This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. Such infrastructures must implement additional controls to securely separate each customer’s data.
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
As software pipelines evolve, so do the demands on binary and artifact storage systems. Enterprises must future-proof their infrastructure with a vendor-neutral solution that includes an abstraction layer , preventing dependency on any one provider and enabling agile innovation.
Therefore, they need an environment that offers scalable computing, storage, and networking. That’s where hyperconverged infrastructure, or HCI, comes in. What is hyperconverged infrastructure? For organizations managing a hybrid cloud infrastructure , HCI has become a go-to strategy. Realizing the benefits of HCI.
CSPM solutions continuously monitor and improve the security posture of Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) environments. However, if you only use minimal cloud services, your cloud environment is static, or you rely on on-premises infrastructure, CSPM may not be worth buying yet.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage.
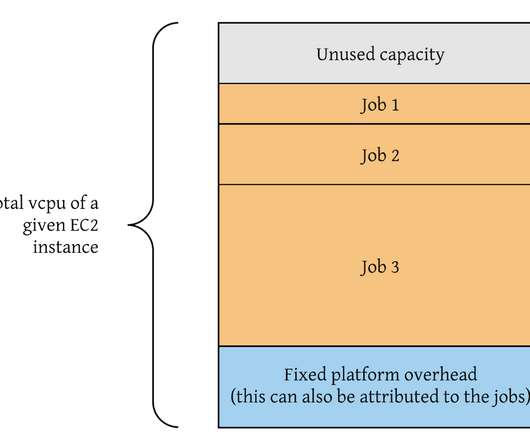
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. It is important to understand the impact infrastructure can have on the platform and the application it runs.
This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures. Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization.
Dynatrace Managed is the on-premises software intelligence platform that brings Dynatrace SaaS capabilities to your infrastructure while ensuring resilience and optimizing the total cost of ownership. Using existing storage resources optimally is key to being able to capture the right data over time. Dynatrace news.
The methodology and algorithms were designed by Dynatrace with guidance from the Sustainable Digital Infrastructure Alliance (SDIA), expanding on formulas from the open source project Cloud Carbon Footprint. Green coding focuses on the software that is running on our digital infrastructure.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. And that includes infrastructure monitoring. This also implies a fundamental change to the role of infrastructure and operations teams. Able to provide answers, not just data.
Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback. This infrastructure is available for Netflix shows and is foundational under Content Hubs Media Production Suite tooling. So what isit?
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Network device visibility (hosts, switches, routers, storage devices).
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
There are certain situations when an agent based approach isn’t possible, such as with network or storage devices, or a very old OS. In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? Easy and flexible infrastructure monitoring.
Configuration and Compliance , adding the configuration layer security to both applications and infrastructure and connecting it to compliance. Detection and Response , connecting log management and security, addressing what previously required a dedicated SIEM, and automating detection and response. Were challenging these preconceptions.
As a developer, engineer, or architect, finding the right storage solution that seamlessly integrates with your infrastructure while providing the necessary scalability, security, and performance can be a daunting task. Whether you're a small startup or a large enterprise, StoneFly's storage solutions can grow with your business.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Track business metrics, key performance indicators (KPIs), and service level objectives (SLOs) — automatically and in context with IT infrastructure and services — to promote collaboration between business and IT teams. Reduced storage and query overhead for business use cases. Business process monitoring and optimization.
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. IaC enables treating infrastructure setups as version-controlled code, allowing for automated provisioning, deployment, and configuration management.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
In this blog post, youll learn how Dynatrace OneAgent automatically identifies Journald and ingests structured logs into Dynatrace while enriching them with topology and infrastructure context. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts.
Our goal in building a media-focused ML infrastructure is to reduce the time from ideation to productization for our media ML practitioners. Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. We accomplish this by paving the path to: Accessing and processing media data (e.g.
Data migration involves transferring data from on-premise storage to the cloud. With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud. Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Reliability.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. where an error occurred at the code level.
With this solution, customers will be able to use Dynatrace’s deep observability , advanced AIOps capabilities , and application security to all applications, services, and infrastructure, out-of-the-box. All data at rest is stored in Azure Storage and is encrypted and decrypted using 256-bit AES encryption (FIPS 140-2 compliant).
Logstash: a log-processing tool that collects logs from various sources, parses them, and sends them to Elasticsearch for storage and analysis. The Infrastructure of Elasticsearch Before we dive into deploying the ELK Stack, let's first understand the critical components of Elasticsearch's infrastructure:
This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. FaaS drills down even deeper to scale specific aspects of storage, compute, or other services.
Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices. Dynatrace supports scalable data ingestion, ensuring your observability infrastructure grows with your cloud environment. The dashboard tracks a histogram chart of total storage utilized with logs daily.
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Teams have introduced workarounds to reduce storage costs. Stop worrying about log data ingest and storage — start creating value instead.
Vidhya Arvind , Rajasekhar Ummadisetty , Joey Lynch , Vinay Chella Introduction At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. The KV data can be visualized at a high level, as shown in the diagram below, where three records are shown.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure. Polymorphic Data Storage. Greenplum Advantages.
To meet this need, the Studio Infrastructure team has created Netflix Workstations. They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. We rely on our internal partner teams to support components installed on the workstation, such as storage and artist tools.
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. Unlike data warehouses, however, data is not transformed before landing in storage. A data lakehouse provides a cost-effective storage layer for both structured and unstructured data. Data management.
As companies migrate their infrastructure and development workloads to the cloud, there are numerous use cases for log analytics. Consider the following ways teams can apply log analytics to on-premises and multicloud infrastructures: Application deployment verification. Cold storage and rehydration. Inadequate context.
This approach provides a few advantages: Low burden on existing systems: Log processing imposes minimal changes to existing infrastructure. Additionally, the time-sensitive nature of these investigations precludes the use of cold storage, which cannot meet the stringent SLAs required.
As companies migrate their infrastructure and development workloads to the cloud, there are numerous use cases for log analytics. Consider the following ways teams can apply log analytics to on-premises and multicloud infrastructures: Application deployment verification. Cold storage and rehydration. Inadequate context.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. Let’s dive into the various aspects of this abstraction.
FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. After that, the post gets added to the feed of all the followers in the columnar data storage. System Components. Fetching User Feed. Optimization.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content