This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On top of this, organizations are often unable to accurately identify root causes across their dispersed and disjointed infrastructure. But first, there are five things to consider before settling on a unified observability strategy. What is prompting you to change? Don’t forget to incorporate cybersecurity and sustainability measures.
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
An AI observability strategy—which monitors IT system performance and costs—may help organizations achieve that balance. Training AI data is resource-intensive and costly, again, because of increased computational and storage requirements. They can do so by establishing a solid FinOps strategy. What is AI observability?
And we know as well as anyone: the need for fast transformations drives amazing flexibility and innovation, which is why we took Perform Hands-on Training (HOT) virtual for 2021. Taking training sessions online this year lets us provide more instructor-led sessions over more days and times than ever before. So where do you start?
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Your trained eye can interpret them at a glance, a skill that sets you apart. However, your responsibilities might change or expand, and you need to work with unfamiliar data sets.
Digital transformation strategies are fundamentally changing how organizations operate and deliver value to customers. A comprehensive digital transformation strategy can help organizations better understand the market, reach customers more effectively, and respond to changing demand more quickly. Competitive advantage.
From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. Employee training in cybersecurity best practices and maintaining up-to-date software and systems are also crucial. Outages can disrupt services, cause financial losses, and damage brand reputations.
I recently joined two industry veterans and Dynatrace partners, Syed Husain of Orasi and Paul Bruce of Neotys as panelists to discuss how performance engineering and test strategies have evolved as it pertains to customer experience. The post Panel Recap: How is your performance and reliability strategy aligned with your customer experience?
Augmenting LLM input in this way reduces apparent knowledge gaps in the training data and limits AI hallucinations. The LLM then synthesizes the retrieved data with the augmented prompt and its internal training data to create a response that can be sent back to the user. million AI server units annually by 2027, consuming 75.4+
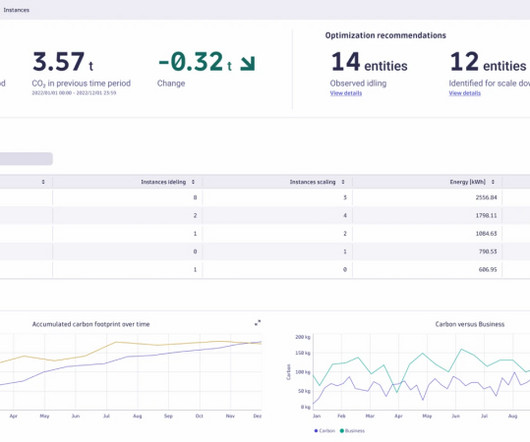
Research from 2020 suggests that training a single LLM generates around 300,000 kg of carbon dioxide emissions—equal to 125 round-trip flights from New York to London. As we onboard more customers, the platform requires more infrastructure, leading to increased carbon emissions. This adoption will further impact carbon emissions.
The directive mandates operators of critical infrastructure and essential services to implement appropriate security measures and promptly report any incidents to the relevant authorities and affected parties. Application security must inform any robust NIS2 compliance strategy. What types of incidents must be reported?
A robust partner ecosystem can drive advancements in cloud infrastructure, application performance, and AI-driven insights, ensuring that businesses can deliver seamless digital experiences for customers. As enterprises globally undergo digital transformations, leveraging the right tools and expertise becomes crucial.
And what are the best strategies to reduce manual labor so your team can focus on more mission-critical issues? With ever-evolving infrastructure, services, and business objectives, IT teams can’t keep up with routine tasks that require human intervention. AI that is based on machine learning needs to be trained.
One effective capacity-management strategy is to switch from a reactive approach to an anticipative approach: all necessary capacity resources are measured, and those measurements are used to train a prediction model that forecasts future demand. You can use any DQL query that yields a time series to train a prediction model.
With the prevalence of cyber threats and regulatory pressures, safeguarding your enterprise’s cloud infrastructure is more critical than ever. This proactive approach also needs to take into consideration complexities arising from multi-cloud or hybrid cloud strategies to achieve holistic enterprise cloud security.
As organizations train generative AI systems with critical data, they must be aware of the security and compliance risks. Therefore, these organizations need an in-depth strategy for handling data that AI models ingest, so teams can build AI platforms with security in mind. Check out the resources below for more information.
Generally speaking, cloud migration involves moving from on-premises infrastructure to cloud-based services. In cloud computing environments, infrastructure and services are maintained by the cloud vendor, allowing you to focus on how best to serve your customers. However, it can also mean migrating from one cloud to another.
Because of this, it is more critical than ever for organizations to leverage a modern observability strategy. The event focused on empowering and informing our valued partner ecosystems by providing updates on strategy, market opportunities, cloud modernization, and a wealth of crucial insights. Building apps and innovations.
Teams require innovative approaches to manage vast amounts of data and complex infrastructure as well as the need for real-time decisions. Generative AI: A type of AI that uses an algorithm trained on large amounts of data collected from diverse sources to generate various types of content, including text, images, audio, and synthetic data.
Marketers can use these insights to better understand which messages resonate with customers and tailor their marketing strategies accordingly. The logs, metrics, traces, and other metadata that applications and infrastructure generate have historically been captured in separate data stores, creating poorly integrated data silos.
FinOps is a cloud financial management philosophy and practice that strives to control the cost of cloud adoption strategies without restricting the scope of cloud resources. Create optimization strategies with realistic goals for each team. The result is smarter, data-driven solutions designed to manage cloud spend. What is FinOps?
Organizations that have achieved SRE maturity have a better handle on the state of their infrastructure, the ability to tie reliability metrics more tightly to business objectives, and the means to ensure a consistent and responsive customer experience. Dynatrace’s 2022 State of SRE Report surveyed 450 SREs across the globe.
Machine learning algorithms use vast amounts of data to train systems and allow them to draw accurate conclusions based on available information. Supervised learning uses already-labeled data to train algorithms for specific outputs. There are two broad types of machine learning: supervised and unsupervised. Enhanced visibility.
Despite these investments, these organizations have complete visibility into just 11% of the applications and infrastructure in their environments. It takes times to train statistics-based machine learning solutions, and this approach doesn’t scale easily with modern, dynamic cloud-native environments.
Large language models (LLMs), which are the foundation of generative AIs, are neural networks: they learn, summarize, and generate content based on training data. Observability, security, and business use cases raise additional challenges as they need precision and reproducibility.
Pairing generative AI with causal AI One key strategy is to pair generative AI with causal AI , providing organizations with better-quality data and answers as they make key decisions. Because generative AI is probabilistic in nature, its value depends on the quality of data that trains its algorithms and prompts.
We built Axion primarily to remove any training-serving skew and make offline experimentation faster. We make sure there is no training/serving skew by using the same data and the code for online and offline feature generation. Our machine learning models train on several weeks of data.
A look at the roles of architect and strategist, and how they help develop successful technology strategies for business. I'm offering an overview of my perspective on the field, which I hope is a unique and interesting take on it, in order to provide context for the work at hand: devising a winning technology strategy for your business.
Serverless architecture enables organizations to deliver applications more efficiently without the overhead of on-premises infrastructure, which has revolutionized software development. Gartner data also indicates that at least 81% of organizations have adopted a multicloud strategy. Digital transformation creates complexity.
In the age of AI, data observability has become foundational and complementary to AI observability, data quality being essential for training and testing AI models. Data is the foundation upon which strategies are built, directions are chosen, and innovations are pursued.
Simply knowing the different forms of performance testing that we have available to us, and where they sit in the product development process, makes it much easier for businesses to adopt a performance strategy and keep on top of things. Who: Engineers. When: During development. Who: Engineers, Product Owners, Marketing.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Working on a customer win-back strategy is cost-intensive and not always fruitful, which makes having an excellent DX more crucial than ever. DEM helps teams understand the context of what’s going on amid the interactions happening across the multitude of apps, services, and infrastructure of your multicloud environment.
In this time, I learned a lot, but the price for this was to have to deal with random infrastructure issues and unhelpful support from HP. I must confess I was feeling so high and mighty about using LoadRunner, the “best” tool in the market, that it took this 3 day training to have me realize that viable alternatives existed.
Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. Training models and developing complex applications on top of those models is becoming easier. of nonusers, 5.4%
This article strips away the complexities, walking you through best practices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. Cloud security monitoring is key—identifying threats in real-time and mitigating risks before they escalate.
Without infrastructure-level support, every team ends up building their own point solution to varying degrees of success. Gutenberg allows browsing older versions of data for use cases such as debugging, rapid mitigation of data related incidents, and re-training of machine-learning models. for example to train machine-learned models.
They were either running their own infrastructure and installing and deploying Brotli everywhere proved non-trivial, or they were using a CDN who didn’t have readily available support for the new algorithm. I started off this whole train of thought because I wanted to see, realistically, what impact Brotli might have for real websites.
According to a 2023 Forrester survey commissioned by Hashicorp , 61% of respondents had implemented, were expanding, or were upgrading their multi-cloud strategy. Nearly every vendor at Kubecon and every person we spoke to had some form of a multi-cloud requirement or strategy. We expect that number to rise higher in 2024.
Develop strategies to mitigate these risks and have contingency plans in place. Communication and training: Keep all stakeholders informed about the progress and changes throughout the migration process. Provide training to staff members, DBAs, and developers to ensure they are well-prepared for the transition.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. Executing cutting-edge intelligent apps’ deployment after successful training becomes much easier thanks primarily to this functionality made possible!
Application performance monitoring focuses on specific metrics and measurements; application performance management is the wider discipline of developing and managing an application performance strategy. Automatic discovery and mapping of application and its infrastructure components to maintain real-time awareness in dynamic environments.
To achieve this, a substantial commitment is necessary from your team to master effective testing strategies. This entails providing comprehensive training for your staff, equipping them with both foundational and sophisticated testing methodologies. You can read more about Pateron’s success story here.
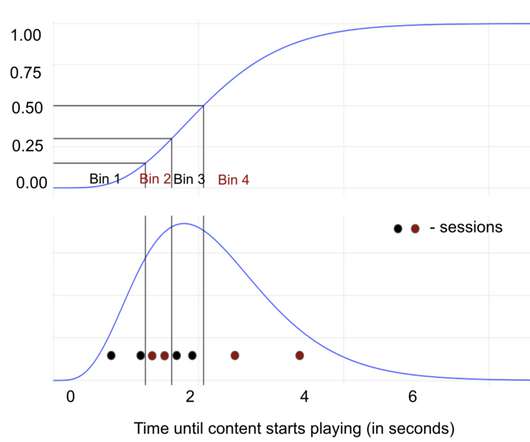
Julie (Novak) Beckley, Andy Rhines, Jeffrey Wong, Matthew Wardrop, Toby Mao, Martin Tingley Ever wonder why Netflix works so well when you’re streaming at home, on the train, or in a foreign hotel? The Bootstrapping Methods Suppose you are watching The Crown on a train and Claire Foy’s face appears pixelated.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content