This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking.
Organizations are in search of improving network agility, but what exactly does this mean? Network agility is represented by the volume of change in the network over a period of time and is defined as the capability for software and hardware component’s to automatically configure and control itself in a complex networking ecosystem.
What Are Virtual Network Functions (VNFs)? Previously, proprietary hardwareperformed functions like routers, firewalls, load balancers, etc. In IBM Cloud, we have proprietary hardware like the FortiGate firewall that resides inside IBM Cloud data centers today.
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. Now, you’ll be able to: Measure internal web page performance and availability with single-URL monitors. Scalability and load balancing.
The network latency between cluster nodes should be around 10 ms or less. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Minimized cross-data center network traffic. – A Dynatrace customer, Head of Performance Engineering.
In QA and software testing world, a compatibility test is a kind of test performed to scrutinize whether the software or app is competent of running on multiple OSs, mobile devices, browsers, applications, network environments, and more. Put simply, the compatibility of the software is checked for distinct environments and platforms.
They may stem from software bugs, cyberattacks, surges in demand, issues with backup processes, network problems, or human errors. Conducting performance testing and having contingency plans for peak times can help ensure systems remain operational during spikes in usage.
Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. Redundancy in power, network, cooling systems, and possibly everything else relevant. this is addressed through monitoring and redundancy. Again the approach here is the same.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. The primary goal of ITOps is to provide a high-performing, consistent IT environment. Performance. What does IT operations do?
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. What Exactly is Greenplum? At a glance – TLDR. Open Source.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
A lot of companies—even if they are aware that performance is key to their business—are often unsure of how, when, or where performance testing sits within their development lifecycle. To make things worse, they’re also usually unsure whose responsibility performance measuring and monitoring is.
What Is Network Agility? Network Agility — the volume of change in the network over a period of time — the capability for software and hardware components to automatically configure and control itself in a complex networking ecosystem.
This centralization means all aspects of the system can share underlying hardware, are generally written in the same programming language, and the operating system level monitoring and diagnostic tools can help developers understand the entire state of the system. 5 challenges to achieving observability at scale. Read eBook now!
It also provides information for organizations setting up high recovery mechanisms for transaction reconciliation and settlement in case of failure, as well as transaction disruption events during a network failure. The fail-over condition arises due to uncontrolled network failure, OS failure, hardware failure or DR drill.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Host-performance measures.
They’ve gone from just maintaining their organization’s hardware and software to becoming an essential function for meeting strategic business objectives. Today, IT services have a direct impact on almost every key business performance indicator, from revenue and conversions to customer satisfaction and operational efficiency.
An equally important aspect of this AI growth equation is the ever-expanding demands it places on computer system requirements to deliver higher AI performance. What’s more is that this AI performance boost driven by software optimizations is free, requiring almost no code changes or developer time and no additional hardware costs.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Here are some of the tasks orchestration platforms are challenged to perform.
Carbon Impact uses host utilization metrics from OneAgents to report the estimated energy consumption for CPU, storage I/O, memory, and network. Use DQL to perform ad-hoc analysis of energy consumption and carbon emissions Carbon Impact simplifies evaluating your carbon footprint at data center and host levels.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. This enables AIOps teams to better predict performance and security issues and improve overall IT operations. Operations analytics ensures IT systems perform as expected.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
It differentiates Dynatrace as an AWS Partner Network (APN) member with a fully tested product on AWS Outposts. “We Dynatrace can help customers monitor, troubleshoot, and optimize application performance for workloads operating on AWS Outposts, in AWS Regions, and on customer-owned hardware for a truly consistent hybrid experience.”.
Someone trying to look at the network through a 4-D lens. While ‘digital transformation’ and ‘cloud migration’ are two concepts with relatively broad definitions, they’re both rooted in the modernization of enterprise networks.
Real-time stream processing to perform live activity tracking, data cleansing, metrics generation, and more. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. The function itself performs a small unit of work and Lambda charges subscribers by the millisecond.
CPU consumption in Unix/Linux operating systems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. Let’s say your application is making network calls to external applications.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. Optimized system performance. Increased collaboration.
These metrics help to keep a network system up and running?, Mean time to recovery (MTTR) measures the entire amount of time it takes to get a downed network or system back up and running. MTTD is a primary key performance indicator for IT and DevOps teams. a critical task that’s easier said than done. Mean time to recovery.
or “How will performance be accurate if the machine is not physical?” When we wanted to add a location, we had to ship hardware and get someone to install that hardware in a rack with power and network. Hardware was outdated. Fixed hardware is a single point of failure – even when we had redundant machines.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Host-performance measures.
With Dynatrace, we follow a combination of agent and agent-less approach where the “secret sauce” lies in our Dynatrace OneAgent (watch my Performance Clinic YouTube tutorial with our Chief Software Architect Helmut Spiegl ). Which hosts not to migrate because of too much network traffic? Where to reduce data transfer in general?
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. A brownout phase performs a preparatory background transfer of all the key state to a memory region shared with the new version. SOSP’19.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases.
Open Connect Open Connect is Netflix’s content delivery network (CDN). video streaming) takes place in the Open Connect network. The network devices that underlie a large portion of the CDN are mostly managed by Python applications. If any of this interests you, check out the jobs site or find us at PyCon. are you logged in?
Before an organization moves to function as a service, it’s important to understand how it works, its benefits and challenges, its effect on scalability, and why cloud-native observability is essential for attaining peak performance. Cloud providers then manage physical hardware, virtual machines, and web server software management.
It provides a consistent platform that integrates with a variety of message queuing types to enable consistent performance regardless of the platform. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. Two styles of message queuing.
It provides a consistent platform that integrates with a variety of message queuing types to enable consistent performance regardless of the platform. Without it, sending an email over a long distance would require the immediate availability of every node on the routing network to forward each message. Two styles of message queuing.
In a monitoring scenario, teams typically preconfigure dashboards to alert about performance issues they may expect to see later. Every hardware, software, cloud infrastructure component, container, open source tool, and microservice generates records of every activity within modern environments. Observability differs from monitoring.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Host performance measures. For details on available metrics, see host performance monitoring. Disk measurements with per-disk resolution.
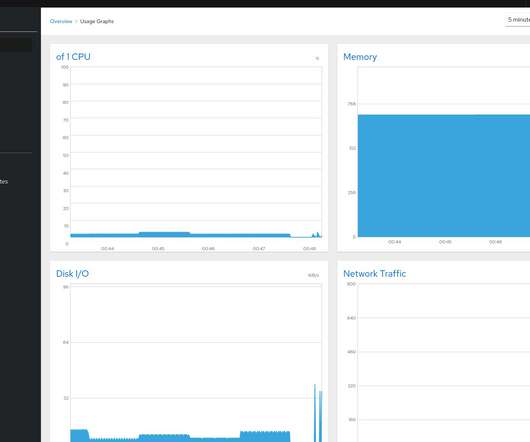
I needed basic information on RAM, CPU, Disk, Networking, and I/O to assess the performance bottleneck for the serve. " I was in the search for a straightforward tool that shows me hardware "VM" metrics and allows me to check the logs without ssh into the VM and ideally tool should be Open Source.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
We were very pleased to see that AV1 streaming improved members’ viewing experience, particularly under challenging network conditions. AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions.
However, the key insight here is that these caches are partially shared among the CPUs, which means that perfect performance isolation of co-hosted containers is not possible. Traditionally it has been the responsibility of the operating system’s task scheduler to mitigate this performance isolation problem. Linux to the rescue?
Generally, we can say that: Web services are packet sized applications that communicate with each other via network but in a precise format. Web Service and Mobile App Testing. The output of one software used as an input to another reciprocally and the whole process executed with interface language like XML.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content