This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. One of our softwareengineers, Tomasz Gajger, has been involved in a research project related to GPU performance analysis. Looking for ways to solve some of your infrastructure-related problems?
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
The events of 2020 accelerated the trend of organizations shifting to cloud-native technologies in response to the dramatic increase in demand for online services. Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. Dynatrace news. SRE vs DevOps?
Because of its matrix of cloud services across multiple environments, AWS and other multicloud environments can be more difficult to manage and monitor compared with traditional on-premises infrastructure. AWS provides a suite of technologies and serverless tools for running modern applications in the cloud. Amazon EC2. AWS Lambda.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE requires a cultural change.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Adopting an SRE approach also requires that teams standardize the technologies and tools they use.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix. Pallavi, what’s your journey to data engineering at Netflix?
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. Operations automation: The operations section addresses the level of automation organizations use in maintaining and managing existing software.
If you want to practice, focus on medium-difficulty real-world problems you might encounter in a softwareengineering role. Let us know if you need any assistive technology or other accommodations ahead of time, and we’ll be sure to work with you to get it set up. Be sure to have questions prepared to ask the interviewers.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
Check out the following use cases to learn how to drive innovation from development to production efficiently and securely with platform engineering observability. These standards can be custom for specific teams, technologies, or criticalities. Standards for consistency. Real-time detection for fast remediation.
In our quest for greater scalability, resilience, and flexibility within the digital infrastructure of our organization, there has been a strategic pivot away from traditional monolithic application architectures towards embracing modern softwareengineering practices such as microservices architecture coupled with cloud-native applications.
There are a few qualities that differentiate average from high performing softwareengineering organisations. In my experience, the culture is better and the results are better in orgs where engineers and architects obsess over the design of code and architecture. My experience is the opposite.
How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of softwareengineering to infrastructure management, both on-premises and in the cloud. However, cloud complexity has made software delivery challenging. But the transition to SRE maturity is not always easy.
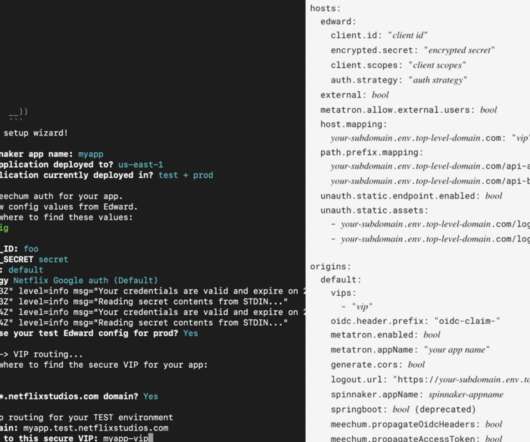
Our gateways are powered by our flagship open-source technology Zuul. During our initial consultations, it was clear that developers preferred prioritizing product work over security or infrastructure improvements. You’ll hear from two teams here: first Application Security, and then Cloud Gateway.
Companies now recognize that technologies such as AI and cloud services have become mandatory to compete successfully. AI data analysis can help development teams release software faster and at higher quality. As organizations adopt more AI technologies, the associated costs are skyrocketing.
FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. The streaming data store makes the system extensible to support other use-cases (e.g. media search index, locations search index, and so forth) in future.
Although IT teams are thorough in checking their code for any errors, an attacker can always discover a loophole to exploit and damage applications, infrastructure, and critical data. If a malicious attacker can identify a key software vulnerability, they can exploit the vulnerability, allowing them to gain access to your systems.
Join us and be a part of the amazing team that brought you this tech-blog; open positions: SoftwareEngineer, Cloud Gaming SoftwareEngineer, Live Streaming References [1] L. Krasula, A. Choudhury, S. Malfait, A. 263–1–8 (2023) [ online ] [2] A. Choudhury, L. Krasula, S.
With our enhanced AWS Lambda extension , we bring the power of Dynatrace PurePath 4 automatic tracing technology to serverless function observability. Serverless architectures help developers innovate more efficiently and effectively by removing the burden of managing underlying infrastructure. Dynatrace news. applications,?mobile
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? All ML projects are software projects. Why: Data Makes It Different.
DevOps is a software delivery methodology that comprises flexible practices and processes to create and deliver applications and services, ultimately closing the gap between software development and IT operations. Rather than a technology, DevOps is a tactical approach to application development. What is DevSecOps?
In the early days of the personal computer, every computer manufacturer needed softwareengineers who could write low-level drivers that performed the work of reading and writing to memory boards, hard disks, and peripherals such as modems and printers. There is so much to learn about how to apply the new technology.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Datadog is a cloud-scale monitoring platform that combines infrastructure metrics, distributed traces, and logs all in one place. Who's Hiring? Apply here. Need excellent people?
pMD is a fast growing , highly rated health care technology company that has been recognized as a Best Place to Work by SF Business Times, Modern Healthcare, and Inc. Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. The technology has been cited in more than 700 research papers and trusted by many Fortune 500 companies. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. The technology has been cited in more than 700 research papers and trusted by many Fortune 500 companies. Apply here.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. The technology has been cited in more than 700 research papers and trusted by many Fortune 500 companies. Apply here.
Close is building the sales communication platform of the future and we're looking for a Site Reliability Engineer to help us accomplish that goal. Wynter is looking for system administrators, engineers, and developers to join its research panel. They also do live system design discussions every week. Try out their platform.
Close is building the sales communication platform of the future and we're looking for a Site Reliability Engineer to help us accomplish that goal. Wynter is looking for system administrators, engineers, and developers to join its research panel. They also do live system design discussions every week. Try out their platform.
Close is building the sales communication platform of the future and we're looking for a Site Reliability Engineer to help us accomplish that goal. Wynter is looking for system administrators, engineers, and developers to join its research panel. They also do live system design discussions every week. Try out their platform.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. The technology has been cited in more than 700 research papers and trusted by many Fortune 500 companies. Apply here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content