This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To achieve this level of performance, such systems require dedicated CPU cores that are free from interruptions by other processes, together with wider system tuning. In modern production environments, there are numerous hardware and software hooks that can be adjusted to improve latency and throughput.
You may also like: How to Properly Plan JVM Performance Tuning. While Performance Tuning an application both Code and Hardware running the code should be accounted for. Ensure there is enough RAM to hold your java process. Swapping java process to disk is a performance killer. Avoid Swapping to Disk.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. REST APIs, authentication, databases, email, and video processing all have a home on serverless platforms. The Serverless Process.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
Proper setup involves creating a configuration process that accounts for hostname changes, which could prevent nodes from rejoining the cluster. Message load balancing guarantees that messages are processed evenly across different queues and nodes within the RabbitMQ system. Erlang is the backbone of RabbitMQ clustering.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. of PostgreSQL users are currently in the process of migrating to the RDBMS, according to the 2019 PostgreSQL Trends Report , an astounding percentage considering this is the 4th most popular database in the world.
We have now moved to a more systematic approach where unknown errors are fed into a Machine Learning process that performs clustering to propose new regular expressions for commonly occurring errors. In the future, we are looking to automate this process. Expand Pensive with Machine Learning classifiers.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. You can find out which functions experience the highest failure rate or processing time and which of them are executed the most. So stay tuned!
Logs can include data about user inputs, system processes, and hardware states. Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded. Log analytics is the process of evaluating and interpreting log data so teams can quickly detect and resolve issues.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Network measurements with per-interface and per-process resolution. Network metrics are also collected for detected processes.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices.
In this post, we will discuss some important kernel parameters that can affect database server performance and how these should be tuned. SHMMAX is a kernel parameter used to define the maximum size of a single shared memory segment a Linux process can allocate. A page is a chunk of RAM that is allocated to a process.
With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. You can find out which functions experience the highest failure rate or processing time and which of them are executed the most. So stay tuned!
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. As datasets continue to grow in size, the amount of RAM required to store and process these datasets also increases. Refer to innodb_redo_log_capacity below.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post.
Bill Simmons, CTO of Dataxu, states, "We process 3 million ad requests a second - 100,000 features per request. In other words, processing the 10th gigabyte and 1000th gigabyte is conceptually the same. To seamlessly switch between CPU and GPU machines, we use Apache MXNet to interface with the underlying hardware.
Upgrading to the newest release of MongoDB is the key to unlocking its full potential, but it’s not as simple as clicking a button; it requires meticulous planning, precise execution, and a deep understanding of the upgrade process. You should also review your hardware resources, how you use MongoDB, and any custom configurations.
Perhaps the most interesting lesson/reminder is this: it takes a lot of effort to tune a Linux kernel. Google’s data center kernel is carefully performance tuned for their workloads. On the exact same hardware, the benchmark suite is then used to test 36 Linux release versions from 3.0 Headline results.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
It’s not just a simple tweak you can turn on/off; it’s a long-time process that touches almost every single item in your stack, including both hardware and software sides of the system. Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
assigning to a specific CPU) is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. Good examples are: ETL processes for data archiving, reporting, data consolidation and so on. Currently, CPU affinity (i.e., What is the possible usage?
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
Ultimately, it leads to a state where your system won’t be able to process more data even if you add more hardware. Now, let’s look at a Cassandra process group and see if we can find any CPU-hungry threads and thread groups. Such behavior not only limits speed but also your ability to increase throughput by adding resources.
These smaller distilled models can run on off-the-shelf hardware without expensive GPUs. And they can do useful work, particularly if fine-tuned for a specific application domain. Spending a little money on high-end hardware will bring response times down to the point where building and hosting custom models becomes a realistic option.
It’s a complex process involving various factors and meticulous planning. Today, we’ll be taking a deep dive into the intricacies of database migration, along with specific solutions to help make the process easier. Evaluating your hardware requirements is another vital aspect of resource allocation.
Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Google goes a step further in offering compute instances with its specialized TPU hardware. You can download these models to use out of the box, or employ minimal compute resources to fine-tune them for your particular task.
Most organizations are embracing DevSecOps, a term that covers processes and tooling enabling security to be integrated into the application development life cycle rather than treated as a separate process. It comprises numerous organizations from various sectors, including software, hardware, nonprofit, public, and academic.
Users and Nonusers AI adoption is in the process of becoming widespread, but it’s still not universal. Until AI reaches 100%, it’s still in the process of adoption. Automating the process of building complex prompts has become common, with patterns like retrieval-augmented generation (RAG) and tools like LangChain.
System’s configuration is not given anymore and often can’t be easily mapped to hardware. As already mentioned, performance testing is rather a performance engineering process (with tuning, optimization, troubleshooting and fixing multi-user issues) eventually bringing the system to the proper state rather than just testing.
Snap’s architecture is a composition of recent ideas in user-space networking, in-service upgrades, centralized resource accounting, programmable packet processing, kernel-bypass, RDMA functionality, and optimized co-design of transport, congestion control and routing. It reminds me of ZeroMQ. Snap’s control plane is orchestrated via RPCs.
About the cluster Following a step-by-step process, the objective is to create a four-node cluster consisting of: PostgreSQL version 15 Citus extension (I’ll be using version 11, but there are newer ones available.) psql pgbench <<_eof1_ qecho adding node citus3.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. This plays a crucial role in supervising the replication process.
There seems to be broad agreement that hyperautomation is the combination of Robotic Process Automation with AI. We’ll see it in the processing of the thousands of documents businesses handle every day. We can certainly apply the slogan to many, if not all, clerical tasks–and even to the automation process itself.
Using zswap means that no new hardware solutions are required, enabling rapid deployment across clusters. ML-based auto-tuning. This model is used by a Gaussian Process (GP) Bandit machine learning model to guide the parameter search towards an optimal point with a minimal number of trials.
Flexible location : Data files can reside within the MySQL data directory or an independent location, enabling finer control over storage management and performance tuning. mysql> SHOW VARIABLES LIKE 'innodb_directories'; + --+ -+ | Variable_name | Value | + --+ -+ | innodb_directories | | + --+ -+ 1 row in set (0.00
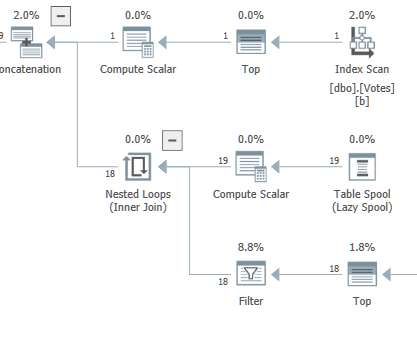
Back in 2014, I wrote an article called Performance Tuning the Whole Query Plan. The Sort only has 19 rows to process, so it consumes only 1ms or so. The parallel column store aggregate push down result of 57 million rows processed in 7ms (using 40ms of CPU) is remarkable, especially considering the hardware.
We live in the era of the connected experience, where our daily interactions with the world can be digitized, collected, processed, and analyzed to generate valuable insights. Accumulating all this data to process overnight is not an option anymore. Do we need to process each record individually? Process tolerance.
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g., Stay tuned! This post is about a secondary performance characteristic — sustained memory bandwidth for a single thread running on a single core.
This allows NASA's engineers to fine-tune every aspect of the rover's behavior, optimizing for reliability rather than rapid development or ease of use. They employ rigorous development processes, including multiple layers of review and testing that would make most software companies' heads spin.
Compression: Compression is the process of restructuring the data by changing its encoding in order to store it in fewer bytes. With hardware being more powerful and cheaper, and the technology evolving, now it is easier than ever to manage large tables in MySQL. 1 mysql mysql 592K Dec 30 02:48 tb1.ibd ibd -rw-r --. ibd -rw-r --.
There's also a ZFS send/recv code path that should try to use the TASK_INTERRUPTIBLE flag (as suggested by a coworker), to avoid a kernel hang (can't kill -9 the process). On Linux, containers are a combination of namespaces (restricting what a process sees) and cgroups (similar to Solaris resource controls). amazon").
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content