This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
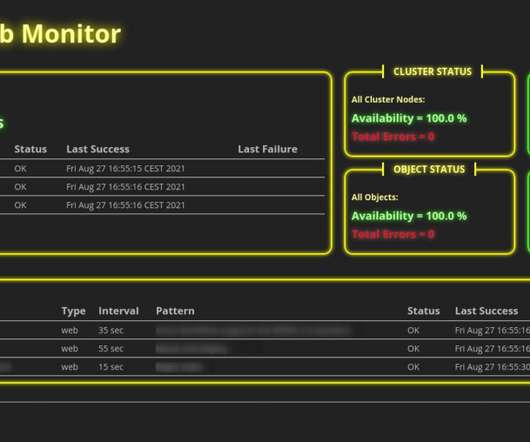
For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. One prominent solution is the open-source tool Nagios which allows you to monitor hardware in every detail.
Turnkey cluster overload protection with adaptive traffic management and control. A Dynatrace Managed cluster may lack the necessary hardware to process all the additional incoming data. The new ALR algorithm gives you more precise AI answers and optimized hardware utilization. All this automatically and with the same hardware.
Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Minimized cross-data center network traffic. Save on costs for hardware and network bandwidth to optimize total cost of ownership. Automatic recovery for outages for up to 72 hours.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Containers can be replicated or deleted on the fly to meet varying end-user traffic.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Finally, observability helps organizations understand the connections between disparate software, hardware, and infrastructure resources.
When we wanted to add a location, we had to ship hardware and get someone to install that hardware in a rack with power and network. Hardware was outdated. Fixed hardware is a single point of failure – even when we had redundant machines. Keep hardware and browsers updated at all times. Sound easy?
We had some fun getting hardware figured out, and I used a 3D printer to make some cases, but the whole project was interrupted by the delivery of the iPhone by Apple in late 2007. We simply didnt have enough capacity in our datacenter to run the traffic, so it had to work.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
Resource consumption & traffic analysis. Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This can result in significant cost savings for high traffic applications.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models.
However, performance can decline under high traffic conditions. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. Low-Latency Messaging Both Kafka and RabbitMQ are capable of low-latency messaging but use different approaches.
First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. You can see the traffic reaching each milestone of an online shopping journey. Auer outlined the key benefits of Dynatrace’s observability for e-commerce use cases and beyond. We really like how Davis works.
In modern cloud environments, every piece of hardware, software, cloud infrastructure component, container, open-source tool, and microservice generates records of every activity. Unified observability is the ability to know how systems and infrastructure are performing based on the data they generate, such as logs, metrics, and traces.
More efficient SSL/TLS handling for OneAgent traffic. By default, all OneAgent traffic is now routed to your embedded ActiveGate via NGINX on port 443. As announced with the release of Dynatrace Managed version 1.150 , we now route all incoming traffic through NGINX in an effort to increase performance and ease configuration effort.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management. They enable real-time tracking and enhanced situational awareness for air traffic control and collision avoidance systems. The ADS-B protocol differs significantly from web technologies.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. The second example was around web-server threads, which turned out that the team ran with default settings for Apache (200 worker threads) which was too low for the traffic the government agencies are receiving during business hours.
The idea CFS operates by very frequently (every few microseconds) applying a set of heuristics which encapsulate a general concept of best practices around CPU hardware use. For services, the gains were even more impressive.
The purpose of infrastructure as code is to enable developers or operations teams to automatically manage, monitor, and provision resources, rather than manually configure discrete hardware devices and operating systems. Proactively manage web and mobile applications based on user experience or traffic.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. We understand the dependencies between the mainframe, data center, and cloud, including all application components and even end-user experience.
When used in prevention mode (IPS), this all has to happen inline over incoming traffic to block any traffic with suspicious signatures. Regular expression matching is well studied, but state of the art hardware algorithms don’t reach the performance and memory targets needed for Pigasus. MPSM: First things first.
For availability, I always propose to use Dynatrace Synthetic vs looking at real user traffic. Because Synthetic tests are predictable and eliminate any seasonal behavior or impact of the end user’s environment (defect hardware, bad Wi-Fi, etc.). For our SLO the only thing we need is the default Mobile Crash Rate metric. Availability.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. Demand Engineering Demand Engineering is responsible for Regional Failovers , Traffic Distribution, Capacity Operations and Fleet Efficiency of the Netflix cloud.
Starting with version 1.170, hardware updates are applied automatically when services are restarted. An agent field is provided for enabling/disabling OneAgent traffic on individual nodes. With this change, Dynatrace Managed deployment is now more resilient and more quickly adapts to your needs.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Load balancers can detect when a component is not responding and put traffic redirection in motion.
Database operations must continue without disruption to ensure high availability, even when faced with hardware or software failures. No Test Scenario Observation 1 Network isolate the standby server from other servers Corosync traffic was blocked on the standby server. There was no disruption in the writer application.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Load balancing: Traffic is distributed across multiple servers to prevent any one component from becoming overloaded.
The goal of WebAssembly is to execute at native speeds by taking advantage of common hardware features available on a variety of platforms. With cloud-based infrastructure, organizations can easily scale their web applications to handle increased traffic or demand without the need for expensive hardware upgrades.
Recently I was engaged in a MySQL Performance Audit for a customer to help troubleshoot performance issues that led to downtime during periods of high traffic on their AWS RDS MySQL instances. The innodb_io_capacity_max parameter was set to 2000, so the hardware should be able to deliver that many IOPS without major issues.
An apples to apples comparison of the costs associated with running various usage patterns on-premises and with AWS requires more than a simple comparison of hardware expense versus always-on utility pricing for compute and storage. Making predictions about web traffic is a very difficult endeavor. Total Cost of Ownership. t need them.
The immediate (working) goal and requirements of HA architecture The more immediate (and “working” goal) of an HA architecture is to bring together a combination of extensions, tools, hardware, software, etc., Load balancing : Traffic is distributed across multiple servers to prevent any one component from becoming overloaded.
With all the resources we have today, it is easier for us to achieve fault-tolerance than it was many decades ago when computers began playing a role in critical systems such as health care, air traffic control and financial market systems. In the early days, the thinking was to use a hardware approach to achieve fault-tolerance.
This is a given, whether you are using the highest quality hardware or lowest cost components. When customers left the constraining, old world of IT hardware and datacenters behind, they started to develop systems with new and interesting usage patterns that no one had ever seen before. Primitives not frameworks. No gatekeepers.
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
After finding it cost prohibitive to use colocation centers in local markets where their users are based, iZettle decided to give up hardware. In making the switch to AWS, WOW air has saved between $30,000 and $45,000 on hardware, and software licensing. iZettle, a mobile payments startup, is also ‘all-in’ on AWS.
The daemon accepts incoming traffic from MySQL clients and forwards it to backend MySQL servers. These include runtime parameters, server grouping, and traffic-related settings. The proxy is designed to run continuously without needing to be restarted.
Vivino also uses Auto Scaling to deal with the large seasonal fluctuations in traffic. During the winter holiday season, the use of the app increases by up to 300% and AWS allows them to seamlessly scale up to cope with the increase in traffic. Telenor Connexion. Telenor Connexion is all-in on AWS.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. But we can discuss common bottlenecks, how to assess them, and have a better understanding as to why proactive monitoring is so important when it comes to responding to traffic growth.
Taiji: managing global user traffic for large-scale internet services at the edge Xu et al., It’s another networking paper to close out the week (and our coverage of SOSP’19), but whereas Snap looked at traffic routing within the datacenter, Taiji is concerned with routing traffic from the edge to a datacenter. SOSP’19.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content