This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
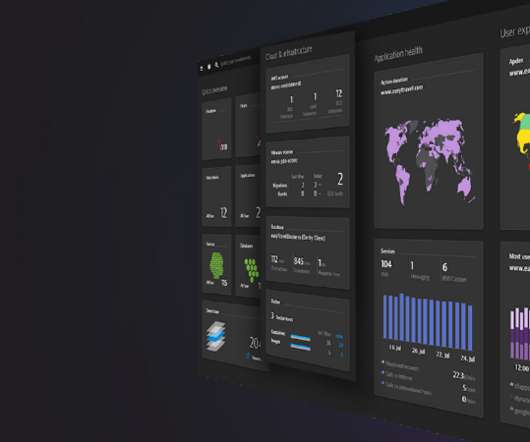
And it enables executives to have unprecedented insight into how user experiences, applications and underlying infrastructure health can power their business. By automating root-cause analysis, TD Bank reduced incidents, speeding up resolution times and maintaining system reliability. The result?
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. What is RabbitMQ? This allows Kafka clusters to handle high-throughput workloads efficiently.
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
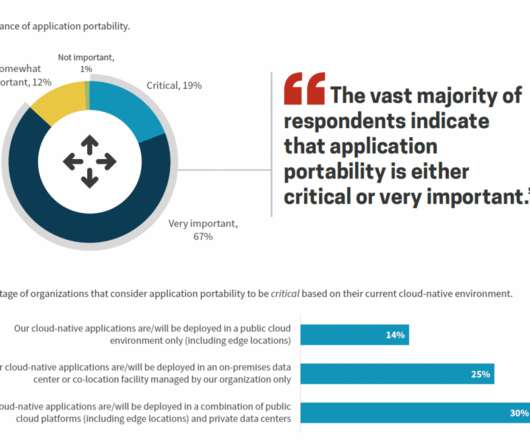
Some organizations need to weigh cost considerations due to technology and business scalability limitations whereas others need to adhere to company policies. These numbers serve as limits for scalability, utilizing the power of the Kubernetes platform. For large enterprises, this is not even a consideration.
To remain competitive in today’s fast-paced market, organizations must not only ensure that their digital infrastructure is functioning optimally but also that software deployments and updates are delivered rapidly and consistently. This approach supports innovation, ambitious SLOs, DevOps scalability, and competitiveness.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. These methods improve the software development lifecycle (SDLC), but what if infrastructure deployment and management could also benefit? GitOps improves speed and scalability. Dynatrace news.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access.
Effective application development requires speed and specificity. Before an organization moves to function as a service, it’s important to understand how it works, its benefits and challenges, its effect on scalability, and why cloud-native observability is essential for attaining peak performance. Dynatrace news. What is FaaS?
In today’s rapidly evolving business and technology landscape, organizations often prioritize the speed of development over security. Modern solutions like Snyk and Dynatrace offer a way to achieve the speed of modern innovation without sacrificing security.
Cloud computing skyrocketed onto the market 20+ years ago and has been widely adopted for the scalability and accelerated innovation it brings organization. As on-prem data centers become obsolete, and organizations look to modernize, Azure has the flexibility and scalability to adapt to the business needs of your organic IT landscape.
In the Magic Quadrant report, Gartner defines APM as, “software that enables the observation of application behavior and its infrastructure dependencies, users, and business key performance indicators (KPIs) throughout the application’s life cycle.” It’s this combination that helps our customers deal with the explosion of observability data.
Optimizing Trino to make it faster can help organizations achieve quicker insights and better user experiences, as well as cut costs and improve infrastructure efficiency and scalability. An open-source distributed SQL query engine, Trino is widely used for data analytics on distributed data storage. But how do we do that?
5), hybrid infrastructure platform operations (4.25/5), Unified observability has become mandatory Many organizations turn to multicloud environments to keep up with the speed of the market. Additionally, Dynatrace ranked first in three of five Use Cases in the 2024 Gartner Critical Capabilities for Observability Platforms.
It is based on the IBM AS/400 system and is known for its reliability, scalability, and security features. Messages overview Monitor disks and disk pool utilization One of the most important functions of your mainframe infrastructure is reading and writing data at high speeds while making it readily available.
To do so we have successfully established AI-based White box load and resiliency testing with JMeter and Dynatrace, helping identify and resolve major performance and scalability problems in recent projects before deploying to production. Each step is automated from provisioning infrastructure to problem analysis. zone } } } }.
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. But with that speed and agility comes new complications and complexity, all while maintaining performance and reliability with less than 1% down-time per year.
Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. From the beginning, Grail was built to be fast and scalable to manage massive volumes of data. Ingest and process with Grail.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. Learn more.
Certified for Red Hat OpenShift, Dynatrace is now available on the Red Hat Marketplace for customers to try, buy, and deploy, to manage their enterprise applications and infrastructure across their dynamic multi-cloud environments. That’s where Red Hat OpenShift came into play.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. What is site reliability engineering? SRE drives a “shift left” mindset.
Speed index. Hold regular meetings and troubleshooting sessions to ensure a holistic approach to DEM that considers all aspects of your infrastructure and CX. Visually complete. The time to fully render content in viewpoint. HTML downloaded. How quickly visible parts of the page are rendered. Load event start. Load event end.
Today, DevOps orchestration is necessary to gain a comprehensive view and means of control over infrastructure, services, and software development practices. In a similar way that developers automate a single task to improve consistency, efficiency, and speed, orchestration tools can coordinate the automation of tasks across platforms.
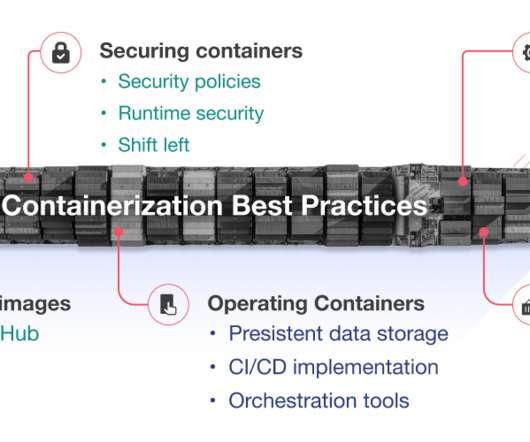
Organizations are chasing containerization technology to have infrastructure optimization, scalability, operational consistency, concrete resilience, productivity, and agility. The post 16 Containerization Best Practices: Speed Up Your Application Delivery by 3X appeared first on Insights on Latest Technologies - Simform Blog.
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Critical success factors – velocity, resilience, and scalability. Automated release inventory and version comparison.
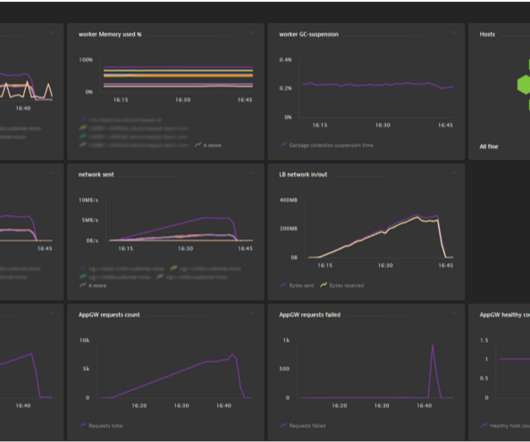
DevOps monitoring is an observability practice that creates a real-time view of the status of applications, services, and infrastructure in pre-production and production environments. The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases.
However, with our rapid product innovation speed, the whole approach experienced significant challenges: Business Complexity: The existing SKU management solution was designed years ago when the engagement rules were simple? Building a scalable SKU catalog platform that allowed for rapid changes with the minimal intervention was challenging.
Figure 1 Investment shift from infrastructure-centric to application-centric. The objective is for business agility, the ability to adapt applications and supporting infrastructure at speed to meet changing and evolving needs. 2021 ISG Provider Lens Container Services & Solutions Report. That’s a wrap from Amplify PowerUP!
This is where email infrastructure comes in handy. While you have limited control over user interaction with your emails, monitoring email infrastructure is in your hands. Email infrastructure usually consists of your server and domain configuration, server performance, IP address, mail agents, and more. Mail Agent.
A typical example of modern "microservices-inspired" Java application would function along these lines: Netflix : We observed during experimentation that RAM random read latencies were rarely higher than 1 microsecond whereas typical SSD random read speeds are between 100–500 microseconds. There are a few more quotes.
Organizations are shifting towards cloud-native stacks where existing application security approaches can’t keep up with the speed and variability of modern development processes. You need to go deeper into the stack — into the infrastructure itself. Automatic vulnerability detection for Kubernetes platform versions.
Infrastructure type In most cases, legacy SIEM tools are on-premises. Security analytics must also contend with the multicomponent architecture of modern IT infrastructure. Finally, observability helps organizations understand the connections between disparate software, hardware, and infrastructure resources.
As part of its Distributed Cloud research series , the Enterprise Strategy Group (ESG) surveyed 387 North American IT professionals responsible for managing application infrastructure. Automation and software intelligence improves the scalability of frequent release cycles for teams using DevOps and GitOps methodologies.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. A major goal of SRE is to reduce duplication or redundancy of effort as much as possible.
One element of our customers’ (and our own) success is the speed of innovation at which we operate. A single OneAgent installed on each monitored host can automatically and continuously discover all application and infrastructure components and their dependencies across an environment, thereby enabling Software Intelligence at scale.
The complexity of such deployments has accelerated with the adoption of emerging, open-source technologies that generate telemetry data, which is exploding in terms of volume, speed, and cardinality. How can we optimize for performance and scalability? Common questions include: Where do bottlenecks occur in our architecture?
According to one statistic, 76% of digital teams are responsible for delivering revenue , so software reliability and scalability are an increasing focus as these teams contribute to the bottom line. The five elements of digital immunity. The increased pace of business has correspondingly accelerated the pace of software development.
In our increasingly digital world, the speed of innovation is key to business success. As a result, e xisting application security approaches can’t keep up with this speed and vari ability of modern development processes. . Dynatrace news. Organizations are rushing towards cloud-native application stacks for agility.
Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure. At a glance – TLDR. The Greenplum Architecture.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
Vulnerability assessment: Protecting applications and infrastructure – Blog. Vulnerability assessment tools are essential for protecting IT infrastructure, applications, and data. Still, while DevOps and DevSecOps practices enable development agility and speed, they can also fall victim to tool complexity and data silos.
In turn, manual approaches to identifying code issues and troubleshooting are not scalable. But DevOps automation isn’t just about reducing manual effort and increasing process speed; it’s also about gaining insight with answer-driven operations. This statistic is despite the $9.1
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Failures can occur unpredictably across various levels, from physical infrastructure to software layers.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content