This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Additional benefits of Dynatrace SaaS on Azure include: No infrastructure investment : Dynatrace manages the infrastructure for you, including automatic visibility, problem detection, and smart alerting across virtual networks, virtual infrastructure, and container orchestration.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data. Watch webinar now!
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data. The post What is a message queue?
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. Dynatrace now monitors your AWS Outposts environment just like any AWS cloud Region. Next steps.
Instead, enterprises manage individual containers on virtual machines (VMs). In FaaS environments, providers manage all the hardware. Alternatively, in a CaaS model, businesses can directly access and manage containers on hardware. Instead, CaaS solutions are often divided into different classes: Individual VM containers.
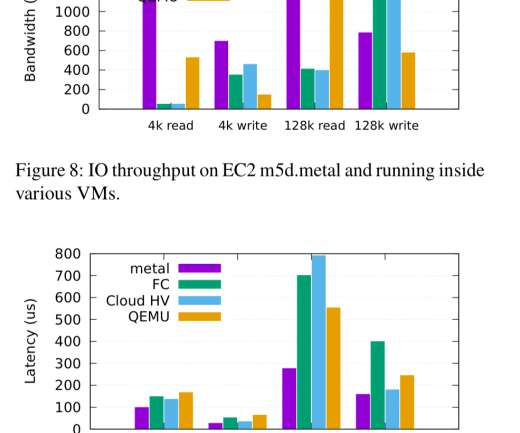
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead.
Organizations hit this cloud operations wall when replacing static virtual machines with dynamic container orchestration and expanding to multicloud environments. Today, VA uses Dynatrace to monitor over 150 different cloud instances — even hybrid instances of applications. In 48 hours, we had a total of 6,500 servers monitored.”
The purpose of infrastructure as code is to enable developers or operations teams to automatically manage, monitor, and provision resources, rather than manually configure discrete hardware devices and operating systems. In response, Dynatrace introduced Monaco (Monitoring-as-code). Register now!
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. All DBaaS management, monitoring, and maintenance tools are included in both plans, along with 24/7 support. Where to host your cloud database? Security Groups.
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Dynatrace automatically detects and monitors all your databases used by your applications and services once the OneAgent is installed. Which Database to migrate?
Setting up and monitoring these systems was pretty easy compared to today’s standards. There were no dynamic web applications or complex user scenarios to have to monitor. monitoring distributed systems becomes much more difficult to carry out and manage. Onto the next project. Gone are the days of monolithic architecture.
From one side, it makes it easier to monitor and update / rollback systems that lowers performance-related risks. The answer to this challenge is service virtualization, which allows simulating real services during testing without actual access. System’s configuration is not given anymore and often can’t be easily mapped to hardware.
When it comes to hardware support to mitigate software security issues, there is a significant gap between what is available in products today and known solutions. Acceleration—Adding hardware support to reduce the runtime overheads of security features. Also known as a “correct by construction” approach to security.
Regular monitoring, logging, and compliance with industry regulations such as PCI-DSS, HIPAA, and GDPR increase RabbitMQ security by enabling audit trails and timely incident response. The continuous security of your messaging system hinges on persistent monitoring and routine updates.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Failure detection : Monitoring mechanisms detect failures or issues that could lead to failures.
Instead of diving in arguing about specific points (which I partly did in my earlier post – start from The Future of Performance Testing if you are interested), I decided to talk to people who monetize on these “myths” So here is a virtual interview with Guillaume Betaillouloux , co-founder and Performance Director of OctoPerf.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtualhardware. Failure detection: Monitoring mechanisms detect failures or issues that could lead to failures. What is fault tolerance?
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Monitoring. Benefits of a Serverless Model.
The immediate (working) goal and requirements of HA architecture The more immediate (and “working” goal) of an HA architecture is to bring together a combination of extensions, tools, hardware, software, etc., Failure detection : Monitoring mechanisms detect failures or issues that could lead to failures.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
HA in PostgreSQL databases delivers virtually continuous availability, fault tolerance, and disaster recovery. Also, in general terms, a high availability PostgreSQL solution must cover four key areas: Infrastructure: This is the physical or virtualhardware database systems rely on to run. there cannot be high availability.
Nowadays, hardware and software are designed to conduct eye-tracking studies for marketing , UX , psychological and medical research , gaming , and several other use cases. Another area that has been showing huge potential is eye-tracking in the context of virtual reality. Source: Nielsen Norman Group ) ( Large preview ).
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. idle%-99.97
These acronyms, which stand for real user monitoring and application performance monitoring, are software monitoring processes essential to measuring and evaluating applications in many different areas. What is real user monitoring (RUM)? What is application performance monitoring (APM)?
You cannot virtualize everything…yet. Software services still require physical devices and hardware for them to function. Incident identification begins with some form of monitoring or alerting mechanism. We talked about monitoring distributed systems in a different article and how that pertains to SRE teams.
It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based. Enterprise environments are monitored, continuously profiled, and analyzed on a regular basis, so this capability will indeed be put to use.
The core idea is to continuously monitor all aspects of the business, actively interpret the observations using advanced data analysis – including ML – and integrate the learnings into appropriate actions that improve business outcomes. And there’s going to be a lot of them! Data management.
Vertical scaling is also often discussed, which involves increasing the resources of a single server, which can have limitations in hardware capabilities and become costly as demands grow. 2) Hardware limitations Disk and memory are inexpensive nowadays. An example is running MongoDB on Mesos.
That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure. These models are typically smaller (7 to 14 billion parameters) and easier to fine-tune, and they can run on very limited hardware; many can run on laptops, cell phones, or nanocomputers such as the Raspberry Pi.
It is built as part of the platform-as-a-service environment which provides customers with additional monitoring and security for the product. Fast forward a few years after Azure SQL Database was released to when Azure SQL Managed Instance was in public preview, and "vCores" (virtual cores) were announced for Azure SQL Database.
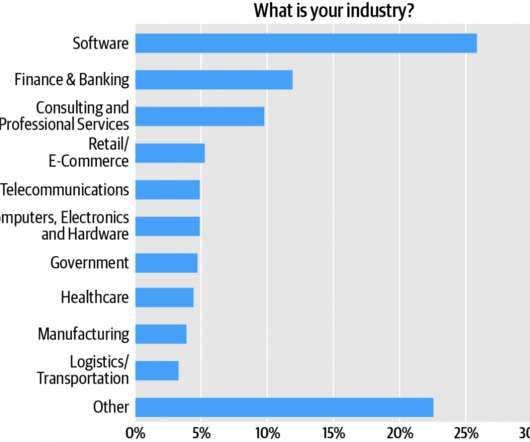
Combined, technology verticals—software, computers/hardware, and telecommunications—account for about 35% of the audience (Figure 2). So it just makes sense to instantiate microservices at the level of the virtual machine (VM), as distinct to that of the container. Figure 2: Respondent industries. The high showing for API quality—i.e.,
The scripts can be uploaded into the LoadView platform and replayed by a virtually unlimited number of simultaneous users, giving you actual performance from real browsers. Shift Right – Monitoring Performance after Deployment. Distribute user load by geographical testing locations, simulating your customer base.
By clicking on the Metrics Display option, HammerDB will connect to the target database and start monitoring the performance, note that if the pg_active_session_history table is empty the viewer will report an error and refuse to start. The example shows a TPROC-C workload running with 4 Active Virtual Users. No rows found.
Today we’ll be reviewing LoadView , an on-demand load-testing platform from Dotcom-Monitor that makes realistic load testing possible without an up-front investment in hardware or software infrastructure. Thanks to cloud-based virtual servers, LoadView can send traffic to your site or application from around the world.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. About CXL hardware availability with academia. Also, besides the hardware, we see the software ecosystem starts to appear (e.g., Using emulation (e.g.
Containerized data workloads running on Kubernetes offer several advantages over traditional virtual machine/bare metal based data workloads including but not limited to. support for logging, monitoring, and observability. In fact, if we go by current trends containerised microservices running on Kubernetes are the future.
From the maintenance and monitoring of the machines and software to upgrading and installations — you’ll need all hands on deck. More control: While performing on-premise testing, organizations have more control over configurations, setup, hardware, and software. As the name suggests, it happens on-premise.
A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable. This means despite having extensive observability and monitoring we cannot detect new problems or issues unless we go through them. A data pipeline can process data in a different order than they were received.
A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. The key aspect is the presence of the TP Monitor and this is arguably the area where the most confusion arose in stating that a HammerDB TPC-C workload was not an actual TPC-C workload which should have already been clear.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. driver: intel_pstate CPUs which run at the same hardware frequency: 0 . hardware limits: 1000 MHz - 3.80 hardware limits: 1000 MHz - 3.80 current CPU frequency: Unable to call hardware .
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content