This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
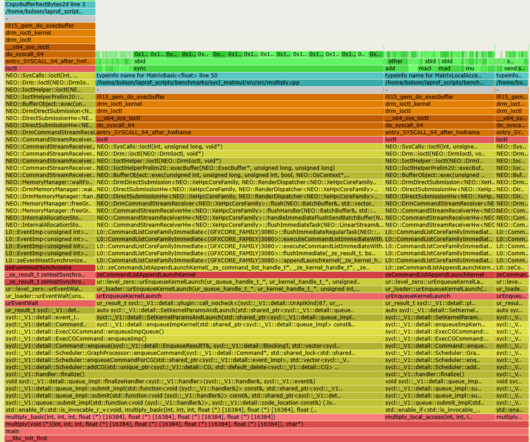
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. The x-axis is proportional to cost, so you look for the widest things and find ways to reduce them.
We do our best to provide support for all popular hardware and OS platforms that are used by our customers for the hosting of their business services. The list is constantly being updated as new releases are tested and old releases are deprecated. Behind the scenes, environment tests are performed on an ongoing basis.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions. The Encoding Technologies team took a first stab at this problem by fine-tuning the encoding recipe. Stay tuned!
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. These new applications are a great way for enterprise companies to test out PostgreSQL before migrating their entire infrastructure. Compare Ease of Use. So Which Is Best?
Christian Inzko , Performance Engineer out of our Klagenfurt Lab, is running a lot of performance tests to validate performance and scalability of our Dynatrace clusters. For some of these tests, he’s using the open source tool Apache JMeter. So stay tuned. Goal: sending metrics to Dynatrace. Raspberry Pi Model 3 B.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. Our Infrastructure Security team leverages Python to help with IAM permission tuning using Repokid. We leverage Python to protect our SSH resources using Bless.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. The initial release of OneAgent for the ARM platform with OneAgent version 1.191 is certified and tested to work on SUSE Enterprise Linux 15.x,
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. remove the dependency on the monolith after all testing is successful. create a microservice; 2.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. The optimal value can be decided after testing multiple settings, starting from eight is a good choice. If you see concurrency issues, you can tune this variable.
I am looking forward to share my thoughts on ‘Reinventing Performance Testing’ at the imPACt performance and capacity conference by CMG held on November 7-10, 2016 in La Jolla, CA. Another major trend is using multiple third-party components and services, which may be not easy to properly incorporate into testing. – Cloud.
By Benson Ma , Alok Ahuja Introduction At Netflix, hundreds of different device types, from streaming sticks to smart TVs, are tested every day through automation to ensure that new software releases continue to deliver the quality of the Netflix experience that our customers enjoy. In this blog post, we will focus on the latter feature set.
Logs can include data about user inputs, system processes, and hardware states. Whether a situation arises during development, testing, deployment, or in production, it’s important to work with a solution that can detect conditions in real-time so teams can troubleshoot issues before they slow down development or impact customers.
Perhaps the most interesting lesson/reminder is this: it takes a lot of effort to tune a Linux kernel. Google’s data center kernel is carefully performance tuned for their workloads. On the exact same hardware, the benchmark suite is then used to test 36 Linux release versions from 3.0 Headline results.
Amazon SageMaker training supports powerful container management mechanisms that include spinning up large numbers of containers on different hardware with fast networking and access to the underlying hardware, such as GPUs. Post-training model tuning and rich states. This can all be done without touching a single line of code.
Improved performance : MongoDB continually fine-tunes its database engine, resulting in faster query execution and reduced latency. You should also review your hardware resources, how you use MongoDB, and any custom configurations. We walk you through the essential steps required.
assigning to a specific CPU) is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. Then we need to see IF implementing the tuning will work or not. Currently, CPU affinity (i.e., Will this work? test4 run both to see what happen with RG.
A lot of useful information can be retrieved from this schema, for example, table metadata and foreign key relations, but trying to query I_S can induce performance degradation if your server is under heavy load, as shown in the following example test. The same tests have been executed in Percona Server for MySQL 5.7
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
Ultimately, it leads to a state where your system won’t be able to process more data even if you add more hardware. Based on this, you can go back and test different ways to write this code. Among other things, you’ll also be able to understand which thread is responsible for high allocation pressure, so stay tuned.
This approach can minimize complexities but requires complete confidence in your preparations, tests, and abilities. Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. Should I be bringing in external experts to help out?
Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Google goes a step further in offering compute instances with its specialized TPU hardware. You can download these models to use out of the box, or employ minimal compute resources to fine-tune them for your particular task.
It’s not just a simple tweak you can turn on/off; it’s a long-time process that touches almost every single item in your stack, including both hardware and software sides of the system. Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
Unexpected outcomes, security, safety, fairness and bias, and privacy are the biggest risks for which adopters are testing. Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking.
Effectively applying AI involves extensive manual effort to develop and tune many different types of machine learning and deep learning algorithms (e.g. automatic speech recognition, natural language understanding, image classification), collect and clean the training data, and train and tune the machine learning models.
These smaller distilled models can run on off-the-shelf hardware without expensive GPUs. And they can do useful work, particularly if fine-tuned for a specific application domain. Spending a little money on high-end hardware will bring response times down to the point where building and hosting custom models becomes a realistic option.
Using zswap means that no new hardware solutions are required, enabling rapid deployment across clusters. From extensive A/B testing, P was empirically determined to be 0.2%/minute. ML-based auto-tuning. The following chart shows an A/B test result for Bigtable with and without zswap enabled. min promotion rate though?
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge Steps Provisioning The first step is to provision the four nodes with both PostgreSQL and Citus. Redundancy can potentially decrease overall performance.
Instead, you want a library that is tuned for your target hardware architecture and ready for par_unseq vectorized algorithms, for blazing speed. The work ended up taking not quite an hour, including to update the repo’s own code where I’m using contracts myself in the compiler and its unit tests. This is that library.
Web performance is a broad subject, and you’ll find no shortage of performance testing tips and tutorials all over the web. Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. What is Performance Testing?
Back in 2014, I wrote an article called Performance Tuning the Whole Query Plan. Test Environment. Each test result represents the best of ten runs, with all required data and index pages in memory. Cost" column shows the optimizer's cost estimate for each query as reported on the test system. Final Thoughts.
Evaluating the total commands processed per second entails tracking server workload by observing its request-handling capabilities via different techniques such as immediate metric measurements, continuous real-time data flow using MONITOR command, or testing simulated workloads with the Redis benchmark program.
Example: Creating four simple tables to store strings but using different data types: db1 test> CREATE TABLE tb1 (id int auto_increment primary key, test_text char(200)); Query OK, 0 rows affected (0.11 sec) db1 test> CREATE TABLE tb2 (id int auto_increment primary key, test_text varchar(200)); Query OK, 0 rows affected (0.05
Well its difficult to be entirely sure however the tests have all the characteristics of tests observed previously where the CPUs are running in powersave mode. So lets take an Ubuntu system with Platinum 8280 CPUs with the following Ubuntu OS, reboot and check the CPU configuration before running any tests.
As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. There's also a test and println() in the loop to, hopefully, convince the compiler not to optimize-out an otherwise empty loop. This will slow this test a little.) But I'm not completely sure.
This allows NASA's engineers to fine-tune every aspect of the rover's behavior, optimizing for reliability rather than rapid development or ease of use. Imagine spending years meticulously planning, coding, and testing a single app. NASA's testing processes are where the real magic happens.
link] ) For the single-core case the bandwidth reported by the STREAM benchmark kernels is very close to the same as the bandwidth for the all-read tests reported here. Stay tuned! Details in the next blog entry.) The NEC Vector Engine processors provide a demonstration of very high single-core bandwidth. On a VE20B (8 cores, 1.6
Therefore, before we attempt to measure our database performance, we should know the system or cloud instance to be tested in detail. Please refer to this tuning guide to tune the system for HammerDB: Open Source Database Tuning Guide on 3rd Generation Intel® Xeon® Scalable Processors Based Platform. 4.22 %usr 38.40
Selenium , the first tool for automated browser testing (2004), could be programmed to find fields on a web page, click on them or insert text, click “submit,” scrape the resulting web page, and collect results. But the core of the process is simple, and hasn’t changed much since the early days of web testing. What’s required?
Depending on the configuration, one can tune a hardware RAID for either performance or redundancy. Now let’s stretch our imagination and consider a second method of high availability, ala Citus. The best way to describe the Citus way of doing things is to reflect how data is managed by a disk RAID array.
A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable. If tuned for performance, there is a good change reliability is compromised - and vice versa. Testing Hell Testing and quality assurance with data pipeline is a nightmare.
Not all back-end errors affect the user experience, but keeping track of them can prove helpful when tuning your app. Monitoring errors on the front-end requires a bit more work because front-end performance is highly dependant on the user’s hardware, software and connection. Manual Testing 5.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content