This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
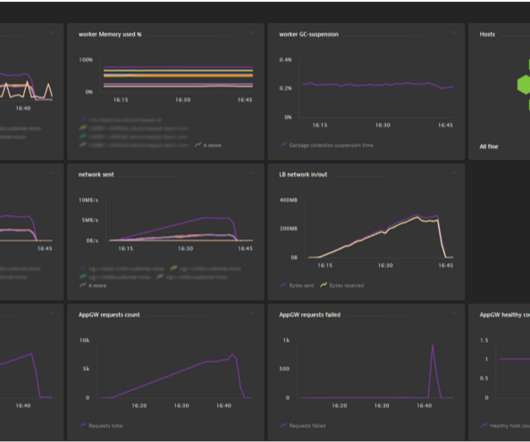
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructuremetrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
To address this, state and local governments are adopting multicloud environments to achieve the necessary speed, scale, and agility to keep up with faster digital transformation. The importance of critical infrastructure and services While digital government is necessary, protecting critical infrastructure and services is equally important.
Break data silos and add context for faster, more strategic decisions : Unifying metrics, logs, traces, and user behavior within a single platform enables real-time decisions rooted in full context, not guesswork. Generative AI enhances response speed and clarity, accelerating incident resolution and boosting team productivity.
To remain competitive in today’s fast-paced market, organizations must not only ensure that their digital infrastructure is functioning optimally but also that software deployments and updates are delivered rapidly and consistently. Continuous, informed improvement : Quality gates provide consistent feedback on key metrics.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
For organizations running their own on-premises infrastructure, these costs can be prohibitive. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. What is always-on infrastructure?
Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well. Ensure better user experience with paint-focused performance metrics. These metrics are tightly connected to the perceived load speed of your application.
Dynatrace has recently enhanced its Metrics APIs, allowing everyone to send any type of metric with any set of data dimension to Davis, Dynatrace’s AI engine. In our conversation, I mentioned the new Dynatrace Metrics ingestion and off we went. ?? There are many use cases for using this API.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
Kafkas proprietary protocol is optimized for high-speed data transfer, ensuring minimal latency and efficient message distribution. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations.
The success of an organization often depends on the quality of the on-premises or physical IT infrastructure, among other things. Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. Dynatrace news. Pool nodes. Virtual servers.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. where an error occurred at the code level.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Observability across the full technology stack gives teams comprehensive, real-time insight into the behavior, performance, and health of applications and their underlying infrastructure.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
According to the Dynatrace “2022 Global CIO Report,” 79% of large organizations use multicloud infrastructure. Moreover, organizations have to balance maintaining security, retaining cloud management expertise, and managing infrastructure performance. Rural lifestyle retail giant Tractor Supply Co.
Complexity and data volume for IT infrastructure soars to new heights. The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. Device-centric SNMP Trap overview.
The journey toward business observability Traditional IT monitoring that relies on a multitude of tools to collect, index, and correlate logs from IT infrastructure, networks, applications, and security systems is no longer effective at supporting the need of the wider organization for business insights. Operational optimization.
Effortlessly analyze IBM i Performance with the new Dynatrace extension Dynatrace has created a new version of its popular extension that is faster, offers better interactive pages, and includes more metrics, metadata, and analytics without having to install anything on your mainframe infrastructure. It’s all monitored remotely !
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. How quickly visible parts of the page are rendered.
Effective application development requires speed and specificity. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Dynatrace news.
Platform engineering creates and manages a shared infrastructure and set of tools, such as internal developer platforms (IDPs) , to enable software developers to build, deploy, and operate applications more efficiently. As a result, teams can focus on writing code and building features rather than dealing with infrastructure nuances.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. As teams try to gain insight into this data deluge, they have to balance the need for speed, data fidelity, and scale with capacity constraints and cost. Logs on Grail Log data is foundational for any IT analytics.
However, cloud infrastructure has become increasingly complex. Further, the delivery infrastructure that makes this happen has also become complex. The only way to address these challenges is through observability data — logs, metrics, and traces. Your key business objectives will drive your strategy and metrics.
These criteria include operational excellence, security and data privacy, speed to market, and disruptive innovation. “Ally continues to push the envelope to further monitor their cloud infrastructure costs. As a result, Ally is driving a new level of operational efficiency and saving millions in annual licensing costs. “We
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. Transform your operations today with the new Problems app and stay ahead in the ever-evolving software and cloud infrastructure landscape.
More recently, teams have begun to apply DevOps best practices to infrastructure automation, giving developers a more active role with GitOps as an operational framework. Key components of GitOps are declarative infrastructure as code, orchestration, and observability. Dynatrace enables software intelligence as code.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. Thus, Grail was born.
As a result, site reliability has emerged as a critical success metric for many organizations. How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of software engineering to infrastructure management, both on-premises and in the cloud. Service-level objectives (SLOs).
As they increase the speed of product innovation and software development, organizations have an increasing number of applications, microservices and cloud infrastructure to manage. Further, many organizations—more than 90%—have turned to cloud computing to navigate the highwire act of balancing speed and quality.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
This allows us to provide our services to customers with a focus on these three key pillars: Scalability : Our solution uses scalable cloud infrastructure. Each step is automated from provisioning infrastructure to problem analysis. It automatically sends JMeter metrics to the Dynatrace cluster via the Metrics Ingest API.
Observability analytics enables users to gain new insights into traditional telemetry data such as logs, metrics, and traces by allowing users to dynamically query any data captured and to deliver actionable insights. Metrics-based performance thresholds. What is observability analytics? Predictive analysis.
Application performance monitoring (APM) , infrastructure monitoring, log management, and artificial intelligence for IT operations (AIOps) can all converge into a single, integrated approach. This integrated approach represents significant time savings, drastically reducing MTTI and speeding mean time to resolution (MTTR).
To address this, many states apply for federal funding to build a security operations center to proactively defend against the growing rate of cybersecurity threats and ensure the resilience of digital infrastructure. For metrics in particular, important context includes dimensions, relationships to other metrics, and metadata.
ABlaze: The standard view of analyses in the XP UI Suppose you’re running a new video encoding test and theorize that the two new encodes should reduce play delay, a metric describing how long it takes for a video to play after you press the start button. This enables us to optimize their experience at speed. Not at Netflix.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. Learn more. Learn more.
Deploy risk-based estimates and models with confidence, accuracy, transparency, and speed. Optimize the IT infrastructure supporting risk management processes and controls for maximum performance and resilience. The IT infrastructure, services, and applications that enable processes for risk management must perform optimally.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. With Dynatrace’s full-stack monitoring capabilities, organizations can assess how underlying infrastructure resources affect the application’s performance.
The Dynatrace Software Intelligence Platform delivers precise answers about the performance of your applications, the underlying infrastructure, and the experience of your end-users. You can, for example, drive ad hoc multidimensional analysis to analyze, chart, and report on microservice-based metrics without code changes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content