This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How to achieve sustainable IT practices Use observability tools The first step in driving improvements is to obtain a comprehensive view of your IT infrastructure’s climate impact. For example, reporting jobs can process monthly data without running exactly at the end of the month.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages.
Platform engineering is a practice that outlines how development teams build internal platforms to create self-service capabilities for softwareengineering teams. The result is a cloud-native approach to software delivery. Platform engineering cannot stand alone, however.
DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps is not a specific process, but rather a general collection of flexible software creation and delivery practices that looks to close the gap between software development and IT operations.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. With DQL, the workflow trigger to initiate a required automation and remediation process can be defined.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Open source logs and metrics take precedence in the monitoring process.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructureprocesses to help organizations create highly reliable and scalable software systems. Dynatrace news.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. They enable IT teams to identify and address the precise cause of application and infrastructure issues.
Platform engineering creates and manages a shared infrastructure and set of tools, such as internal developer platforms (IDPs) , to enable software developers to build, deploy, and operate applications more efficiently. This process is vital to an IDP’s effectiveness. “It makes them more productive.
Softwareengineering for machine learning: a case study Amershi et al., Previously on The Morning Paper we’ve looked at the spread of machine learning through Facebook and Google and some of the lessons learned together with processes and tools to address the challenges arising. A general process. ICSE’19.
At the 2024 Dynatrace Perform conference in Las Vegas, Michael Winkler, senior principal product management at Dynatrace, ran a technical session exploring just some of the many ways in which Dynatrace helps to automate the processes around development, releases, and operation.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructureprocesses to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE drives a “shift left” mindset.
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. DevOps automation eliminates extraneous manual processes, enabling DevOps teams to develop, test, deliver, deploy, and execute other key processes at scale.
As software development grows more complex, managing components using an automated onboarding process becomes increasingly important. However, scaling up software development requires more tools along the software product lifecycle, which must be configured promptly and efficiently.
FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. There are two major processes which gets executed when a user posts a photo on Instagram. System Components. Streaming Data Model. Optimization.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. To reduce developers’ cognitive load by providing timely information, platform engineers must create tools that allow validations to be run in the early phases of development, with direct and fast feedback loops.
DevOps is a widely practiced set of procedures and tools for streamlining the development, release, and updating of software. In their most basic form, DevOps procedures can result in complicated processes, data silos, and fragmented responsibilities. DevOps orchestration in practice. Automation versus orchestration.
Because of its matrix of cloud services across multiple environments, AWS and other multicloud environments can be more difficult to manage and monitor compared with traditional on-premises infrastructure. EC2 is Amazon’s Infrastructure-as-a-service (IaaS) compute platform designed to handle any workload at scale. Amazon EC2.
You apply for multiple roles at the same company and proceed through the interview process with each hiring team separately, despite the fact that there is tremendous overlap in the roles. Interviewing can be a daunting endeavor and how companies, and teams, approach the process varies greatly.
Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix. Pallavi, what’s your journey to data engineering at Netflix?
How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of softwareengineering to infrastructure management, both on-premises and in the cloud. However, cloud complexity has made software delivery challenging. But the transition to SRE maturity is not always easy.
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering. like they would do in a Jupyter notebook.
There are a few qualities that differentiate average from high performing softwareengineering organisations. In my experience, the culture is better and the results are better in orgs where engineers and architects obsess over the design of code and architecture. My experience is the opposite.
Motivation Growth in the cloud has exploded, and it is now easier than ever to create infrastructure on the fly. Groups beyond softwareengineering teams are standing up their own systems and automation. At many companies, managing cloud hygiene and security usually falls under the infrastructure or security teams.
During our initial consultations, it was clear that developers preferred prioritizing product work over security or infrastructure improvements. We were under pressure to improve our adoption numbers and decided to focus first on the setup friction by improving the developer experience and automating the onboarding process.
For a given rate-quality operating point, the DO process helps allocate bits among the various shots while maximizing an overall objective function. Additionally, the current version has some algorithmic limitations that we are in the process of improving before the official release. Krasula, A. Choudhury, S. Malfait, A.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? All ML projects are software projects. Why: Data Makes It Different.
All such automation is available while your environment is continuously enriched with additional contextual information that connects the responsible teams with your software development process. Any softwareengineer can search for monitored entities that relate to specific deployments and their respective teams.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Instead, we provide them with delightfully usable ML infrastructure that they can use to manage a project’s lifecycle. Wednesday?—?December
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. They also care about infrastructure: SREs require system visibility and incident management. The DevOps people looking end-to-end. “Then, I add a breakpoint.
We talked about the cultural and process changes in order to follow through on Bernd’s requirement of “ 1 hour Code to Production !”. To do that, Anita’s team drove innovation around a common delivery pipeline to enable developers automating operational tasks such as runbook execution to solve infrastructure problems.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. According to recent Dynatrace research , organizations expect to make software updates 58% more frequently in the coming year. What is SRE (site reliability engineering)?
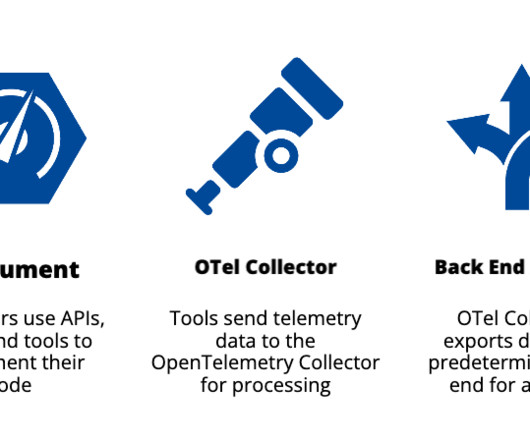
But, as Justin Scherer, senior softwareengineer from Northwestern Mutual found, OpenTelemetry by itself is not a panacea. The collector processes the data and exports it to a predetermined monitoring, tracing, or logging back end, such as Dynatrace, for analysis. What is OpenTelemetry?
Another key theme at Dynatrace Perform 2024 is organizations’ growing adoption of platform engineering , which helps accelerate the delivery of software applications. Platform engineering improves developer productivity by providing self-service capabilities with automated infrastructure operations.
In the early days of the personal computer, every computer manufacturer needed softwareengineers who could write low-level drivers that performed the work of reading and writing to memory boards, hard disks, and peripherals such as modems and printers. All of this happens through a process that Bessen calls learning by doing.
By Drew Koszewnik This is the story about how the Content Setup Engineering team used Hollow, a Netflix OSS technology, to re-architect and simplify an essential component in our content pipeline?—?delivering delivering a large amount of business value in the process. Improved debuggability and visibility into liveness processing.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes.
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering. like they would do in a Jupyter notebook.
Following our culture of freedom and responsibility , Metaflow grants data scientists the freedom to choose the right modeling approach, handle data and features flexibly, and construct workflows easily while ensuring that the resulting project executes responsibly and robustly on the production infrastructure.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Application security products and processes, however, have not kept up with advances in software development. They also do live system design discussions every week.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Application security products and processes, however, have not kept up with advances in software development. Make your job search O (1), not O ( n ). Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Who's Hiring? Apply here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content