This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now let’s look at how we designed the tracing infrastructure that powers Edgar. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage.
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
Challenges The cloud network infrastructure that Netflix utilizes today consists of AWS services such as VPC, DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc and Netflix owned devices. The choice of transport protocols like GRPC, HTTPS & UDP is runtime dependent on characteristics of the instance placement.
The importance of critical infrastructure and services While digital government is necessary, protecting critical infrastructure and services is equally important. Critical infrastructure and services refer to the systems, facilities, and assets vital for the functioning of society and the economy.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Capturing data is critical to understanding how your applications and infrastructure are performing at any given time.
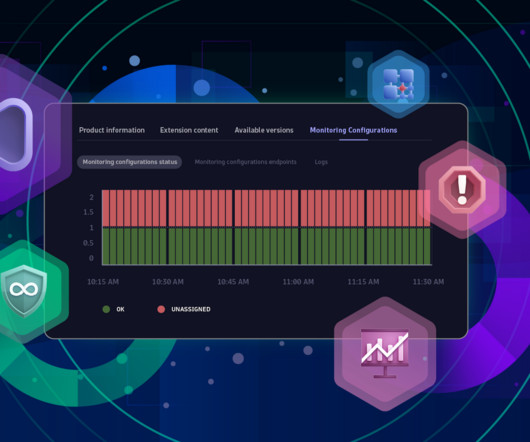
Calling it a console of transportation hubs seems reasonable, as the extension itself is only one way to get the data. Extensions bring you a load of metrics. Knowing what each metric means is crucial to selecting the most suitable ones. Monitoring configuration outages leading to metric gaps might let crucial errors slip away.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. How quickly visible parts of the page are rendered.
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
These include Source IP, destination IP, transport protocol, source port, and destination port. A full list of metrics can be found here and include dimensions such as the following: Packets. When it comes to logs and metrics, the Dynatrace platform provides direct access to the log content of all mission-critical processes.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. Just like shipping containers revolutionized the transportation industry, Docker containers disrupted software. Security is a growing area of concern for managing containers.
The Partner Infrastructure team at Netflix provides solutions to support these two significant efforts by enabling device management at scale. Together, they form the Device Management Platform, which is the infrastructural foundation for Netflix Test Studio (NTS).
Instead, we use a wrapper that pulls in the latest version of Conductor and adds Netflix infrastructure components and libraries before deployment. Below is a snapshot of our Kibana dashboard which shows the workflow execution metrics over a typical 7-day period. Cassandra persistence module is a partial implementation.
This is particularly important as we build out new functionality that relies on Pushy; a strong, stable infrastructure foundation allows our partners to continue to build on top of Pushy with confidence. Recent developments With this stable foundation and all of these connections, what can we now do with them?
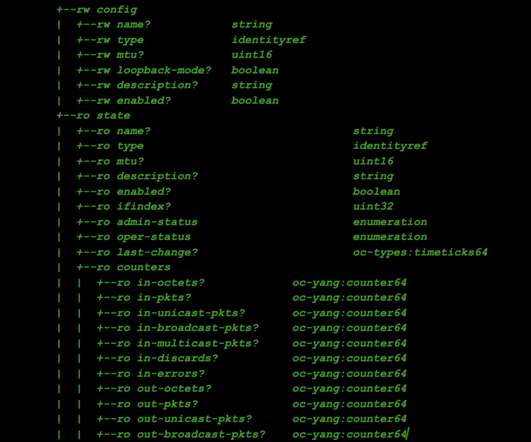
In order to design, operate, and measure these networks, we must collect metrics and state data from the thousands of devices that compose them. The mechanisms by which the data is retrieved may not be inherently reliable (in the case of SNMP’s UDP transport) and always require active polling by the collector?—?which,
Encryption at both the transport level (using SSL/TLS) and message level is crucial for safeguarding data in transit and at rest, ensuring confidentiality and integrity within RabbitMQ deployments. By implementing security measures at the transport and protocol levels, RabbitMQ ensures robust safeguards are in place.
Data Mesh provides a drag-and-drop, self-service user interface for exploring sources and creating pipelines so that users can focus on delivering business value without having to worry about managing and scaling complex data streaming infrastructure.
While not quite the same experience as dining in, if you close your eyes you can almost transport yourself into your favorite haunt. The below steps give you an idea of just some of the effort, time and costs that go into building a Flow Metrics solution that can scale across your portfolio and organization: . Development Team.
Setting up clear rules for managing your cloud infrastructure is key to keeping things from getting out of hand. Adopting Infrastructure as Code (IaaC) makes transitioning to a multi-cloud architecture more efficient, allowing streamlined setup processes. Scalegrid: Your Multi-Cloud Strategy Solution ScaleGrid.io
As an online booking platform, we connect travelers with transport providers worldwide, offering bus, ferry, train, and car transfers in over 30 countries. We aim to eliminate the complexity and hassle associated with travel planning by providing a one-stop solution for all transportation needs. Core Web Vital metrics definitions.
While not quite the same experience as dining in, if you close your eyes you can almost transport yourself into your favorite haunt. The below steps give you an idea of just some of the effort, time and costs that go into building a Flow Metrics solution that can scale across your portfolio and organization: . Development Team.
Investments in infrastructure, whether public transport or IT applications, tend to lack hard numbers because they are a means to an end and not an end in themselves. We have transport to enable people to travel to work and allow goods to reach markets. In the absence of hard measures, we concoct soft ones.
In order for enterprise IT to adopt this approach, this means shifting focus away from traditional project management metrics and plans towards a lean product development mindset. Managing product better to deliver faster time-to-value to the customer (instead of focusing on internal project metrics).
Teams with this support are free to set performance budgets, do “bakeoffs” between competing approaches, and invest in performance infrastructure. This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Performance budgets keep everyone on the same.
Data Pipeline using Delta In the following sections, we are going to describe the Delta-Connector that connects to a datastore and publishes CDC events to the Transport Layer, which is a real-time data transportationinfrastructure routing CDC events to Kafka topics. In addition, we support Cassandra (multi-master).
In a winner-take-all economy where a company’s highest-paid employees can earn over 1000 times as much as the lowest paid, the absence of a commitment to employees leads to poor housing, poor school systems, poor infrastructure, and marginalized local businesses. But we can think about what a corporation’s goals really are.
LogRocket tracks key metrics, incl. Getting Ready: Planning And Metrics Performance culture, Core Web Vitals, performance profiles, CrUX, Lighthouse, FID, TTI, CLS, devices. Getting Ready: Planning And Metrics. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Quick Wins.
Paul Reed, Clean Energy & Sustainability, AWS Solutions, Amazon Web Services SUS101 | Advancing sustainable AWS infrastructure to power AI solutions In this session, learn how AWS is committed to innovating with data center efficiency and lowering its carbon footprint to build a more sustainable business. Jason OMalley, Sr.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content