You can free up space and reduce the load on your server by compressing and optimizing images.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). One use case for STM is to model the behavior of a customer in the form of a flow of transactions along the buyer’s journey.
We’d like to get deeper insight into the host, the underlying operatingsystem, and any third-party services used by our application. Tracking CPU usage helps identify performance bottlenecks, optimize resource utilization, plan for scalability, detect performance degradation, and monitor overall system health.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. Compaction operation defragments data files & indexes. However, keep in ming that it does not release space to the operatingsystem. The compact process releases the free space to the operatingsystem.
In the back to basics readings this week I am re-reading a paper from 1995 about the work that I did together with Thorsten on solving the problem of end-to-end low-latency communication on high-speed networks. The lack of low-latency made that distributed systems (e.g.
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., This post is about a secondary performance characteristic — sustained memory bandwidth for a single thread running on a single core.
Failures are a given and everything will eventually fail over time: from routers to hard disks, from operatingsystems to memory units corrupting TCP packets, from transient errors to permanent failures. This lowered latency more than 2x and delivered more than 10x improvement in latency variability on the network.
AWS handles all the administration of the underlying compute resources, including server and operatingsystem maintenance, capacity provisioning and automatic scaling, code and security patch deployment, and code monitoring and logging. You can go from code to service in three clicks and then let AWS Lambda take care of the rest.
how well the system fetched relevant documents, measured with metrics like precision and recall), semantic similarity of response, cost, and latency, in addition to performing heuristics checks, such as length constraints, hedging versus overconfidence, and hallucination detection. We tested both retrieval quality (e.g.,
The success of our early results with the Dynamo database encouraged us to write Amazon's Dynamo whitepaper and share it at the 2007 ACM Symposium on OperatingSystems Principles (SOSP conference), so that others in the industry could benefit. This was the genesis of the Amazon Dynamo database.
With a few clicks in the AWS Management Console, customers can use Amazon EFS to create file systems that are accessible to EC2 instances and that support standard operatingsystem APIs and file system semantics. Synchronous events operate with low latency so you can deliver dynamic, interactive experiences to your users.
Such solutions also incorporate features like disaster recovery and built-in safeguards that ensure data integrity across diverse operatingsystems. Utilizing cloud platforms is especially useful in areas like machine learning and artificial intelligence research.
Let alone browsers, the website may get into trouble for different resolutions, different operatingsystems and different browser versions too!! Cross-browser testing deals with all those things by running the websites on different browsers, their versions, operatingsystems and on different resolutions.
Given that allocation is a costly operation in most operatingsystems, this becomes important in performance-critical environments. This can create variable latency during iteration.
If throttling is applied at the operatingsystem level , then the metrics match what a real user with those network conditions would experience. INP is a measure of the latency for all interactions on a given page, where the highest latency — or close to it — informs the final score.
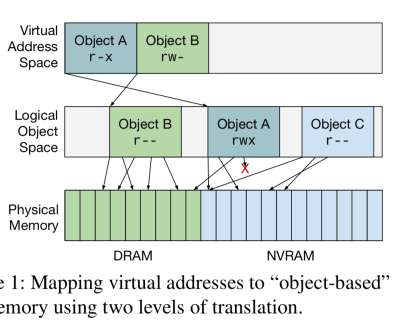
Drawing inspiration from work on single-address-space (SAS) operatingsystems a single system-wide mapping is maintained by the OS which all devices use for accessing memory. It’s the job of the operatingsystem to manage the global and logical object space abstractions. A prototype implementation.
This is a standalone software program which doesn’t depend on any internet connectivity for its working and its performance is not impacted because of any network related latencies. Any network-related latencies result in performance hindrances in these types of applications.
While ensuring that messages are durable brings several advantages, it’s important to note that it doesn’t significantly degrade performance regarding throughput or latency. Nevertheless, RabbitMQ prioritizes system stability and may halt incoming messages from producers should available disk space drop below a critical threshold.
In such a situation I’d expect to see unusually high latencies, but normal throughput). I was only partially right (there is a steady-state queue involved)… Plus, although it’s not described, the performance degradation observed in this case would almost certainly be poor latency and poor throughput. Hence convoys will occur.
By implementing data replication strategies, distributed storage systems achieve greater. Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions.
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. When we work on a single machine, the operatingsystem takes care of managing the resources allocated to applications.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
To me this positions Fugaku as the first of a new mainstream, rather than a special purpose system. I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available.
This boils down to a single digit µs latency toleration in the tail for far memory, and in addition to security and privacy concerns, rules out remote memory solutions. Thus we’re fundamentally trading (de)-compression latency at access time for the ability to pack more data in memory.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content