This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
In today’s rapidly evolving landscape, incorporating AI innovation into business strategies is vital, enabling organizations to optimize operations, enhance decision-making processes, and stay competitive. The annual Google Cloud Next conference explores the latest innovations for cloud technology and Google Cloud.
Running workloads on top of Kubernetes is significantly valuable, not just for application teams, but for infrastructure teams as well. Control plane – updates to better understand control plane health, new dashboards (etcd, api-server, controller manager, kubelet). Get your free eBook now!
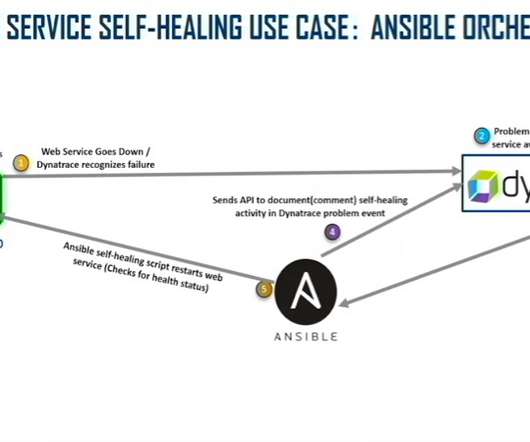
AIOps and observability for infrastructure management. This kind of IT automation “ingests data from every layer in the stack — from the infrastructure layer to the application layer and even user experience data,” says Bipin Singh, director of product marketing at Dynatrace. And then we never see these issues manifest again.
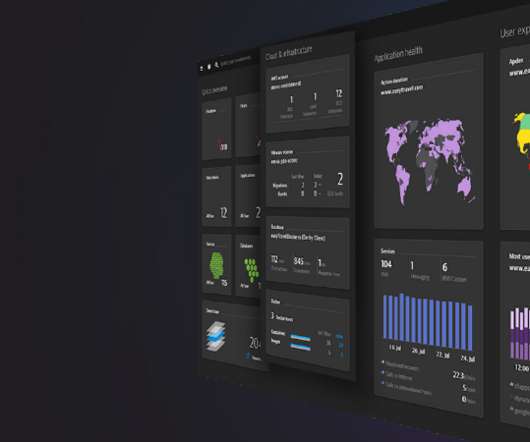
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
With this solution, customers will be able to use Dynatrace’s deep observability , advanced AIOps capabilities , and application security to all applications, services, and infrastructure, out-of-the-box. This enables organizations to tame cloud complexity, minimize risk, and reduce manual effort so teams can focus on driving innovation.
This freedom allows teams and individuals to move fast to deliver on innovation and feel responsible for quality and robustness of their delivery. All these micro-services are currently operated in AWS cloud infrastructure. In the next section, we will highlight some high level areas of focus in each dimension of our infrastructure.
Full-stack observability is fast becoming a must-have capability for organizations under pressure to deliver innovation in increasingly cloud-native environments. Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Dynatrace news.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
As organizations expand their cloud footprints, they are combining public, private, and on-premises infrastructures. But modern cloud infrastructure is large, complex, and dynamic — and over time, this cloud complexity can impede innovation. “We used Dynatrace to monitor that large increase in servers.
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. Cloud migration enables IT teams to enlist public cloud infrastructure so an organization can innovate without getting bogged down in managing all aspects of IT infrastructure as it scales.
Are all your remote file servers available? Remote file server availability. Tracking the availability of remote file servers is one of the most critical jobs as a PTC administrator – many currently do this as a manual task, downloading a file from each node. Are there any issues with your background queues?
In a Dynatrace Perform 2024 session, Kristof Renders, director of innovation services, discussed how a stronger FinOps strategy coupled with observability can make a significant difference in helping teams to keep spiraling infrastructure costs under control and manage cloud spending. ” But Dynatrace goes further.
Within every industry, organizations are accelerating efforts to modernize IT capabilities that increase agility, reduce complexity, and foster innovation. As we found in our Kubernetes in the Wild research, 63% of organizations are using Kubernetes for auxiliary infrastructure-related workloads versus 37% for application-only workloads.
Customer Conversations - How Intuit and Edmodo Innovate using Amazon RDS. From tax preparation to safe social networks, Amazon RDS brings new and innovative applications to the cloud. Empowering innovation is at the heart of everything we do at Amazon Web Services (AWS). Whats unique and innovative about your service?
Your employees are not in your central offices, your VPNs and infrastructure are stressed, and your processes may or may not be up to the task of supporting a distributed remote workforce. You have no choice but to focus on innovation, automate operations, and improve production quality. What are some other things?
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases.
Vidhya Arvind , Rajasekhar Ummadisetty , Joey Lynch , Vinay Chella Introduction At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. The KV data can be visualized at a high level, as shown in the diagram below, where three records are shown.
This automatic analysis enables engineers to spend more time innovating and improving business operations. An IT organization is often unaware a critical server has gone down until a user reports it. Each piece of the AIOps triumvirate plays a crucial role in the automation process to speed innovation.
In the first blog post of this series , we explored how the Dynatrace ® observability and security platform boosts the reliability of Site Reliability Engineers (SRE) CI/CD pipelines and enhances their ability to focus on innovation. Infrastructure layer (Kubernetes Cluster, GCP, Standalone server, etc.)
Containers are the key technical enablers for tremendously accelerated deployment and innovation cycles. Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. Docker Hub is similar in functionality to GitHub.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Log analytics also help identify ways to make infrastructure environments more predictable, efficient, and resilient. Accelerated innovation. What are logs?
An easy, though imprecise, way of thinking about Netflix infrastructure is that everything that happens before you press Play on your remote control (e.g., Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. are you logged in?
OSS is a faster, more collaborative, and more flexible way of driving software innovation than proprietary-only code. Especially those operating in critical infrastructure sectors such as oil and gas, telecommunications, and energy. Organizations also benefit from being at the leading edge of any new discoveries and innovations.
With Dynatrace for Government , you simply configure a local gateway server, set up your single sign-on (this setup will require support from our FedRAMP D ev O ps team), and deploy the automated One Agent to your physical or virtual hosts. . Minimal infrastructure cost . Works out – of – the – box .
Despite being serverless, the function still requires infrastructure on which to run. The difference is the owner of the Lambda function does not have to worry about provisioning and managing servers. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications.
As a result, organizations need software to work perfectly to create customer experiences, deliver innovation, and generate operational efficiency. However, cloud infrastructure has become increasingly complex. However, cloud infrastructure has become increasingly complex. Much of the software developed today is cloud native.
Data dependencies and framework intricacies require observing the lifecycle of an AI-powered application end to end, from infrastructure and model performance to semantic caches and workflow orchestration. million AI server units annually by 2027, consuming 75.4+ Enterprises that fail to adapt to these innovations face extinction.
AWS Fargate is the exception to this rule: with the AWS serverless compute engine, paired with Dynatrace intelligent observability for Kubernetes, customers can forgo the complex burden of managing and monitoring their own serverinfrastructure. Flexible monitoring of pods with OneAgent on EKS. and Golang containers.
It allows users to access and use shared computing resources, such as servers, storage, and applications, on demand and without the need to manage the underlying infrastructure. Finally, cloud computing enables greater collaboration and innovation. Can you expand? Explain serverless to me at a professional level.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. An application could rely on dozens or even hundreds of Lambdas and other infrastructure.
But moreover, business is the top priority; it never made sense to me to just monitor servers. Dynatrace traces end-user interactions deep into the full stack of server-side activity to understand dependencies, allowing the platform to quantify the impact, qualify the situation, and prioritize actions. See the overview on the homepage.
IBM Power servers enable customers to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Full stack observability: Gain comprehensive observability across the entire stack, including Kubernetes clusters, applications, and underlying infrastructure.
This is especially true when we consider the explosive growth of cloud and container environments, where containers are orchestrated and infrastructure is software defined, meaning even the simplest of environments move at speeds beyond manual control, and beyond the speed of legacy Security practices. And this poses a significant risk.
With role-based access control for large global teams, automatic enterprise-wide deployment and full-stack coverage across infrastructure, cloud platforms, and applications, Dynatrace is built for the most demanding enterprise environments. This means that you can spend more of your time innovating and less time configuring!
Dependency agent Installation – Maps connections between servers and processes. Combined, these integration points cover the full application stack from infrastructure monitoring to end-user experience. End-to-end distributed tracing rather than simply monitoring the uptime of servers. Available as an agent installer).
By proactively implementing digital experience monitoring best practices and optimizing user experiences , organizations can increase long-term customer satisfaction and loyalty, drive business value , and accelerate innovation. The time from browser request to the first byte of information from the server. Time to first byte.
As organizations turn to artificial intelligence for operational efficiency and product innovation in multicloud environments, they have to balance the benefits with skyrocketing costs associated with AI. Cloud-based AI enables organizations to run AI in the cloud without the hassle of managing, provisioning, or housing servers.
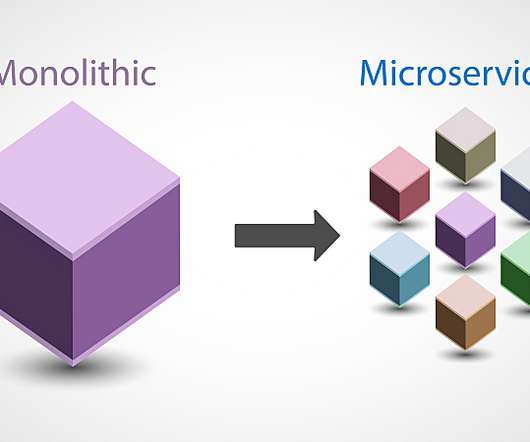
Shifting from monolith to microservices makes it easier to test, develop, and release innovative features more rapidly. C-level executives “must race to reinvent their organizations for the fast-paced, multiplied innovation world,” says Frank Gens, senior vice president and chief analyst at IDC. Server-side application.
Security vulnerabilities are weaknesses in applications, operating systems, networks, and other IT services and infrastructure that would allow an attacker to compromise a system, steal data, or otherwise disrupt IT operations. For example, an attacker could exploit a misconfigured firewall rule to gain access to servers on your network.
Without an easy way of getting answers to such questions, enterprises risk overinvesting in operations and underinvesting in development, which slows down innovation. Operations teams can leverage the same approach to improve analytics and insights into data storage, network devices, or even the room temperatures of specific server rooms.
Cloud Infrastructure Services -- An analysis of potentially anti-competitive practices by Professor Frédéric Jenny. What some consider infrastructure or platform is just another cloud service. We would still be building higher and higher on top of VMs because that's where platform innovation would have stopped evolving.
How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of software engineering to infrastructure management, both on-premises and in the cloud. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability.
Currently we have 57 Availability Zones across 19 technology infrastructure Regions. Some of the largest enterprises and public sector organizations in Italy are using AWS to build innovations and power their businesses, drive cost savings, accelerate innovation, and speed time-to-market.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content