This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable.
We had some fun getting hardware figured out, and I used a 3D printer to make some cases, but the whole project was interrupted by the delivery of the iPhone by Apple in late 2007. I wonder if any of my code is still present in todays Netflixapps?)
In modern cloud environments, every piece of hardware, software, cloud infrastructure component, container, open-source tool, and microservice generates records of every activity. Observability also presents the information in highly consumable ways that enable teams to detect and resolve issues before they impact end users or customers.
However, performance can decline under high traffic conditions. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. Low-Latency Messaging Both Kafka and RabbitMQ are capable of low-latency messaging but use different approaches.
The idea CFS operates by very frequently (every few microseconds) applying a set of heuristics which encapsulate a general concept of best practices around CPU hardware use. We are working on multiple fronts to extend the solution presented here. For services, the gains were even more impressive.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. The second example was around web-server threads, which turned out that the team ran with default settings for Apache (200 worker threads) which was too low for the traffic the government agencies are receiving during business hours.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Load balancers can detect when a component is not responding and put traffic redirection in motion.
We need to be able to easily determine what imagery is present for a given platform, region, and language. However, it would be cost-inefficient to leverage this same hardware for lightweight and more consistent traffic patterns that an asset management service requires. The imagery needs to be localized.
That meant I started having regular meetings with the hardware engineers who were working with IBM on the CPU which gave me even more expertise on this CPU, which was critical in helping me discover a design flaw in one of its instructions , and in helping game developers master this finicky beast. Standard stuff.
Let’s take a look at how to get the benefits you need while spending less, based on the recommendations presented by Dani Guzmán Burgos, our Percona Monitoring and Management (PMM) Tech Lead, on this webinar (now available on demand) hosted in November last year. vacuumdb is a utility for cleaning a PostgreSQL database.
s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Consistency. SimpleDBâ??s
Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity. By implementing data abstraction techniques, these challenges can be addressed more effectively.
The layers of platforms start at the bottom with hardware choices such as which CPU architectures and vendors you want to use. The next layer is operating system platforms, what flavor of Linux, what version of Windows etc.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
In the past analytics within an organization was the pinnacle of old style IT: a centralized data warehouse running on specialized hardware. The City of Chicago is one of the first to bring sensors throughout the city that will permanently measure air quality, light intensity, sound volume, heat, precipitation, wind and traffic.
Websites are now more than just the storage and retrieval of information to present content to users. Hardware resources. Monitoring of the network for the applications using the network, traffic, and bandwidth allocations can improve the network latency. Present-day applications make more much use of the database.
Understanding Multi-Cloud and Hybrid Cloud Cloud computing has revolutionized the IT industry, offering a host of advantages including cost-effectiveness, increased agility, and access to cutting-edge hardware. Challenges of Multi-Cloud Although multi-cloud has its benefits, it also presents some obstacles. But what do these entail?
Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. And that brings our story to the present day: Stage 3: Neural networks High-end video games required high-end video cards. Google goes a step further in offering compute instances with its specialized TPU hardware.
Unfortunately, using certain open source database software as part of an HA architecture can present significant challenges. Despite all its upside, PostgreSQL software presents such challenges. Can you afford the necessary hardware, software, and operational costs of maintaining a PostgreSQL HA solution?
Hardware Past As Performance Prologue. This 2GiB RAM, Android 9 stalwart features the all-too classic lines of a Quad-core A53 (1.4GHz, small mercies) CPU, tastefully presented in a charming 5.5" But the hardware future is not evenly distributed, and web workloads aren't heavily parallel. So what did $150USD fetch in 2019?
Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. Evaluating your hardware requirements is another vital aspect of resource allocation. Look closely at your current infrastructure (hardware, storage, networks, etc.)
A three-tier system is a software application architecture that consists of a presentation layer, application layer, and data, or core, layer. Software and hardware components are autonomous and execute tasks concurrently. It is also one of the four golden signals of monitoring, which also includes traffic, error, and saturation.
Meanwhile, on Android, the #2 and #3 sources of web traffic do not respect browser choice. On Android today and early iOS versions, WebViews allow embedders to observe and modify all network traffic (regardless of encryption). Hardware access APIs, notably: Geolocation. Basic navigation and window management features to (e.g.
Understanding Redis Performance Indicators Redis is designed to handle high traffic and low latency with its in-memory data store and efficient data structures. It’s important to note that recommended throughput levels may vary depending on factors such as operating system type, network bandwidth availability, and hardware quality.
Lighthouse records metrics from the browser, applies a scoring model to them, and presents an overall performance score. It’s time to come to terms that your customers aren’t using the same powerful hardware as you. An excellent substitute for using a real device is to use Chrome DevTools hardware emulation mode. In PageSpeed 5.0,
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. But I'm not completely sure.
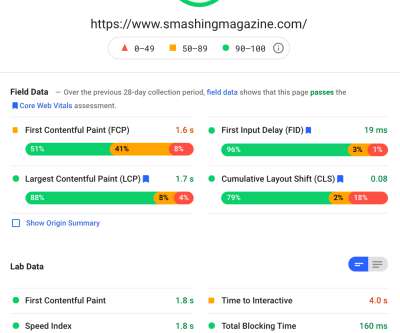
Simply enter the URL you want an audit on and click Analyze, and a few seconds later you will be presented with two tabs (one for mobile and one for desktop) that contain a wealth of information: Example screenshot of PageSpeed Insights audit ( Large preview ). At the top is the big Lighthouse performance score out of 100.
Infrastructure as a Service is the term used for those cloud-based solutions that provide complete infrastructure to the users including all the overheads, hardware, and networking facilities. SaaS does not need you to manage hardware or other requirements such as OS and middleware. Infrastructure as a Service (IaaS).
This discussion focuses on hardware, software and operational failure modes. When there’s three ways to succeed, we still have two ways to succeed when a failure is present, and if data is corrupted, we can tell which of the three is the odd one out. There is no need to retry and no extra time taken when a failure is present.
This discussion focuses on hardware, software and operational failure modes. When there’s three ways to succeed, we still have two ways to succeed when a failure is present, and if data is corrupted, we can tell which of the three is the odd one out. There is no need to retry and no extra time taken when a failure is present.
Linux has been adding tracing technologies over the years: kprobes (kernel dynamic tracing), uprobes (user-level dynamic tracing), tracepoints (static tracing), and perf_events (profiling and hardware counters). Just from a quick search, see this presentation PDF , which digs into oops message components.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
This allows MongoDB to scale horizontally, handling large datasets and high traffic loads. In MongoDB, sharding is achieved by creating shards, each of which contains a subset of the data, which are then distributed across multiple machines in a cluster, with each machine hosting one or more shards.
Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. But I'm not completely sure.
In general terms, here are potential trouble spots: Hardware failure: Manufacturing defects, wear and tear, physical damage, and other factors can cause hardware to fail. heat) can damage hardware components and prompt data loss. Human mistakes: Incorrect configuration is an all-too-common cause of hardware and software failure.
Testing shows that by using the Fua bit with the data, write request can reduce the I/O traffic by ~50% for a SQL Server, write-intensive workload. The repeated use of a write request followed by a flush request may be detrimental to performance and will increase traffic on the I/O bus. Starting with the Linux 4.18 4 Socket, TPCC.
This saves clients traffic — sometimes traffic which the client is paying for. All of this means that it will be more costly because of the growing hardware requirement and a little bit faster. Let’s assume that you’ve decided to develop a library and publish it to NPM. nature you will have full-weight Node.js
In reality, these are actually TLS features that were already present in some form in TLS 1.2 Many network interface controllers (NICs) even have built-in hardware-offload features for TCP. We can also expect QUIC-specific hardware to become available. and are now fully fledged in TLS 1.3.
For Mac OS, we can use Network Link Conditioner , for Windows Windows Traffic Shaper , for Linux netem , and for FreeBSD dummynet. On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Lighthouse , a performance auditing tool integrated into DevTools.
For Mac OS, we can use Network Link Conditioner , for Windows Windows Traffic Shaper , for Linux netem , and for FreeBSD dummynet. On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Lighthouse , a performance auditing tool integrated into DevTools.
Presenting The Case For Sustainability. Being able to present a business case, and demonstrate that the benefits outweigh the costs, will help justify focusing resources in the area of sustainability. Terabyte of wasted traffic. Hardware And E-Waste. The Bigger Picture. On the Fact Sheets page, we can save approx.
CrUX generates an overview of performance distributions over time, with traffic collected from Google Chrome users. But account for the different types and usage behaviors of your customers (which Tobias Baldauf called cadence and cohorts ), along with bot traffic and seasonality effects. You can create your own on Chrome UX Dashboard.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content