This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
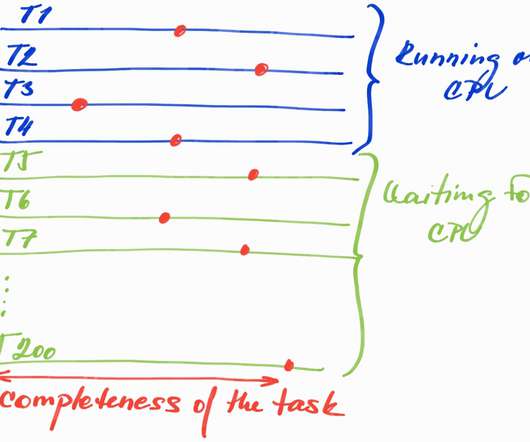
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. Each section will be illustrated with relevant Java code samples to provide practical insights.
To achieve this, we often need to make changes in the settings of created network sockets and default settings of Linux kernel, monitor the usage of the TCP Send/Receive Buffers and Queues and, in particular, adjust our application to be a good candidate for solving this problem.
This decoupling simplifies system architecture and supports scalability in distributed environments. RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Kafka achieves scalability by distributing topics across multiple partitions and replicating them among brokers.
Although these COBOL applications operate with consistent performance, companies and governments are forced to transform them to new platforms and rewrite them in modern programming languages (like Java) for several reasons. Thus, implementing applications in Java can result in considerable financial savings.
A cornerstone of Dynatrace monitoring capabilities, OneAgent boosts your log ingestion experience by automatically detecting and tagging logs based on the detected process technologyeven for custom-developed applications. Ready to consolidate your logs and monitoring tools in Dynatrace? Configuration is fully customizable.
that offers security, scalability, and simplicity of use. already address SNMP, WMI, SQL databases, and Prometheus technologies, serving the monitoring needs of hundreds of Dynatrace customers. JMX monitoring extensions are currently being migrated. Extensions can monitor virtually any type of technology in your environment.
Implement proactive monitoring for each of these endpoints. Key Features Proactive monitoring through scheduled collectors jobs Our Title Health microservice runs a scheduled collector job every 30 minutes for most of our personalization stack. Track real-time title impressions from the NetflixUI. there is a dedicated collector.
As a result of persistent queues, a system benefits from improved performance, reliability, and scalability. TIBCO Enterprise Message Service features compatibility with software written in Java. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data. Watch webinar now!
As a result of persistent queues, a system benefits from improved performance, reliability, and scalability. TIBCO Enterprise Message Service features compatibility with software written in Java. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data.
We’ve worked closely with our partner AWS to deliver a complete, end-to-end picture of your cloud environment that includes monitoring support for all AWS services. Dynatrace can monitor AWS Lambda functions automatically, just like any other service. With these steps complete, your Lambda functions are now fully monitored.
Dynatrace is redefining Application Security, applying the automation, AI, scalability, and enterprise-grade robustness of its platform to change the way security gets done. Dynatrace entered the Application Security market with automatic and continuous protection for Java workloads. Vulnerabilities in Node.js Next steps.
This created problems with both visibility and scalability. The company’s goal was to standardize observability and prevent common problems, such as Java or pods running out of memory, or users requesting resources and barely using any, or using 100% of it. Platform engineering looks to bring in a unified toolset.”
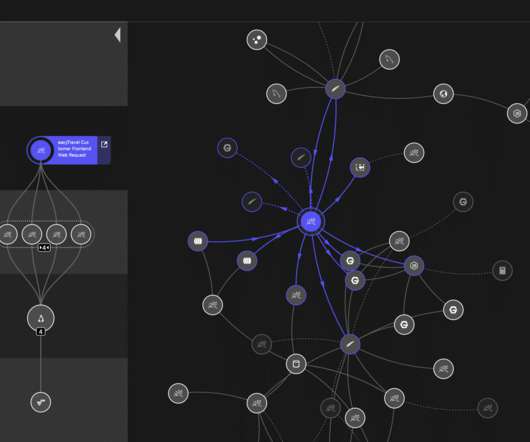
Data analysis within large and highly dynamic microservices environments is the biggest challenge that Application Performance Monitoring (APM) vendors face today. Dynatrace provides the widest monitoring coverage of software frameworks that are used in modern enterprise applications. Why are we doing this?
Adopting cloud-native technologies and open source software makes applications more feature rich and scalable, but it also increases IT complexity. In recent years, the number of vulnerabilities has overtaken the ability to effectively monitor IT environments manually. Learn what Spring4Shell is and how to detect and mitigate it.
Java Memory Management, with its built-in garbage collection, is one of the language’s finest achievements. However, garbage collection is one of the main sources of performance and scalability issues in any modern Java application. T his feature requires Java 11+. . Dynatrace news. Prerequisites.
Dynatrace’s collaboration with Google addresses these needs by providing simple, scalable, and innovative data acquisition for comprehensive analysis and troubleshooting. kubectl apply -f example.yml After applying the Dynakube definition, you must label the namespaces you wish to monitor with the selector we defined.
Our tactical approach was to use Netflix-specific libraries for collecting traces from Java-based streaming services until open source tracer libraries matured. We chose Open-Zipkin because it had better integrations with our Spring Boot based Java runtime environment. Storage: don’t break the bank!
Both backend and report service are implemented in Java, but Robert found no Java runtime-related issues, either. Dynatrace ingests Kubernetes events and assigns them to the monitored entities. Now they’re investing in more load, scalability, and memory testing with the goal of better understanding capacity requirements.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. You can configure and activate the following extensions in Dynatrace at Settings > Monitoring > Monitored technologies > Supported technologies : ActiveMQ.
For two decades, Dynatrace NAM—Network Application Monitoring, formerly known as DC RUM—has been successfully monitoring the user experience of our customers’ enterprise applications. Introducing network probes: the new scalability challenges were solved with products like NV and AV. Dynatrace news.
Through automated self-monitoring, we observe whether the update succeeded within a certain time window and whether the cluster runs within our defined Service Level Objectives (SLOs). Dynatrace progressive delivery includes automated self-monitoring of every Dynatrace cluster with Dynatrace. What does that mean?
It inherits the automation, AI, scalability, and enterprise-grade robustness of the Dynatrace platform. With new RASP capabilities of the Dynatrace OneAgent, the same trusted approach extends the Dynatrace platform to application security: automatic, intelligent, highly scalable. Next up: node.js.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Motivation Scalability and usability are essential to enable large-scale workflows and support a wide range of use cases.
With that, we could make use of the full set of OpenTelemetry’s features to instrument and monitor our applications in the Dynatrace back end, including traces with spans and metrics. OneAgent is the native telemetry data collector and monitoring solution of Dynatrace.
Scalability is a major feature of GCF. GCF also enables teams to run custom-written code to connect multiple services in Node, Python, Go, Java,NET, Ruby, and PHP. Observability and monitoring challenges with Google Cloud Functions. How Google Cloud Functions works. Avoid lock-in with open-source technologies. GCF use cases.
A dashboard for monitoring activities such as database locks, connected sessions, and prepared transactions for multiple servers. It is known for its flexibility and large feature set, as well as supporting databases utilizing a Java Database Connectivity (JDBC) driver, rendering it a default tool for both DBAs and developers.
From of our learnings on how we integrated Dynatrace into our DevOps toolchain , we advise our customers to follow our best practices around integrating delivery tools with Dynatrace, enforcing Dynatrace-based quality gates, implementing monitoring as code or automate remediation based on Dynatrace problems. Monitoring Configuration as Code.
IAST only works with languages that have a virtual runtime environment, such as Java, C#, Python, and Node.js. Once an application moves into the production environment, teams usually use other tools to monitor the applications. RASP can identify both vulnerabilities and malicious activities. So, why is all this important?
The key components of automatic failover include the primary server for write operations, standby servers for backup, and a monitor node for health checks and coordination of failover events. Tools for PostgreSQL high availability include automatic failover, monitoring, replication, and user management.
Provisioning of cloud infrastructure, especially within large environments, requires a standardized approach to scalability, compliance, and troubleshooting. Dynamic cloud operations call for an application performance management tool that can monitor individual customer workloads. Create a package with Maven: mvn package.
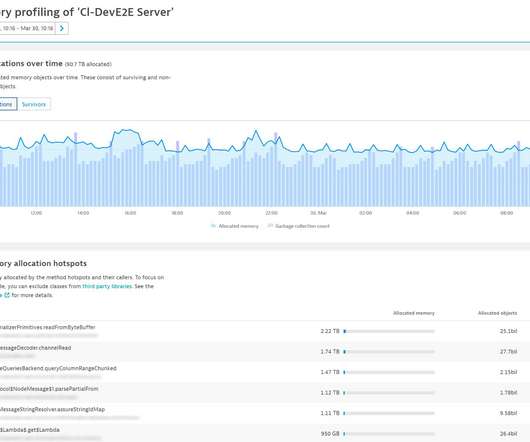
Cryostat, a container-native JVM application developed by Red Hat, provides an API for monitoring and profiling Java containers using Java Flight Recorder (JFR). Cryostat brings JFR to container age allowing analysis and profiling of multiple JVMs directly from a central hub. By Andrea Messetti.
This gives us access to Netflix’s Java ecosystem, while also giving us the robust language features such as coroutines for efficient parallel fetches, and an expressive type system with null safety. As this architecture matures, we will continue to monitor schema health and develop new tooling, processes, and best practices where needed.
Werner Vogels weblog on building scalable and robust distributed systems. Amazon SWF is an orchestration service for building scalable distributed applications. A growing number of applications are relying on asynchronous and distributed processing, with scalability of the application as the primary motivation. Comments ().
It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance.
For fast processing of the events, we use different settings of Kafka consumer and Java executor thread pool. We have set up the alerts and continuously monitor the production traffic which can be impacted because of the bulk old data reprocessing. We are using the Netflix Atlas framework to collect and monitor such metrics.
Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to load balancing. Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. Try the API now in this 5 minute interactive tutorial.
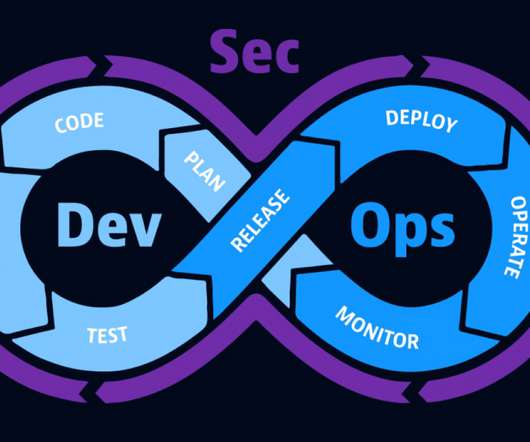
Site reliability engineering (SRE) is a software operations methodology that enables organizations to create highly reliable and scalable applications. Eliminate silos, improve cross-team collaboration, and release better software faster with DevOps monitoring – product page.
Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to load balancing. Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. Try the API now in this 5 minute interactive tutorial.
Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Don't be limited by the slow and narrow capabilities of traditional log monitoring tools. Learn more today.
It has connectors for programming languages such as Java, Python, and PHP, as well as integrations with popular data visualization tools such as Tableau and Power BI. Conclusion PostgreSQL is a top choice for production-ready databases due to its scalability, reliability, flexibility, security, and community support.
Leverage this data across your monitoring efforts and integrate with PerfOps’ other tools such as Alerts, Health Monitors and FlexBalancer – a smart approach to load balancing. Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. Try the API now in this 5 minute interactive tutorial.
Senior DevOps Engineer : Your engineering work will focus on using your deep knowledge of the web stack including firewalls, web applications, caches and data stores to create innovative infrastructure architectures that are resilient, scalable, and blazingly fast. Try the API now in this 5 minute interactive tutorial.
Upcoming topics include infrastructure and application monitoring, AI/ML platforms, and more. Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. Upcoming topics include infrastructure and application monitoring, AI/ML platforms, and more. No obligations, no marketing emails or sales calls.
Client libraries are available for Node, Ruby, Python, PHP, Go, Java and.NET. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Don't be limited by the slow and narrow capabilities of traditional log monitoring tools. Learn more today.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content