This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks.
This is a given, whether you are using the highest quality hardware or lowest cost components. When customers left the constraining, old world of IT hardware and datacenters behind, they started to develop systems with new and interesting usage patterns that no one had ever seen before. Primitives not frameworks. No gatekeepers.
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with!
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. As a result, IT teams picked hardware somewhat blindly but with a strong bias towards oversizing for the sake of expanding the budget, leading to systems running at 10-15% of maximum capacity.
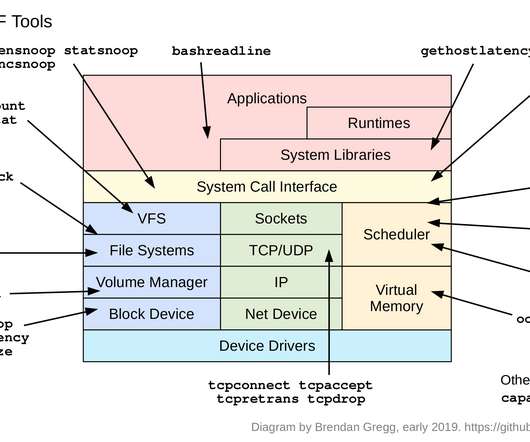
This was a chance to talk about other things I've been working on, such as the present and future of hardware performance. The video is on [youtube]: The slides are on [slideshare] or as a [PDF]: I work on many areas of performance, but recently I've had a lot of demand to talk about BPF. Ford, et al., “TCP
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. Data written to these volumes is maintained on your on-premises storage hardware while being asynchronously backed up to AWS, where it is stored in Amazon S3 in the form of Amazon EBS snapshots.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Unfortunately, this means that the age-old Telco bugbears will rear their ugly heads again, including latency. 5G, as a fundamental requirement, mandates a 1 millisecond latency from the datasource to its destination. In fact, 5G has plenty of valid use cases, one of which is virtual reality. This requires 1 ms network latency.
Unfortunately, this means that the age-old Telco bugbears will rear their ugly heads again, including latency. 5G, as a fundamental requirement, mandates a 1 millisecond latency from the datasource to its destination. In fact, 5G has plenty of valid use cases, one of which is virtual reality. This requires 1 ms network latency.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. By implementing data replication strategies, distributed storage systems achieve greater.
It was – like the hypothetical movie I describe above – more than a little bit odd, as you could leave a session discussing ever more abstract layers of virtualization and walk into one where they emphasized the critical importance of pinning a network interface to a specific VM for optimal performance.
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
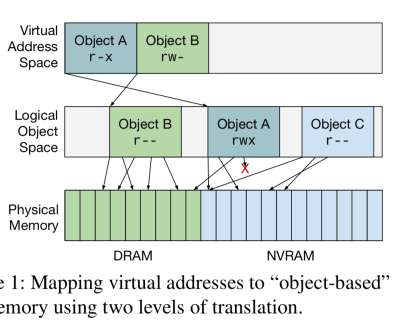
This is a companion paper to the " persistent problem " piece that we looked at earlier this week, going a little deeper into the object pointer representation choices and the mapping of a virtual object space into physical address spaces. Both abstractions must be implemented in a way that is efficient using existing hardware.
These systems can include physical servers, containers, virtual machines, or even a device, or node, that connects and communicates with the network. Software and hardware components are autonomous and execute tasks concurrently. This also includes latency, or the time it takes for data or a request to get through a network.
The main change last week is that the committee decided to postpone supporting contracts on virtual functions; work will continue on that and other extensions. This can create variable latency during iteration. For an overview, see Timur Doumlers blog post Contracts for C++ explained in 5 minutes.
Fast forward a few years after Azure SQL Database was released to when Azure SQL Managed Instance was in public preview, and "vCores" (virtual cores) were announced for Azure SQL Database. Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. New Hardware Configuration for Provisioned Compute Tier.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. About CXL hardware availability with academia.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. sum: 23997083.58
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. bpftrace uses BPF (Berkeley Packet Filter), an in-kernel execution engine that processes a virtual instruction set.
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Benefits of a Serverless Model.
It was – like the hypothetical movie I describe above – more than a little bit odd, as you could leave a session discussing ever more abstract layers of virtualization and walk into one where they emphasized the critical importance of pinning a network interface to a specific VM for optimal performance.
This was a chance to talk about other things I've been working on, such as the present and future of hardware performance. The video is on [youtube]: The slides are [here] or as a [PDF]: first prev next last / permalink/zoom I work on many areas of performance, but recently I've had a lot of demand to talk about BPF. Ford, et al., “TCP
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
You cannot virtualize everything…yet. Software services still require physical devices and hardware for them to function. Knowing when and where an error, downtime, or application latency occurs is a critical factor in limiting the impact to users and customers. Asset Management.
Now in development in WebKit after years of radio silence, WebXR APIs provide Augmented Reality and Virtual Reality input and scene information to web applications. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. is access to hardware devices. Offscreen Canvas.
To move as fast as they can at scale while protecting mission-critical data, more and more organizations are investing in private 5G networks, also known as private cellular networks or just “private 5G” (not to be confused with virtual private networks, which are something totally different). billion in 2022. billion, growing 48.2%
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible.
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. Even when we do flush caches, the latency of flushing can itself be used as a channel! Microarchitectural channels. Threat scenarios.
Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. What happens if processes really do try to populate all that virtual memory? Many new tools can now be written, and the main toolkit we're working on is [bcc]. Hit Ctrl-C to end. ^C
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Containerized data workloads running on Kubernetes offer several advantages over traditional virtual machine/bare metal based data workloads including but not limited to. direct access to raw block storage [18] without the abstraction of a filesystem for workloads that require consistent I/O performance and low latency.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
The data shows a scripted automated workload running a number of back to back tests each time with an increasing number of virtual users. Using MariaDB and analysing performance at a workload of 80 Virtual Users the first place we can look at is the information schema user_statistics to quantify the difference in the database traffic.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. driver: intel_pstate CPUs which run at the same hardware frequency: 0 . maximum transition latency: Cannot determine or is not supported. . hardware limits: 1000 MHz - 3.80
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. For TPC-C this meant enough available spindles to reduce I/O latency and for TPC-H enough bandwidth for data throughput. This was both expensive and time consuming to configure.
While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.” This was our starting point for troubleshooting.
Operating System (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100. The CFQ works well for many general use cases but lacks latency guarantees. Without further ado, let’s start with the OS settings.
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. Example 1: Hardware failure (CPU board) Battery backup on the caching controller maintained the data. Important Always consult with your hardware manufacturer for proper stable media strategies.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content