This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Any service provider tries to reach several metrics in their activity. One group of these metrics is service quality. Quality metrics contain: The ratio of successfully processed requests. But what is the metric that shows service hardware monopolization by a group of users? Number of requests dependent curves.
Additional benefits of Dynatrace SaaS on Azure include: No infrastructure investment : Dynatrace manages the infrastructure for you, including automatic visibility, problem detection, and smart alerting across virtual networks, virtual infrastructure, and container orchestration.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. Automatic recovery for outages for up to 72 hours.
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Disk measurements with per-disk resolution.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
For Carbon Impact, these business events come from an automation workflow that translates host utilization metrics into energy consumption in watt hours (Wh) and into greenhouse gas emissions in carbon dioxide equivalent (CO2e). If you think this was difficult at the hardware level, it’s significantly more difficult for software.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. It differentiates Dynatrace as an AWS Partner Network (APN) member with a fully tested product on AWS Outposts. “We
They’ve gone from just maintaining their organization’s hardware and software to becoming an essential function for meeting strategic business objectives. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends. Business observability is emerging as the answer.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Although modern cloud systems simplify tasks, such as deploying apps and provisioning new hardware and servers, hybrid cloud and multicloud environments are often complex.
CPU consumption in Unix/Linux operating systems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. Let’s say your application is making network calls to external applications.
Modern operating systems provide capabilities to observe and report various metrics about the applications running. The components of partitioned applications generally communicate over a network call. Another aspect of microservices is how the service itself relates to the underlying hardware.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Networking. In production, containers are easy to replicate. Observability.
Open Connect Open Connect is Netflix’s content delivery network (CDN). video streaming) takes place in the Open Connect network. The network devices that underlie a large portion of the CDN are mostly managed by Python applications. If any of this interests you, check out the jobs site or find us at PyCon. are you logged in?
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
Real-time stream processing to perform live activity tracking, data cleansing, metrics generation, and more. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. Real-time file processing, for quickly indexing files, processing logs, and validating content.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Disk measurements with per-disk resolution.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. Define core metrics.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Host performance is tracked via high-level health metrics with details for each host (these appear on your home dashboard by default).
We were very pleased to see that AV1 streaming improved members’ viewing experience, particularly under challenging network conditions. AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. Logs are an essential part of the three fundamental pillars of observability : metrics, logs, and traces.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
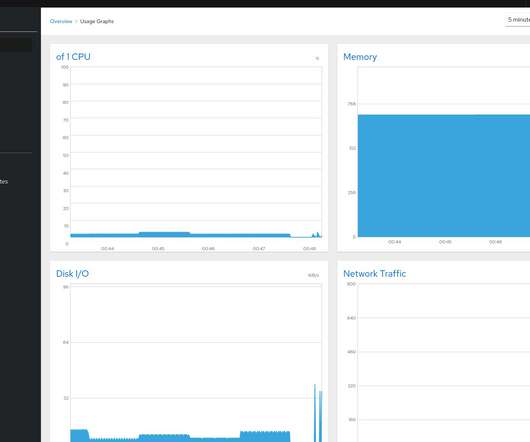
I needed basic information on RAM, CPU, Disk, Networking, and I/O to assess the performance bottleneck for the serve. " I was in the search for a straightforward tool that shows me hardware "VM" metrics and allows me to check the logs without ssh into the VM and ideally tool should be Open Source.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. In-depth, AI-driven metrics can help to manage this simplicity. But how does FaaS fit in? Don’t double up on functions.
While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
However, one metric I feel that front-end developers overlook all too quickly is Time to First Byte (TTFB). The reason is because mobile networks are, as a rule, high latency connections. can all provide valuable insights. Armed with this knowledge, we can soon understand why TTFB can often increase so dramatically on mobile.
Dynatrace innovates again with the release of topology-driven auto-adaptive metric baselines. Introducing Davis data units (DDUs) for increased flexibility with custom metrics. Hardware requirements updates – “Trial” node category changed to Micro. Premium High Availability goes GA. Cluster Management Console.
Unified observability is the ability to know how systems and infrastructure are performing based on the data they generate, such as logs, metrics, and traces. In modern cloud environments, every piece of hardware, software, cloud infrastructure component, container, open-source tool, and microservice generates records of every activity.
In contrast, observability enables teams to understand a system’s internal state by analyzing the data it generates, including logs, metrics, and traces. Every hardware, software, cloud infrastructure component, container, open source tool, and microservice generates records of every activity within modern environments.
Instead, to speed up response times, applications are now processing most data at the network’s perimeter, closest to the data’s origin. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models.
Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. It also provides an HTTP API for retrieving performance metrics and a command-line tool for advanced management tasks. However, performance can decline under high traffic conditions.
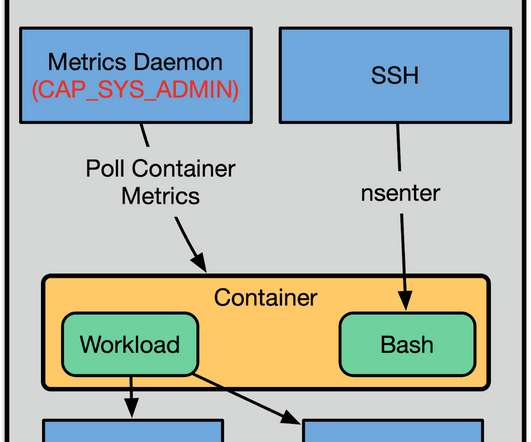
In addition to the default Docker namespaces (mount, network, UTS, IPC, and PID), we employ user namespaces for added layers of isolation. We had a shared metrics daemon on the machine that reached in and polled metrics from the container. In addition to that, we could use our standard metrics daemons on the host.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks.
CPU consumption in Unix/Linux operating systems is broken down into 8 different metrics: User CPU time , System CPU time , nice CPU time , Idle CPU time , Waiting CPU time , Hardware Interrupt CPU time , Software Interrupt CPU time , and Stolen CPU time. In this article, let us study ‘waiting CPU time’. What Is ‘Waiting’ CPU Time?
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Too many fine-grained services leading to network and communication overhead. All this was made possible without any need for hardware upgrades : Misconfigured queue and pool sizes are a common issue in distributed architectures. .
Have you ever looked at the page speed metrics – such as Start Render and Largest Contentful Paint – for your site in both your synthetic and real user monitoring tools and wondered "Why are these numbers so different?" For a myriad of reasons, older hardware can't always accommodate faster speeds. After DOCSIS 4.0
Things always always feel fast when we’re developing because, more often than not, we’re working on high-spec machines on dedicated networks, and also serving from localhost which removes the bulk of the latency and bandwidth issues that a real user would suffer. Do changes in performance correlate to changes in business metrics?
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
But pages keep getting bigger and more complex year over year – and this increasing size and complexity is not fully mitigated by faster devices and networks, or by our hard-working browsers. How does page bloat affect other metrics, such as Google's Core Web Vitals? Clearly we need to keep talking about it.
The pool of resources, at this time, is the CPU, memory, and networking resources of Amazon EC2 instances as partitioned by containers. networks ports, memory, CPU, etc). To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. Replication lag can occur due to various factors such as network latency, system resource limitations, complex transactions, or heavy write loads on the primary/master database.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content