This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The unstoppable rise of opensource databases. One database in particular is causing a huge dent in Oracle’s market share – opensource PostgreSQL. See how opensource PostgreSQL Community version costs compare to Oracle Standard Edition and Oracle Enterprise Edition. What’s causing this massive shift?
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. The towers are getting smaller as optimizations are added. This will become a daily tool for AI developers.
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. Advantages of migrating to opensource For many reasons mentioned earlier, organizations are increasingly shifting towards opensource databases for their data management needs.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
RabbitMQ is an open-source message broker that supports multiple messaging protocols , including AMQP, STOMP, MQTT, and RabbitMQ Streams. Apache Kafka is an open-source event streaming platform for high-volume, event-driven data processing. What is RabbitMQ? What is Apache Kafka?
We use and contribute to many open-source Python packages, some of which are mentioned below. Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. If any of this interests you, check out the jobs site or find us at PyCon.
The Android launch leveraged the open-source software decoder dav1d built by the VideoLAN, VLC, and FFmpeg communities and sponsored by AOMedia. AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions.
For some of these tests, he’s using the opensource tool Apache JMeter. A day later he came back to me as he just built, and since then also opensourced, the Dynatrace Backend Listener for JMeter ! So stay tuned. If you want to replicate Christians work – here are the software and hardware specs: Hardware.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Many organizations also find it useful to use an opensource observability tool, such as OpenTelemetry.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. If you see concurrency issues, you can tune this variable. have been released since then with some major changes. I hope this helps!
Amazon SageMaker training supports powerful container management mechanisms that include spinning up large numbers of containers on different hardware with fast networking and access to the underlying hardware, such as GPUs. Post-training model tuning and rich states. This can all be done without touching a single line of code.
We want adopters of our technology to be able to deploy their critical opensource databases and applications across any public or private cloud environment. The newly formed OpenSource AI Alliance , led by META and IBM, promises to support open-source AI.
16% of respondents working with AI are using opensource models. Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. We’ll say more about this later.)
The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. Setup The setup consists of creating 10K tables with sysbench and adding 20 FKs to 20 tables.
Finally, the most important question: Opensource software enabled the vast software ecosystem that we now enjoy; will open AI lead to an flourishing AI ecosystem, or will it still be possible for a single vendor (or nation) to dominate? These smaller distilled models can run on off-the-shelf hardware without expensive GPUs.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Google goes a step further in offering compute instances with its specialized TPU hardware. You can download these models to use out of the box, or employ minimal compute resources to fine-tune them for your particular task.
Flexible location : Data files can reside within the MySQL data directory or an independent location, enabling finer control over storage management and performance tuning. In order to maximize their benefits, remember to carefully consider your specific needs and workload characteristics before implementing general tablespaces.
ProxySQL: It is a feature-rich open-source MySQL proxy solution, that allows query routing for the most common MySQL architectures (PXC/Galera, Replication, Group Replication, etc.). MyRocks: MyRocks is a storage engine developed by Facebook and made opensource. It is available under a paid subscription.
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge A future blog will continue my exploration into Citus by scaling out pgbench into other architectures.
FSD has a sense of purpose, a planning capability, has real time agency and responds to its environment via an ego model, predicting the behavior of pedestrians and other road users, and is being tuned to drive in a very human way, so that other road users interact with it as a predicable normal driver.
As noted previously the main developer of HammerDB is an Intel employee (#IAMINTEL) however HammerDB is a personal opensource project and any opinions are my own, specific to the context of HammerDB as an independent personal project and not representing Intel. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
sysbench is a widely used open-source benchmarking tool that is designed to evaluate the performance of CPU, memory, disk I/O, and database systems. Please refer to this tuning guide to tune the system for HammerDB: OpenSource Database Tuning Guide on 3rd Generation Intel® Xeon® Scalable Processors Based Platform.
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. In other words, whether the workload is dominated by reads or writes. Why should you care?
software” rather than “hardware” in our brains). Speech recognition errors : ChatGPT’s speech recognition system (presumably based on OpenAI’s open-source Whisper model ) is very good, but it does at times misinterpret what I’m saying. would do if I were on a noisy phone connection with someone and didn’t hear them clearly.
Depending on the configuration, one can tune a hardware RAID for either performance or redundancy. Percona Distribution for PostgreSQL provides the best and most critical enterprise components from the open-source community in a single distribution, designed and tested to work together.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Google Lighthouse Google Lighthouse is a free and opensource tool that is part of the Google Chrome DevTools family. What is Performance Testing?
Not all back-end errors affect the user experience, but keeping track of them can prove helpful when tuning your app. The Google DevTools console can give you real-time feedback to help you trace the source of errors, and you can set handlers to automate exception data collection.
A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable. If tuned for performance, there is a good change reliability is compromised - and vice versa. A data pipeline can process data in a different order than they were received.
The main objective of this post is to share my experience over the past years tuning MongoDB and centralize the diverse sources that I crossed in this journey in a unique place. systemctl stop tuned $ systemctl disable tuned Dirty ratio The dirty_ratio is the percentage of total system memory that can hold dirty pages.
Note that the main developer of HammerDB is Intel employee (#IAMINTEL) however HammerDB is a personal opensource project and any opinions are specific to the context of HammerDB as an independent personal project and are not related to Intel in any way. Repeatability. can you be sure that it scales?
This is possible because the Tcl interpreter is exceptionally compact and lightweight (Also for this reason Tcl is often used as an embedded language in hardware such as Cisco Routers). Whereas within Python all threads run in a single interpreter (after acquiring the GIL) in Tcl each thread has its own copy of the interpreter.
However, TCP is typically implemented in the operating system’s (OS’) kernel, a secure and more restricted environment, which for most OSes isn’t even opensource. As such, tuning congestion logic is usually only done by a select few developers, and evolution is slow. Finally convinced?
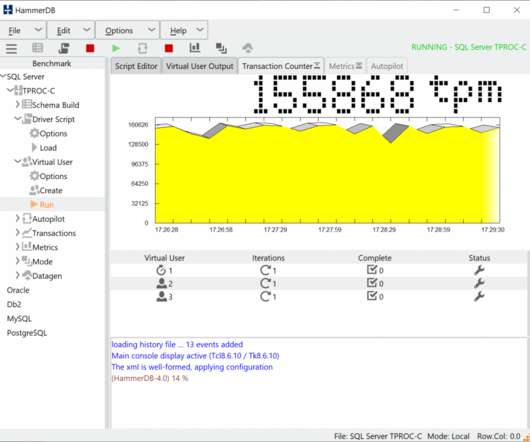
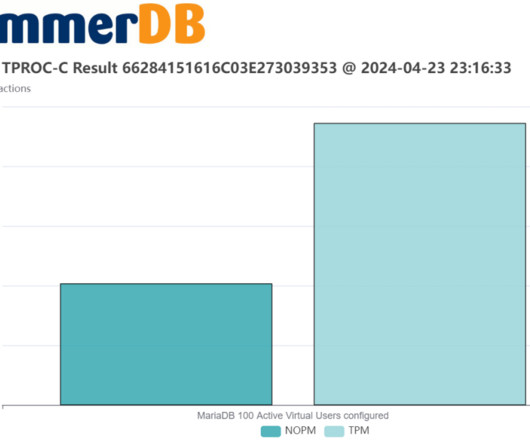
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024. Results in the 10’s of millions are not uncommon with the most advanced hardware, software and expertise.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content