This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
CPU consumption in Unix/Linux operatingsystems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. User CPU Time and System CPU Time.
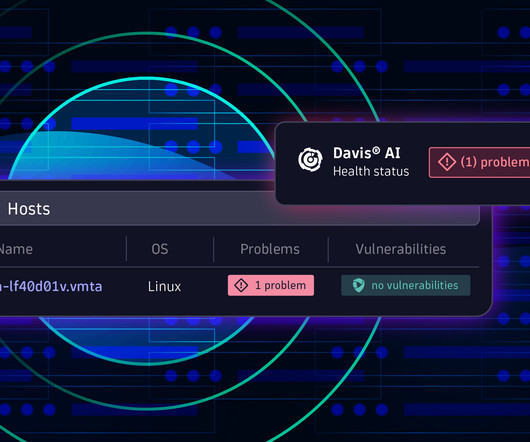
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x).
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operatingsystem” of the cloud. Kubernetes is emerging as the “operatingsystem” of the cloud. Kubernetes is emerging as the “operatingsystem” of the cloud. Kubernetes moved to the cloud in 2022.
When an application runs on a single large computing element, a single operatingsystem can monitor every aspect of the system. Modern operatingsystems provide capabilities to observe and report various metrics about the applications running. Just as the code is monolithic, so is the logging.
CPU consumption in Unix/Linux operatingsystems is studied using eight different metrics: User CPU time , System CPU time , nice CPU time , Idle CPU time , Waiting CPU time , Hardware Interrupt CPU time , Software Interrupt CPU time , Stolen CPU time. In this article let's study ‘Software Interrupt CPU time’.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operatingsystem, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. This means that Dynatrace continues full operation when a majority of nodes are up and a maximum of two nodes are down at a time. Dynatrace news. Self-contained turnkey solution.
Real-time stream processing to perform live activity tracking, data cleansing, metrics generation, and more. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. Real-time file processing, for quickly indexing files, processing logs, and validating content.
ITOA automates repetitive cloud operations tasks and streamlines the flow of analytics into decision-making processes. Additionally, ITOA gathers and processes information from applications, services, networks, operatingsystems, and cloud infrastructure hardware logs in real time. Define core metrics.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operatingsystem and infrastructure. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. Observability.
CPU consumption in Unix/Linux operatingsystems are studied using 8 different metrics: User CPU time , System CPU time , nice CPU time , Idle CPU time , Waiting CPU time , Hardware Interrupt CPU time , Software Interrupt CPU time , and Stolen CPU time. In this article, let's study ‘nice CPU time’.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operatingsystem, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
A log is a detailed, timestamped record of an event generated by an operatingsystem, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. Optimized system performance. More automation. But logs alone aren’t enough.
Telegraf is an agent that runs on your operatingsystem of choice, schedules gathering metrics and events from various sources and then sends them to one or more sinks, such as InfluxDB or Kafka. It can also retrieve information about hardware and software from the OS. Learn how to use Telegraf on Windows.
CPU consumption in Unix/Linux operatingsystems is broken down into 8 different metrics: User CPU time , System CPU time , nice CPU time , Idle CPU time , Waiting CPU time , Hardware Interrupt CPU time , Software Interrupt CPU time , and Stolen CPU time. In this article, let us study ‘waiting CPU time’.
An always-on infrastructure provides the foundation for system availability that can deliver five-nines availability. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models. Gather observability data from all digital touchpoints.
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. But to understand them in more detail is difficult without the aid of other metrics. I've never seen an explanation.
In general terms, here are potential trouble spots: Hardware failure: Manufacturing defects, wear and tear, physical damage, and other factors can cause hardware to fail. heat) can damage hardware components and prompt data loss. Without data backup mechanisms, there can be data loss or system downtime.
Software and hardware components are autonomous and execute tasks concurrently. Concurrency refers to the system’s ability to carry out multiple tasks in parallel and manage the access and usage of shared resources. Big systems cost big money. Monitoring a Distributed System. Heterogeneity. Fault Tolerance.
In addition to upgrading the underlying operatingsystem, we've added support for: Lighthouse 12.3.0 Synthetic updates are known to cause baseline changes due to hardware changes, browser optimization or in the case of Lighthouse, changes to the methodology. previously 10.4.0) See full release history here. and 10.4.0
A wide range of users with different operatingsystems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. Basic server metrics. Custom metrics. RUM gathers data from real life users to analyze application performance.
The primary metric for memory bandwidth in multicore processors is that maximum sustained performance when using many cores. This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g.,
Using zswap means that no new hardware solutions are required, enabling rapid deployment across clusters. The key to an efficient system is the identification of cold pages: the cold age threshold determines how many seconds we can go without a page being accessed before it is declared cold.
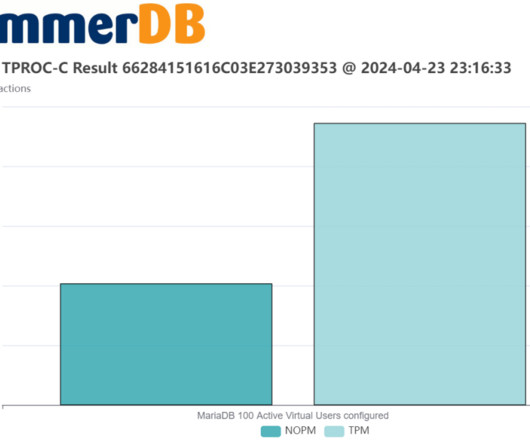
It enables the user to measure database performance and make comparative judgements about database hardware and software. HammerDB has graphical and command line interfaces for the Windows and Linux operatingsystems. The NOPM Metric. HammerDB is a software application for database benchmarking.
Let’s look at how the workloads behave when running on an identical system We ran both sysbench and HammerDB on a system with: Processors: Two Intel Xeon 8360Y processor sockets (36 Core/72 Threads per socket). OperatingSystem: Ubuntu 22.04 DISK METRICS sysstat_io_nvme0n1_avg_wait_ms 8.32 Database: MySQL 8.0.31
The key metric for measuring the sustainability of a digital product is its energy usage. how much data does the browser have to download to display your website) and resource usage of the hardware serving and receiving the website. “You Can’t Manage What You Can’t Measure”. These include data transfer (i.e. Sustainable Web Design.
Additionally, end users can access your site or applications from anywhere in the world using different browsers, operatingsystems, and mobile devices, all with varying connection speeds. Use baseline metrics to identify performance degradation by reviewing elements provided by waterfall charts.
Most manufacturers' implementations immediately flush pending writes to physical disk during the restart operations. Example 1: Hardware failure (CPU board) Battery backup on the caching controller maintained the data. Important Always consult with your hardware manufacturer for proper stable media strategies.
As the chart shows because we know that both HammerDB and the implementation of the TPC-C workload scales then we can determine that with this particular database engine both the software and hardware scales as well. If you only test your own application (and if you have more than one application which one will you use for benchmarking?)
A learning organization, disaster recovery testing, game days, and chaos engineering tools are all important components of a continuously resilient system. This discussion focuses on hardware, software and operational failure modes. The update rate could be set too high so that the sensor or metric delivery system can’t keep up.
A learning organization, disaster recovery testing, game days, and chaos engineering tools are all important components of a continuously resilient system. This discussion focuses on hardware, software and operational failure modes. The update rate could be set too high so that the sensor or metric delivery system can’t keep up.
It is mostly a metric of quality assurance, but the whole app development team is active in its operations. Given the wide variety of computers, operatingsystems, and browsers currently available to consumers, testing these variations is important for testers to work.
The primary metric for memory bandwidth in multicore processors is that maximum sustained performance when using many cores. This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g.,
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. These may be performance, high availability, operational cost, management, capacity planning, scalability, security, monitoring, etc.
In contrast, observability enables teams to understand a system’s internal state by analyzing the data it generates, including logs, metrics, and traces. Every hardware, software, cloud infrastructure component, container, open source tool, and microservice generates records of every activity within modern environments.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Setting Realistic Goals. Defining The Environment.
Dynatrace introduced numerous powerful features to its Infrastructure & Operations app, addressing the emerging requirement for enhanced end-to-end infrastructure observability. These enhancements are designed to empower IT operations and SRE teams with more comprehensive visibility and increased efficiency at any time.
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024. tpmC tpmC is the transactions per minute metric that is the measurement of the official TPC-C benchmark from the TPC-Council.
What operatingsystems do you use? We also generate quite a bit of internal application metrics using a home grown framework. We use Grafana/Nagios/Kibana, internal tools and other tools to monitor performance for other parts of the system. How are software and hardware upgrades rolled out? Nginx, HAproxy.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content