This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS has a number of features, including: Stream objects ?— ?
User Feed Service, Media Counter Service) read the actions from the streaming data store and performs their specific tasks. media search index, locations search index, and so forth) in future. After that, the post gets added to the feed of all the followers in the columnar data storage. After that, the various services (e.g.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
by Varun Sekhri , Meenakshi Jindal , Burak Bacioglu Introduction At Netflix, to promote and recommend the content to users in the best possible way there are many Media Algorithm teams which work hand in hand with content creators and editors. But we cannot search or present low latency retrievals from files Etc.
And an O’Reilly Media survey indicated that two-thirds of survey respondents have already adopted generative AI —a form of AI that uses training data to create text, images, code, or other types of content that reflect its users’ natural language queries. AI requires more compute and storage. AI performs frequent data transfers.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. For instance, envision a response payload that delivers media streams for a playback session.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc. Related Articles.
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces.
This system is responsible for processing incoming media files, such as video, audio and subtitles, and making them playable on the streaming service. Cosmos is a computing platform for workflow-driven, media-centric microservices. This enables us to use our scale to increase throughput and reduce latencies.
You may also know that this has led to an increase in the demand for efficient and secure data storage solutions that won’t break the bank. By processing data at the edge of the network, latency can be minimized, which means that data can be processed and analyzed faster.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). One use case for STM is to model the behavior of a customer in the form of a flow of transactions along the buyer’s journey.
We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases. The watermarking functionality, at the start, was a simple offering with various Google Drive integrations for storage and links.
Today, we are releasing a plugin that allows customers to use the Titan graph engine with Amazon DynamoDB as the backend storage layer. It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage. The importance of relationships.
However, then the style will not be present when referencing the image directly (such as the image shared in social media via the <meta property="og:image" content="{image-url}"> tag), making the image devoid of personality. The images embedded in social media when sharing our content are of particular interest.
Other industries using Amazon EC2 for HPC-style workloads include pharmaceuticals, oil exploration, industrial and automotive design, media and entertainment, and more. When instances are placed in a cluster they have access to low latency, non-blocking 10 Gbps networking when communicating the other instances in the cluster.
webcam access via getUserMedia() or the Media Session API ) may attend deceptively small expansions in exposed API surface. Chrome has missed several APIs for 3+ years: Storage Access API. Audio Worklets are a fundamental enabler for rich media and games on the web. Media Recorder. Media Source API (a.k.a. "MSE").
Spot Instances are ideal for use cases like web and data crawling, financial analysis, grid computing, media transcoding, scientific research, and batch processing. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway. At werner.ly Syndication. Subscribe to this weblogs. or rss feed.
In an in-depth article on Streaming Media Dan Rayburn analyzed the impact of Amazon Cloudfront move to GA: Amazons CDN Gets More Competitive, Adds SLA, New Edge Locations, Lower Pricing. Understanding Throughput-Oriented Architectures - background article in CACM on massively parallel and throughput vs latency oriented architectures.
The starting point is a set of three asumptions for an NVM-based programming model: Compared to traditional persistent media, NVM is fast. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. in front of that memory , as we saw last week).
These nodes and edges require a good amount of compute and storage which is typically distributed across a large number servers either running in the cloud or your own data center. Every time data spikes - a phenomenon which will be not predictable in most cases - overall latency to process the data using data pipeline will go up.
Optimize media content for quality and/or bandwidth. Each of these categories opens up challenging problems in AI/visual algorithms, high-density computing, bandwidth/latency, distributed systems. Generate interactive and immersive content. Orchestrate the processing flow across an end-to-end infrastructure.
media="(min-width: 990px)"> <source srcset="img@tablet.png, img@tablet-2x.png 2x". media="(min-width: 750px)"> <img srcset="img@mobile.png, img@mobile-2x.png 2x". It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). alt="I don't know why.
Briefly, WAL requires that all the transaction log records associated with a particular data page be flushed to stable media before the data page itself can be flushed to stable media. Stable Media Stable media is often confused with physical storage.
Here, native apps are doing work related to their core function; storage and tracking of user data are squarely within the four corners of the app's natural responsibilities. Many have adroitly covered the perspective and ethical distortions within social media firms caused by the relentless pursuit of "north star" metrics.
The solution for this specific problem is that the user should optimize media by reducing the size of the images without lowering their quality. Cached Mode (Repeat Visit): The user access the website for the second time, emulating a second visit from the user’s perspective, which includes all the files now cached in a local storage.
The solution for this specific problem is that the user should optimize media by reducing the size of the images without lowering their quality. Cached Mode (Repeat Visit): The user access the website for the second time, emulating a second visit from the user’s perspective, which includes all the files now cached in a local storage.
Assuming you want to load a social media layout, you might add a loading spinner or a skeleton loader to ensure that you don’t load an incomplete site. Caching partially stores your data and is not used as permanent storage. Using the cache as permanent storage is an anti-pattern. But isn’t waiting for the data the point?
Read Retry When a read from stable media returns an error, the read operation is tried again. Streams NTFS volumes enable data files to have one or more secondary storage streams.
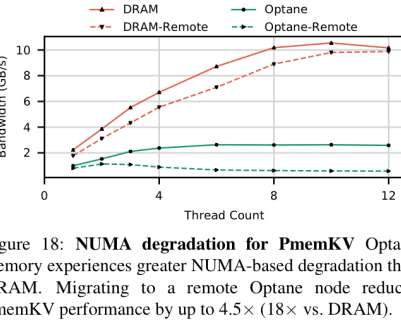
higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The physical media is accessed in chunks of 256 bytes (an XPLine). The read latency for Optane is 2x-3x higher than DRAM.
Using CDN for the whole website, you can offload most of the website traffic to your CDN which will handle not only large traffic spikes but also reduce the latency of content delivery. Alternatively, you can upload output directory to cloud object/blob storage such as Amazon S3 or Azure Blob Storage and serve your site from there.
Assets Optimizations Brotli, AVIF, WebP, responsive images, AV1, adaptive media loding, video compression, web fonts, Google fonts. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Do we use adaptive media loading and client hints? Large preview ).
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Consider Swapping Images with the Sizes Attribute by specifying different image display dimensions depending on media queries, e.g. to manipulate sizes to swap sources in a magnifier component. AV1 has compression similar to H.265
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content