This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. For that reason, we use monitoring tools. And there are a lot of monitoring tools available providing all kinds of features and concepts.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Minimized cross-data center network traffic. Automatic recovery for outages for up to 72 hours.
Turnkey cluster overload protection with adaptive traffic management and control. A Dynatrace Managed cluster may lack the necessary hardware to process all the additional incoming data. This is one of our self-healing solutions that enables Dynatrace to monitor your applications continuously.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Containers can be replicated or deleted on the fly to meet varying end-user traffic.
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. However, performance can decline under high traffic conditions. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Meanwhile, security analytics tools leverage behavior-based analysis to continuously monitor cloud, on-prem, and hybrid networks.
When we wanted to add a location, we had to ship hardware and get someone to install that hardware in a rack with power and network. Hardware was outdated. Fixed hardware is a single point of failure – even when we had redundant machines. Keep hardware and browsers updated at all times. Sound easy?
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. What’s included.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models. Automate IT operations.
IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management. Mining and public transportation organizations commonly rely on IoT to monitor vehicle status and performance and ensure fuel efficiency and operational safety.
First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. Auer also explained how observability data is used to deliver insights to the business, through a fully automated monitoring service. Digital experience revealed by real-user monitoring.
Resource consumption & traffic analysis. Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). Mainframe monitoring is an area of significant investment for Dynatrace. What’s included.
The purpose of infrastructure as code is to enable developers or operations teams to automatically manage, monitor, and provision resources, rather than manually configure discrete hardware devices and operating systems. Proactively manage web and mobile applications based on user experience or traffic.
The key components of automatic failover include the primary server for write operations, standby servers for backup, and a monitor node for health checks and coordination of failover events. Tools for PostgreSQL high availability include automatic failover, monitoring, replication, and user management.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Here are details of the capabilities included in this release of OneAgent for Linux on the ARM platform: Deep-code monitoring. What’s included.
In modern cloud environments, every piece of hardware, software, cloud infrastructure component, container, open-source tool, and microservice generates records of every activity. Therefore, the eyes-on-glass approach to monitoring system health just doesn’t work anymore. Observability aims to interpret them all in real time.
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This can result in significant cost savings for high traffic applications.
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Digital Experience optimization.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
Dynatrace’s Real User Monitoring (RUM) offering provides observability to every end-user that uses your mobile or web applications. For availability, I always propose to use Dynatrace Synthetic vs looking at real user traffic. In Dynatrace that’s easy: App Adoption Rate. Availability. Response time.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance. In this blog, we will explore various MySQL KPIs that are basic and essential to track using monitoring tools like PMM.
Audit logs open up a whole new set of use cases for custom notifications using log monitoring tools. Starting with version 1.170, hardware updates are applied automatically when services are restarted. Limits and overage details are included for each monitoring-unit type. Dynamic JVM memory settings update. Other improvements.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. Demand Engineering Demand Engineering is responsible for Regional Failovers , Traffic Distribution, Capacity Operations and Fleet Efficiency of the Netflix cloud.
Setting up and monitoring these systems was pretty easy compared to today’s standards. There were no dynamic web applications or complex user scenarios to have to monitor. monitoring distributed systems becomes much more difficult to carry out and manage. Onto the next project. Gone are the days of monolithic architecture.
An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. When used in prevention mode (IPS), this all has to happen inline over incoming traffic to block any traffic with suspicious signatures. IDS/IPS requirements. MPSM: First things first.
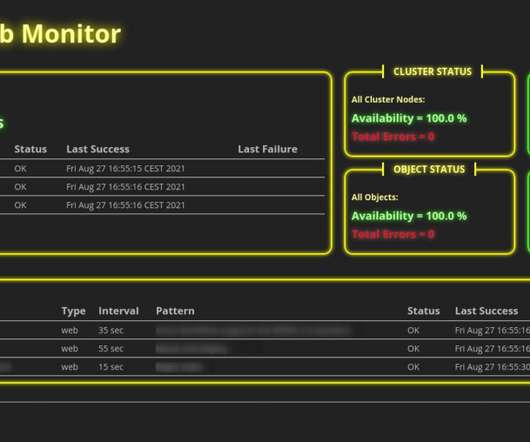
Website and Web Application Monitoring. Web monitoring is a comprehensive term that describes the activity of testing a website or web application for its availability and performance. HTTP Monitoring. HTTP monitoring allows you to test availability and performance from around the world. The list goes on and on.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Load balancers can detect when a component is not responding and put traffic redirection in motion.
ProxySQL is a high-performance SQL proxy that runs as a daemon watched by a monitoring process. The process monitors the daemon and restarts it in case of a crash to minimize downtime. The daemon accepts incoming traffic from MySQL clients and forwards it to backend MySQL servers.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. But we can discuss common bottlenecks, how to assess them, and have a better understanding as to why proactive monitoring is so important when it comes to responding to traffic growth.
The immediate (working) goal and requirements of HA architecture The more immediate (and “working” goal) of an HA architecture is to bring together a combination of extensions, tools, hardware, software, etc., Load balancing : Traffic is distributed across multiple servers to prevent any one component from becoming overloaded.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Load balancing: Traffic is distributed across multiple servers to prevent any one component from becoming overloaded.
Regular monitoring, logging, and compliance with industry regulations such as PCI-DSS, HIPAA, and GDPR increase RabbitMQ security by enabling audit trails and timely incident response. The continuous security of your messaging system hinges on persistent monitoring and routine updates.
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Monitoring. Benefits of a Serverless Model.
Vertical scaling is also often discussed, which involves increasing the resources of a single server, which can have limitations in hardware capabilities and become costly as demands grow. 2) Hardware limitations Disk and memory are inexpensive nowadays. An example is running MongoDB on Mesos.
Applications can be horizontally scaled with Kubernetes by adding or deleting containers based on resource allocation and incoming traffic demands. It distributes the load among containers and nodes automatically, ensuring that your application can handle any spike in traffic without the need for manual intervention from an IT staff.
Essentially, all traffic between China and the rest of the world goes through a few national level and a handful of core level access points in different regions. The censorship and monitoring of internet have evolved from anti-virus-like and firewall software to hardware security patches for all devices that uses internet.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
We switched to storing our game data in DynamoDB, which alleviated our scaling problems while also freeing us from the burden of managing all the underlying hardware and software. The seamless integration with the rest of the AWS infrastructure, especially CloudWatch, made real-time monitoring a cinch.â??.
Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. Evaluating your hardware requirements is another vital aspect of resource allocation. Look closely at your current infrastructure (hardware, storage, networks, etc.)
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content