This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. We then collect and analyze the performance of the two clusters.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Storage and network transfer of files is a measurable cost. For example: All subfolders of the /opt directory are mounted as local, low latency, high-throughput drives, with relatively low storage capacity.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. No more network-based EBS, just blazing-fast local SSD. MySQL on AWS Performance Test. Amazon RDS.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. The desire for CPU efficiency and lower latencies is easy to understand. SOSP’19. Emphasis mine). It reminds me of ZeroMQ.
Uploading and downloading data always come with a penalty, namely latency. It is worth pointing out that cloud processing is always subject to variable network conditions. Doing so has the added advantage of being able to design and tune the enhancement to suit the requirements of packager and our other encoding applications.
With DEM solutions, organizations can operate over on-premise network infrastructure or private or public cloud SaaS or IaaS offerings. STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables).
Additionally, we’ve added the Philadelphia AWS Local Zone , helping to reduce latency for customers operating in the eastern U.S. This enables ScaleGrid users in Australia and nearby regions to access lower-latency services and improved performance. Stay tuned for more exciting updates in the months to come! <p>The
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. Our engineering teams tuned their services for performance after factoring in increased resource utilization due to tracing.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. This article provides the top 10 tips for performance tuning for real-world workloads when running Spark on Alluxio with data locality, giving the most bang for the buck. The first few tips are related to locality.
This allows us to quickly tell whether the network link may be saturated or the processor is running at its limit. This allows us to quickly tell whether the network link may be saturated or the processor is running at its limit. DNS query time indicates the average response times of DNS requests across the system.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Stay tuned for updates in Q1 2020. Dynatrace news. You can also create custom charts.
This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns. This network connection heterogeneity made choosing a single delivery model difficult. This approach enables the computing power to catch up quickly when the queues grow.
When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN. Fault Tolerance If the underlying KafkaConsumer crashes due to ephemeral system or network events, it should be automatically restarted. million elements.
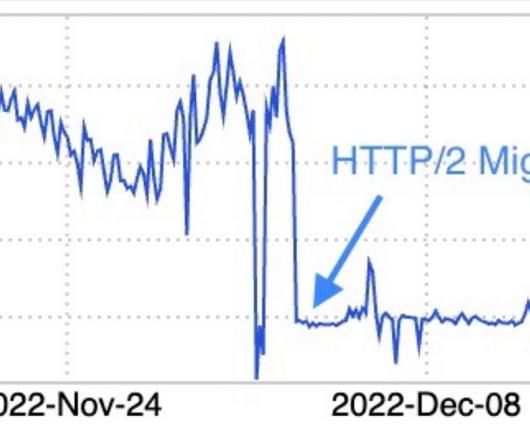
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
In PostgreSQL, replication lag can occur due to various reasons such as networklatency, slow disk I/O, long-running transactions, etc. Replication lag can occur due to various reasons, such as: Networklatency: Networklatency is the delay caused by the time it takes for data to travel between the primary and standby databases.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Stay tuned for updates in Q1 2020. Dynatrace news. You can also create custom charts.
These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Orient: Gather tuning parameters for a particular table that changed. AutoAnalyze In short, AutoAnalyze finds the best tuning/configuration parameters for a table. More processing resources.
Failure can occur due to a myriad of reasons: misbehaving clients that trigger a retry storm, an under-scaled service in the backend, a bad deployment, a network blip, or issues with the cloud provider. Those two metrics are approximate indicators of failures and latency. Let’s dig into how we accomplished this.
This article will cover many areas that database administrators need to be aware of in order to properly license, recover, and tune a Reporting Services installation. Tuning Options. Tuning SSRS is much like any other application. Disk latency for ReportServer and ReportServerTempDB are very important. General Tuning.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. Similarly, an increased throughput signifies an intensive workload on a server and a larger latency.
The POP is strategially located within the country and lowers latency overall. KeyCDN is always on the lookout for ways to minimize latency and accelerate asset delivery worldwide. For more POPs planned, check our current network for a list of both active and planned edge server locations. Hola Mexico!
Each ran with the following specs: 8GB RAM 2 vCPU 120GB SSD Configuration Details : Each PostgreSQL instance for Scalegrid and Amazon RDS was set up with default tuning parameters for PostgreSQL versions 13, 14, and 15. NetworkLatency : We ran both machines in the same region and conducted the tests from within the same box in that region.
The software also extends capabilities allowing fine-tuning consumption parameters through QoS (Quality of Service) prefetch limits catered toward balancing load among numerous consumers, thus preventing overwhelming any single consumer entity. Take Softonic’s platform as an example.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. Stay tuned for more in 2022! Ilya Grigorik. 2021-11-08T14:30:00+00:00. 2021-11-08T19:34:34+00:00.
Unfortunately, this means that the age-old Telco bugbears will rear their ugly heads again, including latency. 5G, as a fundamental requirement, mandates a 1 millisecond latency from the datasource to its destination. This requires 1 ms networklatency. These have to communicate with each other.
Unfortunately, this means that the age-old Telco bugbears will rear their ugly heads again, including latency. 5G, as a fundamental requirement, mandates a 1 millisecond latency from the datasource to its destination. This requires 1 ms networklatency. These have to communicate with each other.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. and lower), this typically takes two network round trips.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
After this, there is often a long process of training that includes tuning the knobs and levers, called hyperparameters, that control the different aspects of the training algorithm. Built-in model tuning (hyperparameter optimization) that can automatically adjust hundreds of different combinations of algorithm parameters.
eBPF was created by Alexei Starovoitov while at PLUMgrid (he's now at Facebook) as a generic in-kernel virtual machine, with software defined networks as the primary use case. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O. eBPF does more.
Next, we’ll look at how to set up servers and clients (that’s the hard part unless you’re using a content delivery network (CDN)). Using just a few (but still more than one), however, could nicely balance congestion growth with better performance, especially on high-speed networks. Servers and Networks. What Does It All Mean?
Compression achieved is relevant because the higher the compression, the smaller the file size, and the lower the data required to transfer the image on the network. Tip: When evaluating quality, compression and fine-tuning of modern formats, Squoosh.app ’s ability to perform a visual side-by-side comparison is helpful.
Making queries to an inference engine has many of the same throughput, latency, and cost considerations as making queries to a datastore, and more and more applications are coming to depend on such queries. The following figure highlights how just one of these variables, batch size, impacts throughput and latency on ResNet50.
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. I've refuted many benchmarks by showing that they would require a network throughput that would far exceed the maximum network bandwidth (off by, for example, as much as 10x!).
They can also bolster uptime and limit latency issues or potential downtimes. Consistently evaluating and tuning resource allocations based on use patterns helps prevent overprovisioning and reduces unnecessary expenses.
The data shape will dictate capacity planning, tuning of the backbone, and scalability analysis for individual components. A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. At least once? At most once?
Today we’re excited to announce that we’ve launched yet another POP location to help further supercharge our network’s content delivery speeds. The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. What’s Next?
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. I've refuted many benchmarks by showing that they would require a network throughput that would far exceed the maximum network bandwidth (off by, for example, as much as 10x!).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content