This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. In 2025, we expect to see the first releases, so youll be able to test out this innovative technology.
This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation. As a MISA member, we look forward to collaborating with Microsoft and other members to develop best practices, share insights, and drive innovation in cloud-native security.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
When we launched the new Dynatrace experience, we introduced major updates to the platform, including Grail ™, our innovative data lakehouse unifying observability, security, and business data, and Dynatrace Query Language ( DQL ) for accessing and exploring unified data. Next, let’s use the Kubernetes app to investigate more metrics.
In today’s rapidly evolving landscape, incorporating AI innovation into business strategies is vital, enabling organizations to optimize operations, enhance decision-making processes, and stay competitive. The annual Google Cloud Next conference explores the latest innovations for cloud technology and Google Cloud.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Recently, we’ve expanded our digital experience monitoring to cover the entire customer journey, from conversion to fulfillment.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
To explore this issue, we asked participants the following question: Which of your teams have access to production monitoring data? Three quick conclusions: 1) More than 80% of the respondents claim that their Development teams have access to production monitoring data. Production monitoring data: The lifeblood of cross-talented teams.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends. Agility and innovation.
However, while Kubernetes can help teams monitor the health of their environments and restart failed applications, the platform has limited visibility into the internal state of those applications. To watch the full session and learn more about how Dynatrace is accelerating innovation with Kubernetes, follow one of the local links below.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. How can you gain insights that drive innovation and reliability in AI initiatives without breaking the bank?
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Dynatrace recently opened up the enterprise-grade functionalities of Dynatrace OneAgent to all the data needed for observability, including metrics, events, logs, traces, and topology data. Davis topology-aware anomaly detection and alerting for your custom metrics. Seamlessly report and be alerted on topology-related custom metrics.
Software should forward innovation and drive better business outcomes. Conversely, an open platform can promote interoperability and innovation. Legacy technologies involve dependencies, customization, and governance that hamper innovation and create inertia. Data supports this need for organizations to flex and modernize.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Stage 2: Service monitoring.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. You’re getting all the architectural benefits of Grail—the petabytes, the cardinality—with this implementation,” including the three pillars of observability: logs, metrics, and traces in context.
Several team members had to pore through logs, metrics, and other data to identify issues. “We Ultimately, better infrastructure management enables organizations like Park ‘N Fly to innovate through software. To do so, organizations often succumb to a “hamster wheel” of having to release code more quickly to innovate effectively.
For many organizations, these back-end technology layers reveal blind spots in their current approach to monitoring. Spotty monitoring coverage makes it hard to identify, analyze, and resolve performance problems, which can endanger key business transactions and impact users. This metric helps you to understand your current workload.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. What is AWS observability?
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
Listen in to learn about the innovative steps that the USPTO has taken to develop new ways of working. With the platform boasting over 3,000 technical users and millions of end users, Dimitris sheds some light on his experience with SRE, User Experience, and Service Monitoring.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Option 1: Log Processing Log processing offers a straightforward solution for monitoring and analyzing title launches.
AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. But increasing complexity and lacking visibility creates a problem: Enterprises invest more resources into monitoring and don’t get the data and answers they need.
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
But this approach introduced new complexity and a need for more advanced cloud monitoring capabilities. Dynatrace’s cloud monitoring capabilities are helping Porsche Informatik to simplify complexity and drive improved digital experiences for customers. Simplifying complexity with cloud monitoring. The key value of Dynatrace.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Following the innovation of microservices, serverless computing is the next step in the evolution of how applications are built in the cloud. Monitor your serverless applications with just two clicks.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. The post Container monitoring for VA Platform One helps VA achieve workload performance appeared first on Dynatrace news.
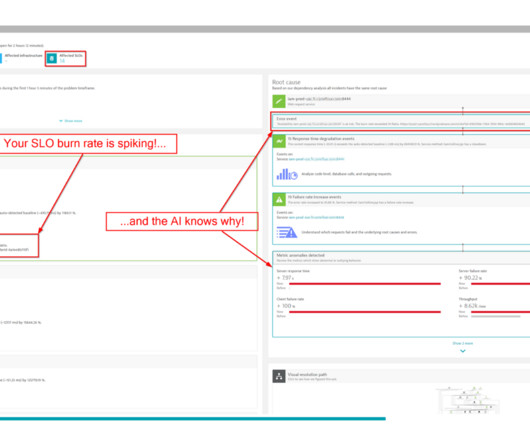
For most organizations, online service reliability that balances innovation and uptime is a primary goal. SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. What is SLO monitoring? And what is an error budget burn rate?
As more organizations transition to distributed services, IT teams are experiencing the limitations of traditional monitoring tools, which were designed for yesterday’s monolithic architectures. Where traditional monitoring falls flat. The architects and developers who create the software must design it to be observed.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Monitoring begins here. Logs, metrics, and traces make up the bulk of all telemetry data.
This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more. What is infrastructure monitoring? . What to look for when selecting an infrastructure monitoring solution?
These criteria include operational excellence, security and data privacy, speed to market, and disruptive innovation. But as a company with a mission to “ Do It Right ” and be a relentless ally for customers and communities, the high-cost monitoring solutions it was using provided only limited insights into end-user experiences.
But this approach introduced new complexity and a need for more advanced cloud monitoring capabilities. Dynatrace’s cloud monitoring capabilities are helping Porsche Informatik to simplify complexity and drive improved digital experiences for customers. Simplifying complexity with cloud monitoring. The key value of Dynatrace.
Echoing John Van Siclen’s sentiments from his Perform 2020 keynote, Steve cited Dynatrace customers as the inspiration and driving force for these innovations. “A Highlighting the company’s announcements from Perform 2020, Steve and a team of other Dynatrace product leaders introduced the audience to several of our latest innovations.
Full-stack observability is fast becoming a must-have capability for organizations under pressure to deliver innovation in increasingly cloud-native environments. A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance.
Businesses in all sectors are introducing novel approaches to innovate with generative AI in their domains. It shows critical SLOs for latency and availability, as well as the most important OpenAI generative AI service metrics, such as response time, error count, and the overall number of requests.
Dynatrace full stack observability for Red Hat OpenShift Dynatrace enhances software quality and operational efficiency, which drives innovation by unifying application, operation, and platform engineering teams on a single platform. You can automatically detect and analyze performance issues across your entire tech stack with Davis® AI.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. Dynatrace now monitors your AWS Outposts environment just like any AWS cloud Region. Next steps.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content