This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency.
User Feed Service, Media Counter Service) read the actions from the streaming data store and performs their specific tasks. media search index, locations search index, and so forth) in future. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable. debian packages).
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. It provides a good read on the availability and latency ranges under different production conditions.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
And an O’Reilly Media survey indicated that two-thirds of survey respondents have already adopted generative AI —a form of AI that uses training data to create text, images, code, or other types of content that reflect its users’ natural language queries. Use containerization.
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. This system is responsible for processing incoming media files, such as video, audio and subtitles, and making them playable on the streaming service. We call this system Cosmos.
We needed to serve our growing base of startup, government, and enterprise customers across many vertical industries, including automotive, financial services, media and entertainment, high technology, education, and energy. The company decided it wanted the scalability, flexibility, and cost benefits of working in the cloud.
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces.
We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases. We wanted a scalable service that was near real-time, 2. New feature requests were adding to the maintenance burden for the team.
To meet user-defined goals for performance (request latency) and cost, the monitoring service tracks and adjusts resources to workload changes. First, we deployed the storage engine across multiple storage media — currently RAM and flash disk. Our monitoring engine automatically moves data between tiers based on access patterns.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. This enables customers to serve content to their end users with low latency, giving them the best application experience.
Social media apps navigate relationships between friends, photos, videos, pages, and followers. When using relational databases, traversing relationships requires expensive table JOIN operations, causing significantly increased latency as table size and query complexity grow. Enter graph databases. Graph databases at Amazon.
Werner Vogels weblog on building scalable and robust distributed systems. The Amazon Simple Queue Service (SQS) is a highly scalable, reliable and elastic queuing service that just works. Simple Queue Service (SQS) is very useful, easy to use, scalable and reliable. Amazon SQS provides highly scalable â??eventual
Werner Vogels weblog on building scalable and robust distributed systems. Other industries using Amazon EC2 for HPC-style workloads include pharmaceuticals, oil exploration, industrial and automotive design, media and entertainment, and more. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications.
Redis's microsecond latency has made it a de facto choice for caching. Four years ago, as part of our AWS fast data journey, we introduced Amazon ElastiCache for Redis , a fully managed, in-memory data store that operates at microsecond latency. TB of in-memory capacity in a single cluster.
The file size of your images of course is very important, but SEO and social media also play an important part in helping your website perform and convert better. How to optimize images for social media for better engagement and CTR. SVG Scalable Vector Graphics (SVG) allows vector graphics to be displayed in the browser.
Werner Vogels weblog on building scalable and robust distributed systems. Spot Instances are ideal for use cases like web and data crawling, financial analysis, grid computing, media transcoding, scientific research, and batch processing. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications.
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
Werner Vogels weblog on building scalable and robust distributed systems. In an in-depth article on Streaming Media Dan Rayburn analyzed the impact of Amazon Cloudfront move to GA: Amazons CDN Gets More Competitive, Adds SLA, New Edge Locations, Lower Pricing. All Things Distributed. By Werner Vogels on 19 November 2010 07:51 AM.
An organization’s response to an incident, whether we are talking about downtime, security breaches or cyber-attacks, or even prolonged latency and repeated errors, is critical to the continued success of the business and trust from the customer or end user. SREs must manage complex distributed systems. Incident Logging.
Static content represents fixed web elements like HTML, CSS, JavaScript files, images, and media assets. Caching improves performance, reduces bandwidth usage, and enhances scalability by reducing the load on the origin server.Faster Loading Times: Static content is pre-generated and does not require server-side processing.
So this November Shahin and I went to SC22 in Dallas TX together, as analysts, and started out in the media briefing event where the latest Top500 Report was revealed and discussed. Many HPC workloads synchronize work on a barrier, and work much better if there’s a consistently narrow latency distribution without a long tail.
You need to watch out for complex design elements, large media files, or slow browser rendering can delay the time it takes for the largest contentful element to render. We realized that we needed to consider a more global and scalable solution to better serve our global audience. This determines how long a page remains “fresh.”
Throughout the web’s history, static websites have always been a popular option due to their simplicity, scalability, and security. Hosted repositories also have an upper limit of ~2GB, so you may need to use a 3rd party service for media if you have many assets. Updating a blog post with the visual editor in CloudCannon.
Static content represents fixed web elements like HTML, CSS, JavaScript files, images, and media assets. Caching improves performance, reduces bandwidth usage, and enhances scalability by reducing the load on the origin server.Faster Loading Times: Static content is pre-generated and does not require server-side processing.
Using an image CDN, such as KeyCDN, can significantly reduce the latency of your image delivery. Developers often focus on improving scripting performance, but they need to realize that the bulk of their performance woes come from media content… - Una Kravets Image optimization.
Because our perceptions of what AI would be were heavily shaped by the media before any real AI existed. So if you’re in this boat with your applications, be sure to: Understand the needs of your audience as far as latency. Why mention this in a tech blog about AI in 2024?
By Meenakshi Jindal Overview At Netflix, we built the asset management platform (AMP) as a centralized service to organize, store and discover the digital media assets created during the movie production. Backend processing may take time from seconds to minutes.
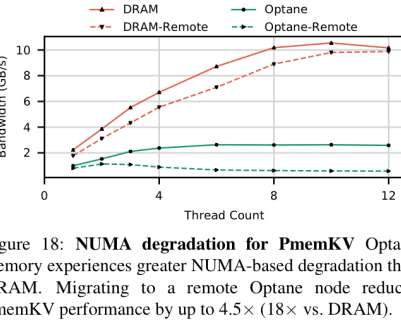
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM.
They understood that most websites lack tight latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. " [ an intro to "isomorphic javascript", a.k.a. "Server-Side "Server-Side Rendering", a.k.a. "SSR"
Assuming you want to load a social media layout, you might add a loading spinner or a skeleton loader to ensure that you don’t load an incomplete site. However, some caveats regarding performance, scalability, and potential data conflicts exist. But isn’t waiting for the data the point? Well, yes, but you can load it faster.
Read Retry When a read from stable media returns an error, the read operation is tried again. Under certain conditions, issuing the same read returns the correct data.
Using CDN for the whole website, you can offload most of the website traffic to your CDN which will handle not only large traffic spikes but also reduce the latency of content delivery. Using JAMstack delivers better performance, higher scalability with less cost, and overall a better developer experience as well as user experience.
Assets Optimizations Brotli, AVIF, WebP, responsive images, AV1, adaptive media loding, video compression, web fonts, Google fonts. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. From: High Performance Browser Networking by Ilya Grigorik. Large preview ).
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content