This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
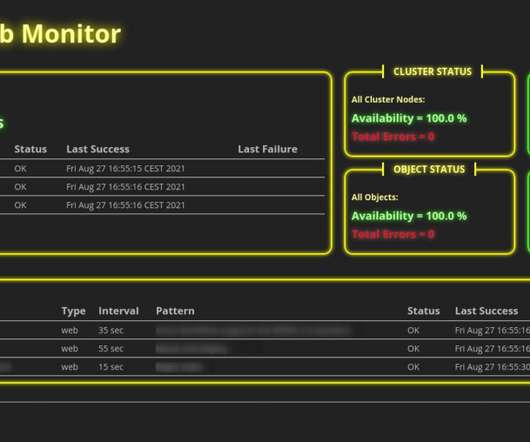
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. If your servers go down for some reason, this may not be funny for your colleagues, customer, and even for yourself. For that reason, we use monitoring tools. Introduction.
As of September 2020, we run 51 clusters on 1100 EC2 instances distributed across six AWS Regions ensuring that all our users can leverage the Dynatrace Software Intelligence Platform to monitor their hybrid-multi cloud environments. The AWS team confirmed a known hardware issue affecting a certain amount of EC2 machines in that region.
Run your own Video Conference Service with Jitsi , I started looking for a reliable solution to monitor my instance that runs Jitsi. " I was in the search for a straightforward tool that shows me hardware "VM" metrics and allows me to check the logs without ssh into the VM and ideally tool should be Open Source.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
We’re happy to announce the launch of Dynatrace Synthetic private browser monitors! We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. Monitor your internal apps from within your offices.
Serverless computing is a computing model that “allows you to build and run applications and services without thinking about servers.”. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. What’s next.
. – this is addressed through monitoring and redundancy. Hardware - servers/storage hardware/software faults such as disk failure, disk full, other hardware failures, servers running out of allocated resources, server software behaving abnormally, intra DC network connectivity issues, etc.
This means you no longer have to procure new hardware, which can be a time-consuming and expensive process. and scales up as monitoring environments grow by simply adding nodes, with built-in failover and automatic load balancing to ensure optimal resource usage.
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams.
Synthetic monitoring locations execute browser and HTTP monitors from within your own infrastructure and answer questions about the availability of applications (internal and external) from the perspective of specific points of interest such as branch offices. Dynatrace news. What’s next.
Serverless computing is a computing model that “allows you to build and run applications and services without thinking about servers.”. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. What’s next.
Serverless container offerings such as AWS Fargate enable companies to manage and modify containers while abstracting server layers to offer customization without increased complexity. IaaS provides direct access to compute resources such as servers, storage, and networks. In FaaS environments, providers manage all the hardware.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Computer operations manages the physical location of the servers — cooling, electricity, and backups — and monitors and responds to alerts. Why is IT operations important?
Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Achieve high SLOs with seamless monitoring when entire data centers experience outages.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. Performing updates, installing software, and resolving hardware issues requires up to 17 hours of developer time every week.
Having the ability to monitor the performance and availability of your organization’s internal applications—in addition to your organization’s customer-facing applications—from within your corporate network is an important benefit of synthetic monitoring. Browser monitors can now be executed from Windows-based ActiveGates.
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers. These tools help ensure proactive monitoring and quick issue resolution.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. How do AWS Lambda functions impact monitoring? What is AWS Lambda?
If the primary server encounters issues, operations are smoothly transitioned to a standby server with minimal interruption. Key Takeaways PostgreSQL automatic failover enhances high availability by seamlessly switching to standby servers during primary server failures, minimizing downtime, and maintaining business continuity.
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. What’s included.
The agency executed one of the largest email migrations from on-premises Exchange servers to Microsoft Office 365 — moving almost 480,000 mailboxes to the cloud. Today, VA uses Dynatrace to monitor over 150 different cloud instances — even hybrid instances of applications. We started out by instrumenting 2,000 servers overnight.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis, a powerful in-memory data store, is no exception.
Achieving 100 Gbps intrusion prevention on a single server , Zhao et al., Today’s paper choice is a wonderful example of pushing the state of the art on a single server. An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. OSDI’20.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. These can be caused by hardware failures, or configuration errors, or external factors like cable cuts. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Redis®, a powerful in-memory data store, is no exception.
Agricultural businesses use IoT sensors to automate irrigation systems, while mining and water supply organizations traditionally rely on SCADA to optimize and monitor water distribution, quality, and consumption. In our example, the ADS-B application provides an excellent visual representation for short-term live monitoring purposes.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). Mainframe monitoring is an area of significant investment for Dynatrace. What’s included.
IBM Power servers enable customers to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Additionally, Dynatrace integrates seamlessly with cloud-native technologies and services, such as Istio and Prometheus, further enhancing its monitoring capabilities.
Because monolithic applications combine database, client-side interfaces, and server-side application elements in a single executable, they’re difficult to understand, even for their own administrators. Security should be an integral part of each stage of the software delivery lifecycle, from development to monitoring in real time.
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Digital Experience optimization.
It allows users to access and use shared computing resources, such as servers, storage, and applications, on demand and without the need to manage the underlying infrastructure. This means that users only pay for the computing resources they actually use, rather than having to invest in expensive hardware and software upfront.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
It also entails secure development practices, security monitoring and logging, compliance and governance, and incident response. Cloud application security practices enable organizations to follow secure coding practices, monitor and log activities for detection and response, comply with regulations, and develop incident response plans.
Management of synthetic monitors using the credential vault is now easier than ever. Easily monitor your entire infrastructure with Dynatrace Synthetic monitors. Easily monitor your entire infrastructure with Dynatrace Synthetic monitors. Installation and upgrade. NGINX was updated to version 1.17.8.5
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. The following shows one of the slides I use to answer the question: What happens if I move this group of servers? For that, it is sufficient to only know host-2-host dependencies.
Do you have a web server? Is the web server running? The last item to check was if the web server was able to talk to the database? Setting up and monitoring these systems was pretty easy compared to today’s standards. There were no dynamic web applications or complex user scenarios to have to monitor.
Content is placed on the network of servers in the Open Connect CDN as close to the end user as possible, improving the streaming experience for our customers and reducing costs for both Netflix and our Internet Service Provider (ISP) partners. takes place in Amazon Web Services (AWS), whereas everything that happens afterwards (i.e.,
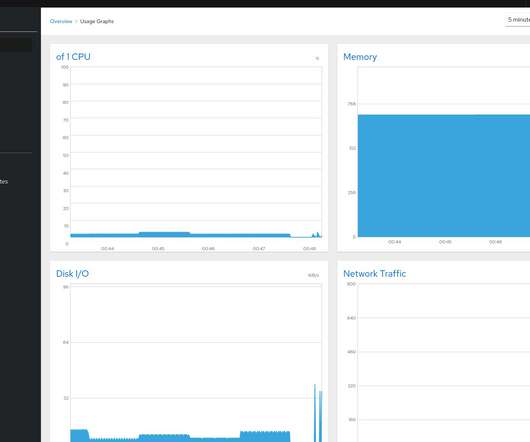
An important concern in optimizing the hardware platform is hardware components that restrict performance, known as bottlenecks. You monitor the server over time so that you can determine Server average […]. Start with obtaining a performance baseline.
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storage hardware in preparation for a multi-million dollar super-bowl ad campaign. Our procurement decisions were based on trace data that was pulled from a handful of fragmented monitoring solutions.
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance.
Audit logs are available on individual nodes at DATASTORE_PATH/log/server. Audit logs open up a whole new set of use cases for custom notifications using log monitoring tools. Starting with version 1.170, hardware updates are applied automatically when services are restarted. See audit log example below: audit.cluster.event.log.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Failure detection : Monitoring mechanisms detect failures or issues that could lead to failures.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content