This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Little’s Law and Why Latency Matters. In many cases, the assumption is that as long as throughput is high enough, the latency won’t be a problem. However, latency is often a key factor in why the throughput isn’t high enough. This is the first time I have benchmarked it with a realistic example.
A common query from users revolves around the precise measurement of latency in APISIX. When utilizing APISIX, how should one address unusually high latency? In reality, discussions on latency measurement are centered around the performance and response time of API requests.
Scalability and low latency are crucial for any application that relies on real-time data. In this post, we'll discuss how you can use YugabyteDB and its read replica nodes to improve the read latency for users across the globe. One way to achieve this is by storing data closer to the users.
There may be a scenario when you want to test an application when the network is slow(we also call it high network latency). Or you are reproducing a customer scenario(having high network latency) where some anomalous behavior is observed. In the Chrome browser, we can easily Simulate a slower network connection.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. The example below is for a 2005-era processor with 60 ns memory latency and 6.4 cache lines -> 5.6 cache lines -> 5.6
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This local SaaS presence minimizes latency and maximizes the speed and reliability of data access. By keeping data within the region, Dynatrace ensures compliance with data privacy regulations and offers peace of mind to its customers.
This versatility provides a cost-effective solution to reduce global network latency by bringing the database closer to the end user. PolyScale operates a global network of PoPs (Points of Presence). Think of PoPs as regional database connections.
Efficient database operations in middleware can dramatically improve overall system performance, reduce latency, and enhance user experience. This is crucial because middleware often serves as the bridge between client applications and backend databases, handling a high volume of requests and data processing tasks.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
Histogram showing the distribution of failed payments, split by credit card provider The use cases and underlying metrics analyzed via histograms are extremely broad: Latency distribution : Histograms can show the distribution of request latencies, helping you understand how many requests fall into different latency buckets.
In the fast-paced digital world, where every millisecond counts, understanding the nuances of network latency becomes paramount for developers and system architects. Latency, the delay before a transfer of data begins following an instruction for its transfer, can significantly impact user experience and system performance.
This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward. That means every query may have to shoot multiple requests to different nodes, aggregate the results back at the coordinating node, and return the result.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
In this article, I will walk through a comprehensive end-to-end architecture for efficient multimodal data processing while striking a balance in scalability, latency, and accuracy by leveraging GPU-accelerated pipelines, advanced neural networks , and hybrid storage platforms.
Welcome back to this series all about file uploads for the web. In the previous posts, we covered things we had to do to upload files on the front end, things we had to do on the back end, and optimizing costs by moving file uploads to object storage.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
Does it affect latency? Yes, you can see an increase in latency. So, if you’re hosting your application in AWS or Azure and move your database to DigitalOcean, you will see an increase in latency. However, the average latencies between AWS US-East and the DigitalOcean New York datacenter locations are typically only 17.4
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. million impression events globally every second, with each event approximately 1.2KB in size.
Continuous Instrumentation of the Linux Scheduler To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. Now that we’ve compared throughput performance, let’s take a look at ScaleGrid vs. DigitalOcean latency for MySQL. Read-Intensive Latency Benchmark. Balanced Workload Latency Benchmark.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation. Latency is the time that it takes a request to be served. Define SLOs for each service. Reliability.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. Citrix latency represents the end-to-end “screen lag” experienced by a server’s users. Tie latency issues to host and virtualization infrastructure network quality. ICA latency. Citrix VDA.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
High latency or lack of responses. You receive an alert message from Dynatrace (your infrastructure observability hub) letting you know that the average response latency of all deployed APIs has tripled. This increase is clearly correlated with the increased response latencies. Soaring number of active connections.
Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency. Spark Structured Streaming can also provide consistent fault recovery for applications where latency is not a critical requirement.
Putting an external cache in front of the database is commonly used to compensate for subpar latency stemming from various factors, such as inefficient database internals, driver usage, infrastructure choices, traffic spikes, and so on. This is a clear performance-oriented decision.
While clustering across wide-area networks (WANs) is discouraged due to latency issues, leased links can mitigate some connectivity challenges. Keeping queues short minimizes latency and enhances the overall efficiency of message delivery in RabbitMQ. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. Logging is selective to cases where the old and new responses do not match.
The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. The reason is because mobile networks are, as a rule, high latency connections. Last mile latency deals with the disproportionate complexity toward the terminus of a connection.
CPU isolation and efficient system management are critical for any application which requires low-latency and high-performance computing. In modern production environments, there are numerous hardware and software hooks that can be adjusted to improve latency and throughput.
Sydney, we have a disk write latency problem! It was on August 25 th at 14:00 when Davis initially alerted on a disk write latency issues to Elastic File System (EFS) on one of our EC2 instances in AWS’s Sydney Data Center. The problem didn’t last long or have any impact on our services.
We want to make scale, availability and low latency access to data as easy as possible for everyone, and it’s all about where your data lives. CockroachDB was built to address these challenges and we’ve recently simplified a multi-region deployment of a consistent database down to a few simple, declarative SQL statements applied as DML.
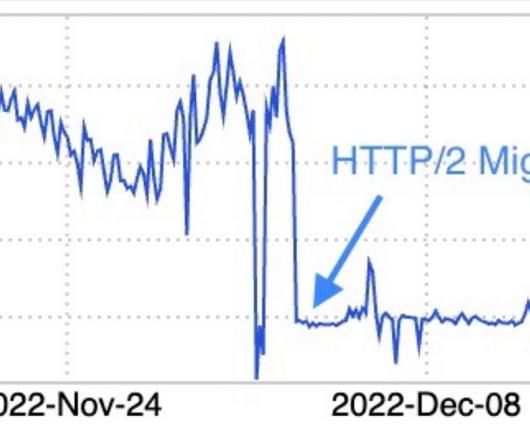
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience. Below is a sample SRG dashboard for these signals: LatencyLatency refers to the amount of time that data takes to transfer from one point to another within a system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content