This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Luckily, the m5.12xl instance type exposes a set of core PMCs (Performance Monitoring Counters, a.k.a. Additionally, ping-ponging coherency traffic has to be monitored through the last level shared cache ’s controller, which leads to even more stalls. Thread 0’s cache in this example.
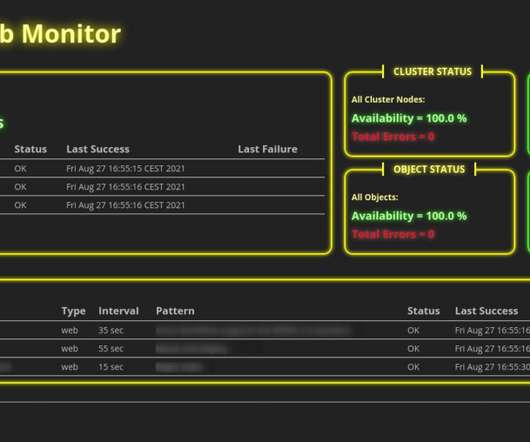
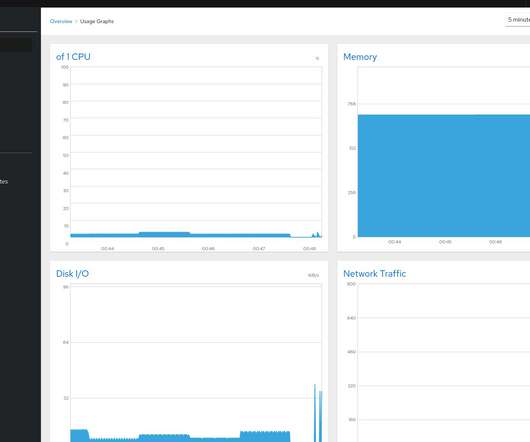
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. For that reason, we use monitoring tools. And there are a lot of monitoring tools available providing all kinds of features and concepts.
As of September 2020, we run 51 clusters on 1100 EC2 instances distributed across six AWS Regions ensuring that all our users can leverage the Dynatrace Software Intelligence Platform to monitor their hybrid-multi cloud environments. The AWS team confirmed a known hardware issue affecting a certain amount of EC2 machines in that region.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. They’ve gone from just maintaining their organization’s hardware and software to becoming an essential function for meeting strategic business objectives.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Logs can include data about user inputs, system processes, and hardware states. What is log monitoring? Log monitoring vs log analytics.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
The Dynatrace Software Intelligence Platform provides you with so much more monitoring functionality. This means that your entire IT infrastructure can be monitored within minutes. OneAgent monitors the full technology stack of each host. Automate and save time! AIOps for automating the identification and resolution of problems.
We’re happy to announce the launch of Dynatrace Synthetic private browser monitors! We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. Monitor your internal apps from within your offices.
Run your own Video Conference Service with Jitsi , I started looking for a reliable solution to monitor my instance that runs Jitsi. " I was in the search for a straightforward tool that shows me hardware "VM" metrics and allows me to check the logs without ssh into the VM and ideally tool should be Open Source.
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams.
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data. Watch webinar now!
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Observability platforms address the challenge of message queue monitoring by capturing and analyzing queue data. The post What is a message queue?
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
Synthetic monitoring locations execute browser and HTTP monitors from within your own infrastructure and answer questions about the availability of applications (internal and external) from the perspective of specific points of interest such as branch offices. Dynatrace news. What’s next.
this is addressed through monitoring and redundancy. Hardware - servers/storage hardware/software faults such as disk failure, disk full, other hardware failures, servers running out of allocated resources, server software behaving abnormally, intra DC network connectivity issues, etc. Again the approach here is the same.
This means you no longer have to procure new hardware, which can be a time-consuming and expensive process. and scales up as monitoring environments grow by simply adding nodes, with built-in failover and automatic load balancing to ensure optimal resource usage.
Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Achieve high SLOs with seamless monitoring when entire data centers experience outages.
Numerous hurdles can hinder successful deployments, from resource constraints to external dependencies and monitoring inadequacies. Vulnerabilities or hardware failures can disrupt deployments and compromise application security. Ensuring that your monitoring solution monitors your cluster.
A Dynatrace Managed cluster may lack the necessary hardware to process all the additional incoming data. The cluster sizing doesn’t match requirements because a large number of hosts were added to monitoring after the initial sizing, and the cluster needs to be expanded. All this automatically and with the same hardware.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. This is significant when coupled with the OpenShift platform.
Having the ability to monitor the performance and availability of your organization’s internal applications—in addition to your organization’s customer-facing applications—from within your corporate network is an important benefit of synthetic monitoring. Browser monitors can now be executed from Windows-based ActiveGates.
Managing SNMP devices at scale can be challenging SNMP (Simple Network Management Protocol) provides a standardized framework for monitoring and managing devices on IP networks. Its simplicity, scalability, and compatibility with a wide range of hardware make it an ideal choice for network management across diverse environments.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. Performing updates, installing software, and resolving hardware issues requires up to 17 hours of developer time every week.
Many customers try to use traditional tools to monitor and observe modern software stacks, but they struggle to deal with the dynamic and changing nature of cloud environments. When an application runs on a single large computing element, a single operating system can monitor every aspect of the system.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. Dynatrace now monitors your AWS Outposts environment just like any AWS cloud Region. Next steps.
When we wanted to add a location, we had to ship hardware and get someone to install that hardware in a rack with power and network. Hardware was outdated. Fixed hardware is a single point of failure – even when we had redundant machines. Keep hardware and browsers updated at all times. Sound easy?
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Computer operations manages the physical location of the servers — cooling, electricity, and backups — and monitors and responds to alerts. Functionality.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. What is the difference between monitoring and observability? Is observability really monitoring by another name? In short, no.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads. Monitoring the cluster nodes preemptively addresses potential issues, ensuring the system operates smoothly.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. What’s included.
We do our best to provide support for all popular hardware and OS platforms that are used by our customers for the hosting of their business services. Please check our detailed OneAgent support matrix to learn about feature availability on specific hardware and software platforms. What about ActiveGates? What about Dynatrace Managed?
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. These tools help ensure proactive monitoring and quick issue resolution.
But with the benefits also come concerns about observability, and how to monitor and manage ever-expanding cloud software stacks. As a bonus, operations staff never needs to update operating systems or hardware, because AWS manages servers with no stoppage of application functionality. How do AWS Lambda functions impact monitoring?
While to-date it’s been possible to integrate Dynatrace Managed for intelligent monitoring of services running on AWS and Azure, today we’re excited to announce the release of our Dynatrace Managed marketplace listing for the Google Cloud Platform. For more details, see Dynatrace Managed hardware and systems requirements.
In FaaS environments, providers manage all the hardware. Alternatively, in a CaaS model, businesses can directly access and manage containers on hardware. In turn, this makes it easier to manage, monitor, and modify containers at scale without sacrificing security. CaaS vs. FaaS.
Ensuring your monitoring system stays up and running is vital. High availability (HA) minimizes downtime for Percona Monitoring and Management (PMM) during hardware failures, in times of disaster recovery, or increased usage of the tool.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis, a powerful in-memory data store, is no exception.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Built-in monitoring. Needs third party tools for monitoring.
To be ready to deal with crashes, you need a monitoring solution that alerts you to critical events, provides you with an overview of crash events, and enables you to quickly resolve issues that contribute to crashes. Dynatrace continues to work hard to make error and performance monitoring of mobile apps faster and more intuitive.
First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. Auer also explained how observability data is used to deliver insights to the business, through a fully automated monitoring service. Digital experience revealed by real-user monitoring.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Meanwhile, security analytics tools leverage behavior-based analysis to continuously monitor cloud, on-prem, and hybrid networks.
Test tools are software or hardware designed to test a system or application. In addition to automating testing tasks, test tools can produce test data, monitor system performance, and report on test results. Various test tools are available for different types of testing, including unit testing, integration testing, and more.
In the recent webinar, Good to great: Case studies in excellence on state and local government transformations, Tammy Zbojniewicz, enterprise monitoring and service delivery owner within Michigan’s Department of Technology, Management, and Budget (DTMB), illustrates that meeting both objectives is possible.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content