This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Employee training in cybersecurity best practices and maintaining up-to-date software and systems are also crucial. These can be caused by hardware failures, or configuration errors, or external factors like cable cuts. Comprehensive training programs and strict change management protocols can help reduce human errors.
This means that users only pay for the computing resources they actually use, rather than having to invest in expensive hardware and software upfront. I'm sorry, but as a large language model trained by OpenAI, I don't have the ability to browse the internet or keep up-to-date with current events. Are you hosted on the cloud?
IaC, or software intelligence as code , codifies and manages IT infrastructure in software, rather than in hardware. With MLOps, data needs to be trained to understand normal behavior and what is anomalous. Unlike MLOps, AIOps doesn’t require training of data. Increased adoption of Infrastructure as code (IaC).
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. What Exactly is Greenplum?
The surprise wasnt so much that DeepSeek managed to build a good modelalthough, at least in the United States, many technologists havent taken seriously the abilities of Chinas technology sectorbut the estimate that the training cost for R1 was only about $5 million. Thats roughly 1/10th what it cost to train OpenAIs most recent models.
Use hardware-based encryption and ensure regular over-the-air updates to maintain device security. Solution: Optimize edge workloads by deploying lightweight algorithms tailored for edge hardware. Environmental costs of manufacturing and disposing of edge hardware. High costs of training and retaining talent.
For example, training on more data means more accurate models. Last re:Invent, to make the problem of authoring, training, and hosting ML models easier, faster, and more reliable, we launched Amazon SageMaker. Machine learning models are usually trained tens or hundreds of times. In machine learning, more is usually more.
First, they used a video camera and trained an AI model but then decided to use a less privacy-intrusive variant with an infrared sensor. For all the hardware geeks – here is the architectural overview of his project: Architectural overview of all involved components in his COVID-19 home innovation project. Raspberry Pi Model 3 B.
The obvious costs of tool sprawl can quickly add up, including licensing, support, maintenance, training, hardware, and often additional headcount. Additionally, the constant and rapid pace of technology innovation causes many “best-of-breed” solutions to become outdated quickly while organizations are still paying for them.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little.
The 604 tasks Gato was trained on vary from playing Atari video games to chat, from navigating simulated 3D environments to following instructions, from captioning images to real-time, real-world robotics. For example, how many training examples does it take to learn something?
As organizations train generative AI systems with critical data, they must be aware of the security and compliance risks. With the ability to generate new content—such as images, text, audio, and other data—based on patterns and examples taken from existing data, organizations are rushing to capitalize on the AI model.
Most respondents participated in training of some form. Learning new skills and improving old ones were the most common reasons for training, though hireability and job security were also factors. Company-provided training opportunities were most strongly associated with pay increases. Demographics.
My dream is to turn computer performance analysis into a science, one where we can completely understand the performance of everything: of applications, libraries, kernels, hypervisors, firmware, and hardware. Teaching others is another passion of mine – it's what drives me to write books, create training materials, and write blog posts here.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. The network devices that underlie a large portion of the CDN are mostly managed by Python applications. We also use Python to detect sensitive data using Lanius.
GPU: Graphics Processing Unit (GPU) , which achieves high data parallelism with its SIMD architecture, has played a great role in the current AI market, from training to inference. HPU: Holographic Processing Unit (HPU) is the specific hardware of Microsoft’s Hololens. FPU: Floating Processing Unit (FPU). The new GV100 packs 7.4
There is no structural separation as there is with a train service. Each cloud-native evolution is about using the hardware more efficiently. Nitro is a revolutionary combination of purpose-built hardware and software designed to provide performance and security. So why bother innovating?
Training models and developing complex applications on top of those models is becoming easier. Many of the new open source models are much smaller and not as resource intensive but still deliver good results (especially when trained for a specific application). report that the difficulty of training a model is a problem.
My involvement with clients here is usually workshops and training: teaching developers the knowledge and tooling required to effectively conduct performance audits, and making teams self-sufficient. Who: Engineers. When: During development.
As a Software Engineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language.
A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Google goes a step further in offering compute instances with its specialized TPU hardware.
sec) Conclusion These methods provide solutions for ProxySQL backups and restores, which play a pivotal role in safeguarding the integrity of your data and providing defense against various disasters, hardware malfunctions, data loss, and corruption. Reach out to us today to schedule your instructor-led class!
If you ran IBM hardware, then you ran IBM software, and that handy calendaring program that ran on Data General or Digital hardware/software was unavailable to you. You either get to pay for the privilege of having less freedom or find yourself sequestered with rapidly aging software.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. If all of this seems overwhelming or difficult to understand, our world-class MySQL Training is here to help. I hope this helps!
Uniting multidisciplinary teams of researchers and educators from 17 universities, IRIS-HEP will receive $5 million a year for five years from the NSF with a focus on producing innovative software and training the next generation of users.
everything from the frontend API for netflix.com, to machine learning training workloads, to video encoders. By Fabio Kung , Sargun Dhillon , Andrew Spyker , Kyle , Rob Gulewich, Nabil Schear , Andrew Leung , Daniel Muino, and Manas Alekar As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system.
automatic speech recognition, natural language understanding, image classification), collect and clean the training data, and train and tune the machine learning models. Effectively applying AI involves extensive manual effort to develop and tune many different types of machine learning and deep learning algorithms (e.g.
I must confess I was feeling so high and mighty about using LoadRunner, the “best” tool in the market, that it took this 3 day training to have me realize that viable alternatives existed. After this I spent almost 4 years working at Neotys, demos, proofs of concept, training people, the usual turf of a pre-sales engineer.
That meant I started having regular meetings with the hardware engineers who were working with IBM on the CPU which gave me even more expertise on this CPU, which was critical in helping me discover a design flaw in one of its instructions , and in helping game developers master this finicky beast. Standard stuff.
Deep dive into NVIDIA Blackwell Benchmarkswhere does the 4x training and 30x inference performance gain, and 25x reduction in energy usage comefrom? The first benchmark claim is 4x for training performance vs. H100, rather than the 2.5x The over-all 4x training speedup claim seems plausible for large configurations.
Ops: "Sorry, 3-5 month lead time on DC hardware and our switches are near capacity" - coming soon to an on-prem "serverless" project near you. Peter : DARPA foresee a third one in which context-based programs are able to explain and justify their own reasoning.
Much of the code ChatGPT was trained on implemented those dark patterns. This came home to me vividly when I read a paper that outlined how when ChatGPT was asked to design a website, it built one that included many dark patterns.
Then there was the need for separate dev, QA, and production runtime environments, each of which called for their own hardware. Are you licensed to use that training data for this specific commercial purpose? (Remember the misguided job postings that required a computer science degree?)
There were five trends and topics for 2021, Serverless First, Chaos Engineering, Wardley Mapping, Huge Hardware, Sustainability. The other continuing trend is to custom silicon, with specialized accelerators and the ARM based Graviton range from AWS, Apple’s M1 series, Tesla’s in car processor and training engines etc.
The goal here is to reduce the training times of DNNs by finding efficient parallel execution strategies, and even including its search time, FlexFlow is able to increase training throughput by up to 3.3x FlexFlow is also given a device topology graph describing all the available hardware devices and their interconnections.
The following chart breaks down features in three main areas: training and auditing, serving and deployment, and data management, across six systems. Finally, an analysis of ML research directions reveals the following arc through time: systems for training, systems for scoring, AutoML, and then responsible AI.
There is a potential benefit in reusing the hardware in place for video compression/decompression. Image decoding in hardware may not be a primary motivator, given the peculiarities of OS dependent UI composition, and architectural implications of moving uncompressed image pixels around.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
AI and MLOps Kubernetes has become a new web server for many production AI workloads, focusing on facilitating the development and deployment of AI applications, including model training. It comprises numerous organizations from various sectors, including software, hardware, nonprofit, public, and academic.
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. Different hardware architectures (CPUs, GPUs, TPUs, FPGAs, ASICs, …) offer different performance and cost trade-offs.
End-to-end tests can often include hardware. If this is the case, request hardware units as early as possible to avoid any delays in testing due to supply issues. It has an abundance of training tutorials and documentation. Cypress – Cypress is also an open-source tool for end-to-end testing of web applications.
Andrew Ng , Christopher Ré , and others have pointed out that in the past decade, we’ve made a lot of progress with algorithms and hardware for running AI. Our current set of AI algorithms are good enough, as is our hardware; the hard problems are all about data. Was it trained using biased, unfair data? Is retraining needed?
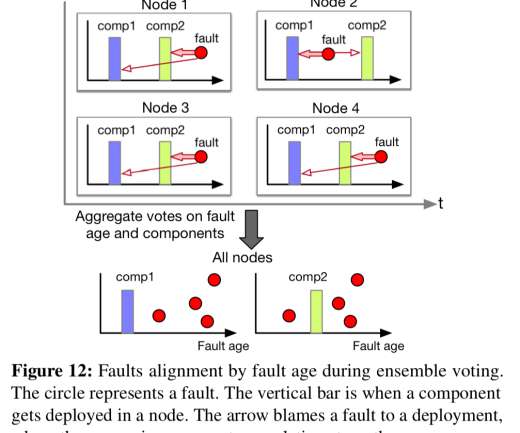
memory leaks that take hours to build up into an issue); and there can be problems that only exhibit themselves with certain user, hardware, or software configurations. Ambient faults due to e.g. hardware faults, network timeouts, and gray failures are occurring all the time, and many of these are unrelated to deployments.
We also provided web-based training, self-paced labs, customer support, third-party offers, and up to $100,000 in AWS service credits–all at no charge. If the solution works as envisioned, Telenor Connexion can easily deploy it to production and scale as needed without an investment in hardware.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content