This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From social media to IoT devices, businesses are generating more data than ever before. With this data comes the challenge of processing it in a timely and efficient way. One of the most important decisions organizations make when it comes to data processing is whether to use stream or batch processing.
In the rapidly evolving landscape of the Internet of Things (IoT), edge computing has emerged as a critical paradigm to process data closer to the source—IoT devices. However, managing distributed workloads across various edge nodes in a scalable and efficient manner is a complex challenge.
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. Step-by-step setup The log ingestion wizard guides you through the prerequisites and provides ready-to-use command examples to start the installation process. Figure 5.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Edge computing involves processing data locally, near the source of data generation, rather than relying on centralized cloud servers. By 2025, more manufacturers will use edge computing to power IIoT devices, allowing them to process data, analyze trends, and respond to anomalies instantaneously.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Ask yourself, how much data should Fluent Bit process? What is Fluent Bit?
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
The Dynatrace platform automatically integrates OpenTelemetry data, thereby providing the highest possible scalability, enterprise manageability, seamless processing of data, and, most importantly the best analytics through Davis (our AI-driven analytics engine), and automation support available. What Dynatrace will contribute.
Edge computing has transformed how businesses and industries process and manage data. Data Overload and Storage Limitations As IoT and especially industrial IoT -based devices proliferate, the volume of data generated at the edge has skyrocketed. As data streams grow in complexity, processing efficiency can decline.
ERP systems offer standardized processes, enabling developers to accelerate development cycles and align with industry best practices. They contribute to efficiency, scalability , and improved decision-making, making them indispensable in modern software development.
As more organizations adopt cloud-native architectures, they are also looking for ways to implement AIOps, harnessing AI as a way to automate more processes throughout the DevSecOps life cycle. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
This article expands on the most commonly used RabbitMQ use cases, from microservices to real-time notifications and IoT. Key Takeaways RabbitMQ is a versatile message broker that improves communication across various applications, including microservices, background jobs, and IoT devices. What is a Message Queue?
AWS Lambda is a serverless compute service that can run code in response to predetermined events or conditions and automatically manage all the computing resources required for those processes. Real-time file processing, for quickly indexing files, processing logs, and validating content. The Amazon Web Services ecosystem.
Scalability is a major feature of GCF. The platform automatically manages all the computing resources required in those processes, freeing up DevOps teams to focus on developing and delivering features and functions. GCF also has relevance in IoT and file processing tasks. How Google Cloud Functions works.
This article introduces a scalability pattern – pipes and filters – that promotes reusability and is appropriate for such scenarios. Problem Context Consider a scenario where incoming data triggers a sequence of processing steps, where each step brings data closer to the desired output state.
RabbitMQ is an open-source message broker that simplifies inter-service communication by ensuring messages are effectively queued, delivered, and processed across diverse applications. RabbitMQ allows web applications to create and place messages in a message queue for further processing.
Data silos – Multiple agents, disparate data sources, and siloed monitoring tools make it hard to understand interdependencies across applications, multiple clouds, and digital channels such as web, mobile, and IoT. Making observability actionable and scalable for IT teams.
It is widely utilized across various industries, such as finance, telecommunications, and e-commerce, for managing activities, including transaction processing, data streaming, and instantaneous messaging. RabbitMQ’s versatile use cases range from web application backend services and distributed systems to PDF processing.
This article will help you understand the core differences in data structure, scalability, and use cases. MongoDB is a NoSQL database designed for unstructured data, offering flexibility and scalability with a schemaless architecture, making it suitable for applications needing rapid data handling.
The council has deployed IoT Weather Stations in Schools across the City and is using the sensor information collated in a Data Lake to gain insights on whether the weather or pollution plays a part in learning outcomes. Take GoSquared , a UK startup that runs all its development and production processes on AWS, as an example.
The population of intelligent IoT devices is exploding, and they are generating more telemetry than ever. The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processingIoT telemetry, from its arrival in the cloud through its storage in databases and data lakes.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. In-Order Processing The semantics of correct device information updates ingestion requires that messages be consumed in the order that they are produced.
The notes are stored in Amazon DynamoDB, and are processed asynchronously using DynamoDB streams and a Lambda function to add them to an Amazon CloudSearch domain. Real-time File Processing Serverless Reference Architecture. IoT Backend Serverless Reference Architecture.
The notes are stored in Amazon DynamoDB, and are processed asynchronously using DynamoDB streams and a Lambda function to add them to an Amazon CloudSearch domain. Real-time File Processing Serverless Reference Architecture. IoT Backend Serverless Reference Architecture.
The Amazon ML console and API provide data and model visualization tools, as well as wizards to guide you through the process of creating machine learning models, measuring their quality and fine-tuning the predictions to match your application requirements.
In previous blogs , we have explored the power of the digital twin model for stateful stream-processing. Digital twins are software abstractions that track the behavior of individual devices in IoT applications. Because real-world IoT applications can track thousands of devices or other entities (e.g.,
We are increasingly surrounded by intelligent IoT devices, which have become an essential part of our lives and an integral component of business and industrial infrastructures. In-memory computing has the speed and scalability needed to generate responses within milliseconds, and it can evaluate and report aggregate trends every few seconds.
These are exciting times in the evolution of stream-processing. As we have seen in previous blogs , the digital twin model offers a breakthrough approach to structuring stateful stream-processing applications. It represents a big step forward for building stream-processing applications.
In previous blogs , we have explored the power of the digital twin model for stateful stream-processing. Digital twins are software abstractions that track the behavior of individual devices in IoT applications. Because real-world IoT applications can track thousands of devices or other entities (e.g.,
Traditional stream-processing and complex event processing systems, such as Apache Storm and Software AG’s Apama , have focused on extracting interesting patterns from incoming data with stateless applications. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report.
Traditional stream-processing and complex event processing systems, such as Apache Storm and Software AG’s Apama , have focused on extracting interesting patterns from incoming data with stateless applications. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report.
Because it runs on a scalable, highly available in-memory computing platform, it can do all this simultaneously for hundreds of thousands or even millions of data sources. Message are delivered to the grid using messaging hubs, such as Azure IoT Hub, AWS IoT Core, Kafka, a built-in REST service, or directly using APIs.
Increased efficiency Leveraging advanced technologies like automation, IoT, AI, and edge computing , intelligent manufacturing streamlines production processes and eliminates inefficiencies, leading to a more profitable operation.
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., However, the process of deriving actionable insights out of this wide variety of data sources is not easy. QuickSight is a fast, cloud native, scalable, business intelligence service for the 1/10th the cost of old-guard BI solutions.
Internet of Things (IoT). Convenient Debugging : Debugging process is easy for the developers as single page application SPA offer developers tools. AI chatbots can handle complex processes and prompt answering, thereby providing seamless digital experiences with a company. Internet of Things (IoT). How does IoT work?
Automation is defined by Wikipedia as a wide range of technologies that reduce human involvement in processes. Mocking Component Behavior Useful in IoT & Embedded Software Testing Can also reduce (or eliminate) actual hardware/component need Test Reporting Generating summary report/email. Linking screenshots/logs to the reports.
Industrial IoT (IIoT) really means making industrial devices work together so they can communicate better for the sake of ultimately improving data analytics, efficiency, and productivity. This scalability ensures that organizations can continue to innovate and expand their capabilities seamlessly, without missing a step.
Whether it’s ecommerce shopping carts, financial trading data, IoT telemetry, or airline reservations, these data sets need fast, reliable access for large, mission-critical workloads. To help ensure fast data access and scalability, IMDGs usually employ a straightforward key/value storage model.
Whether it’s ecommerce shopping carts, financial trading data, IoT telemetry, or airline reservations, these data sets need fast, reliable access for large, mission-critical workloads. To help ensure fast data access and scalability, IMDGs usually employ a straightforward key/value storage model.
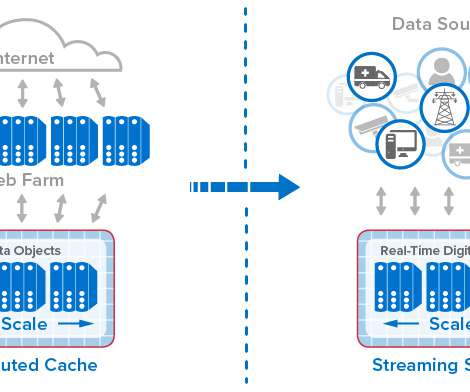
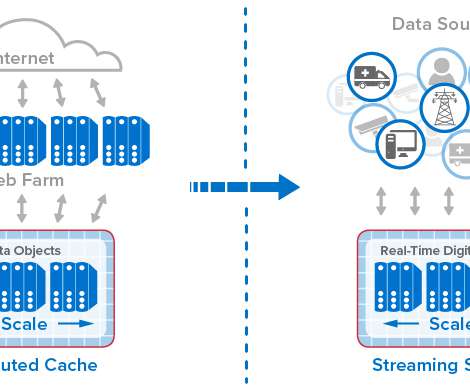
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins.
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins.
Private 5G Network Use cases To make the most out of private networks, organizations need to ensure they bake real-time data processing capabilities into the foundation of their architecture. Unlocking the full promise of a private 5G network is only possible when you have real-time data processing capabilities.
Real-time data platform defined A real-time data platform is designed to ingest, process, analyze, and act upon data instantaneously — right when it’s generated or received. Improved operational efficiency Real-time data platforms enhance operational efficiency by providing timely insights and automating processes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content