This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. What is RabbitMQ? This allows Kafka clusters to handle high-throughput workloads efficiently.
In this article, we explain why you should pay attention to when building a scalable application. What Is Application Scalability? Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Scalability. PostgreSQL offers free scalability, and can scale up to millions of transactions per seconds. Oracle Enterprise is recommended for high workloads which are highly scalable, but costly. PostgreSQL.
At AWS, we continue to strive to enable builders to build cutting-edge technologies faster in a secure, reliable, and scalable fashion. While building Amazon SageMaker and applying it for large-scale machine learning problems, we realized that scalability is one of the key aspects that we need to focus on.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Some cloud providers also offer specialized instances for database workloads, which may provide additional features and optimizations for performance and scalability.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. However, the move to microservices comes with its own challenges and complexities.
MongoDB is a dynamic database system continually evolving to deliver optimized performance, robust security, and limitless scalability. Sharded time-series collections for improved scalability and performance. You should also review your hardware resources, how you use MongoDB, and any custom configurations. In MongoDB 6.x:
This is why threads are often the source of scalability as well as performance issues. Use case #1: Identify scalability issues. A scalable architecture needs to distribute work across many threads in order to facilitate all the CPUs of a physical or virtual machine. Dynatrace news.
Werner Vogels weblog on building scalable and robust distributed systems. s fast and easy scalability can be quickly applied to building high scale applications. This allows us to tune both our hardware and our software to ensure that the end-to-end service is both cost-efficient and highly performant. Comments ().
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post.
We started with Amazon Dynamo, a simple key-value store that was built to be highly available and scalable to power various mission-critical applications in Amazon’s e-commerce platform. For DynamoDB, our primary focus was to build a fully-managed highly available database service with seamless scalability and predictable performance.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. Setup The setup consists of creating 10K tables with sysbench and adding 20 FKs to 20 tables.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
Flexibility and scalability Open source databases provide much greater flexibility regarding customization and configuration. Are you looking to enhance performance, improve scalability, cut expenses, or gain access to specific features you don’t currently have? Start by identifying the reasons driving the migration.
It comprises numerous organizations from various sectors, including software, hardware, nonprofit, public, and academic. This fully automated scaling and tuning will enable a serverless-like experience in our Operators and Everest. Developers will receive the endpoint without needing to consider resources and tuning at all.
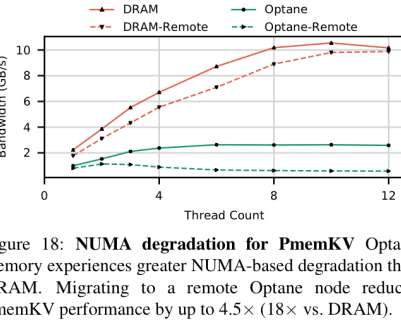
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., The Optane DIMM is the first scalable, commercially available NVDIMM. EWR is the ratio of bytes issue by the iMC divided by the number of bytes actually written to the 3D-XPoint media (as measured by the DIMM’s hardware counters).
Flexible location : Data files can reside within the MySQL data directory or an independent location, enabling finer control over storage management and performance tuning. In order to maximize their benefits, remember to carefully consider your specific needs and workload characteristics before implementing general tablespaces.
The data shape will dictate capacity planning, tuning of the backbone, and scalability analysis for individual components. These requirements impose strong scalability and resilience implications. It enables unbounded scalability as more commodity or specialized hardware can be seamlessly added to existing clusters.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. driver: intel_pstate CPUs which run at the same hardware frequency: 0 . hardware limits: 1000 MHz - 3.80 hardware limits: 1000 MHz - 3.80 current CPU frequency: Unable to call hardware .
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Quantitative performance testing looks at metrics like response time while qualitative testing is concerned with scalability, stability, and interoperability.
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. In other words, whether the workload is dominated by reads or writes. Why should you care?
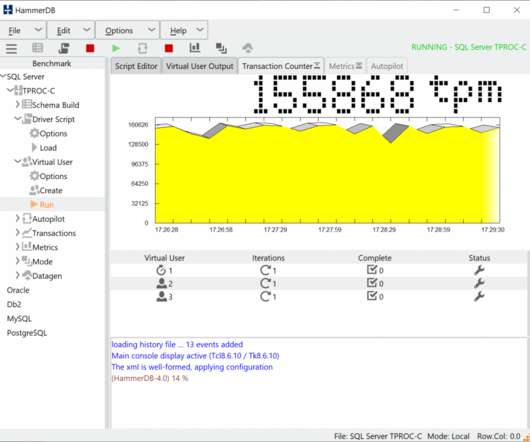
Scalability. As the chart shows because we know that both HammerDB and the implementation of the TPC-C workload scales then we can determine that with this particular database engine both the software and hardware scales as well. That is why we run a workload designed exactly for this purpose as it gives us a “benchmark” 2.
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Scalability. Benefits of a Serverless Model.
However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. This is possible because the Tcl interpreter is exceptionally compact and lightweight (Also for this reason Tcl is often used as an embedded language in hardware such as Cisco Routers).
This means that multiple partitions can be processed simultaneously, making better use of available hardware resources and further enhancing query performance. Enhanced Scalability : Partitioning enhances the database’s ability to scale, as data can be distributed across different storage devices.
Christian Inzko , Performance Engineer out of our Klagenfurt Lab, is running a lot of performance tests to validate performance and scalability of our Dynatrace clusters. So stay tuned. If you want to replicate Christians work – here are the software and hardware specs: Hardware. Goal: sending metrics to Dynatrace.
Once established, chaos engineering becomes an effective way to fine tune service-level indicators and objectives, improve alerting, and build more efficient dashboards, so you know you are collecting all the data you need to accurately observe and analyze your environment. Controlling the chaos.
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. We had specializations in hardware, operating systems, databases, graphics, etc.
ReadFile WriteFile ReadFileScatter WriteFileGather GetOverlappedResult For extended details on the 823 error, see Error message 823 may indicate hardware problems or system problems ( [link] i crosoft.com/default.aspx?scid=kb Contact your hardware manufacture for assistance.
For highly scalable services, going outside of java process is costly, even to go to Memcache or Redis so we do in-memory cache with varying TTL for some highly used data structures like access control computation, feature flags, routing metadata etc. How are software and hardware upgrades rolled out? MySQL and Redis.
Learn how remote sensing, Internet of Things, and AI technologies on AWS can be used to detect and quantify methane sources, offering a cost-effective and efficient approach to scalable environmental monitoring. It’s possible to get energy data in real time from NVIDIA GPUs (because NVIDIA provides it) but not from AWS hardware.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content