This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and softwarearchitectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
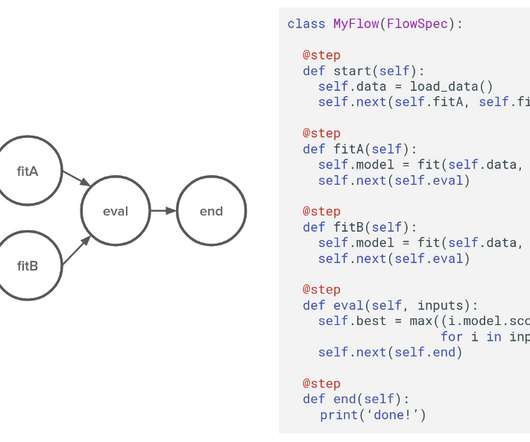
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. In effect, the engineer designs and builds the world wherein the software operates. What: The Modern Stack of ML Infrastructure.
There are a few qualities that differentiate average from high performing softwareengineering organisations. I believe that attitude towards the design of code and architecture is one of them. The same mindset should also be applied to architecture; involve the whole team and challenge the small details.
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering.
O’Reilly Learning > We wanted to discover what our readers were doing with cloud, microservices, and other critical infrastructure and operations technologies. More than one-third have adopted site reliability engineering (SRE); slightly less have developed production AI services. All told, we received 1,283 responses. .
Respondents who have implemented serverless made custom tooling the top tool choice—implying that vendors’ tools may not fully address what organizations need to deploy and manage a serverless infrastructure. A related point: the rise of the serverless paradigm coincides with what we’ve referred to elsewhere as “ Next Architecture.”
Incremental Hollow is like a faster time machine To achieve this, we created an incremental Hollow infrastructure for Netflix, leveraging work which had been done in the Hollow library earlier, and pioneered in production usage by the Streaming Platform Team at Target (and is now a public non-beta API ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content