This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Therefore, they experience how the application code functions and how the application operations depend on the underlying hardware resources and the operating system managed by Hyper-V.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
This is where Lambda comes in: Developers can deploy programs with no concern for the underlying hardware, connecting to services in the broader ecosystem, creating APIs, preparing data, or sending push notifications directly in the cloud, to list just a few examples. AWS continues to improve how it handles latency issues.
SCM slots between DRAM and flash in terms of latency, cost, and density. Thus, despite both quoting 11 nines of durability against hardware failures, S3 is durable against failures that B2 is not, and is thus better. Because of that big servers and other memory systems need to have another kind of memory in the hierarchy.
The breadth of fully-featured services, the pay-as-you-go scalability, and the agility of cloud platforms enable organizations to expand their modern approaches to building and managing digital services in a way they can’t with on-premises apps and infrastructure. Increased scalability. Reduced cost.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. Making observability actionable and scalable for IT teams. Here are some ways you can make observability actionable and scalable.
Scalability is one of the main drivers of the NoSQL movement. Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write scalability. Data Placement.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post.
To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures. This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked.
Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law ). This makes the whole system latency sensitive. Regular expression matching is well studied, but state of the art hardware algorithms don’t reach the performance and memory targets needed for Pigasus.
Looking back over the past 10 years, there are hundreds of lessons that we’ve learned about building and operating services that need to be secure, reliable, scalable, with predictable performance at the lowest possible cost. This is a given, whether you are using the highest quality hardware or lowest cost components.
In traditional database architectures, database engines often run a small search engine or data warehouse engines on the same hardware as the database. A more scalable option is to decouple these systems and build a pipe that connects these engines and feeds all change records from the source database to the data warehouse (e.g.,
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with!
Werner Vogels weblog on building scalable and robust distributed systems. For example, the most fundamental abstraction trade-off has always been latency versus throughput. The throughput of this pipeline is more important than the latency of the individual operations. All Things Distributed. Comments (). Where to go from here?
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. It is important to understand these challenges properly to find solutions for them.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Some cloud providers also offer specialized instances for database workloads, which may provide additional features and optimizations for performance and scalability.
Werner Vogels weblog on building scalable and robust distributed systems. In particular this has been true for applications based on algorithms - often MPI-based - that depend on frequent low-latency communication and/or require significant cross sectional bandwidth. All Things Distributed. By Werner Vogels on 12 July 2010 05:00 PM.
MongoDB is a dynamic database system continually evolving to deliver optimized performance, robust security, and limitless scalability. Sharded time-series collections for improved scalability and performance. You should also review your hardware resources, how you use MongoDB, and any custom configurations. In MongoDB 6.x:
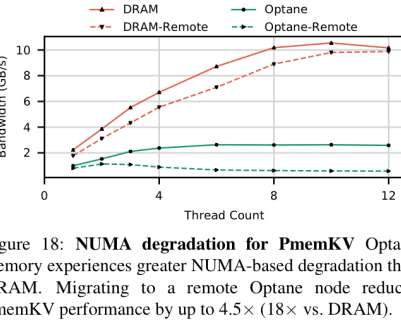
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM.
Werner Vogels weblog on building scalable and robust distributed systems. The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. All Things Distributed. Expanding the Cloud - The AWS Storage Gateway. By Werner Vogels on 23 January 2012 12:01 AM.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Use hardware-based encryption and ensure regular over-the-air updates to maintain device security. Increased latency during peak loads. Data interception during transit.
But for those who are not so familiar, in this post, we will discuss how Kubernetes has emerged as the unsung hero in an industry where agility and scalability are critical success factors. Your workloads, encapsulated in containers, can be deployed freely across different clouds or your own hardware. have adopted Kubernetes.
Modern web applications and pages, such as single-page applications, that put the user experience at its utmost priority are expected to be available 24/7, anywhere in the world, usable on any screen size, secure, flexible, scalable and be ready to meet traffic spikes on demand. Network latency. Hardware resources. Wi-Fi usage.
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
Software and hardware components are autonomous and execute tasks concurrently. A distributed system comprises of a variety of hardware and software components with different operating systems and technologies, meaning the processors are separate and independent of each other. Scalability. Concurrency. Heterogeneity.
Hardware Optimizers” want to get the maximum utilization out of hardware. These systems were designed to have a lifetime of half a decade or more, and rapidly changing hardware meant that the initial deployment had to be sized for 5-7 years out. Latency Optimizers” – need support for very large federated deployments.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. About CXL hardware availability with academia.
The data shape will dictate capacity planning, tuning of the backbone, and scalability analysis for individual components. A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. At least once? At most once?
Breaking that assumption allowed Ceph to introduce a new storage backend called BlueStore with much better performance and predictability, and the ability to support the changing storage hardware landscape. It should offer high bandwidth, horizontal scalability, fault tolerance, and strong consistency. Supporting new storage hardware.
This limitation is at the database level rather than the hardware level, nevertheless with up to date hardware (from mid-2018) PostgreSQL on a 2 socket system can be expected to deliver more than 2M PostgreSQL TPM and 1M NOPM with the HammerDB TPC-C test. . CPUs which run at the same hardware frequency: 0. Latency: 0.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. driver: intel_pstate CPUs which run at the same hardware frequency: 0 . maximum transition latency: Cannot determine or is not supported. . hardware limits: 1000 MHz - 3.80
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Scalability. Benefits of a Serverless Model.
Software services still require physical devices and hardware for them to function. An organization’s response to an incident, whether we are talking about downtime, security breaches or cyber-attacks, or even prolonged latency and repeated errors, is critical to the continued success of the business and trust from the customer or end user.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. sum: 23997083.58
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. This can significantly elevate user satisfaction and engagement.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
Under the hood, the BlueData used several enhancements to boosts the I/O performance and scalability of container-based clusters. Using default scheduler's node affinity feature you can ensure that certain pods only schedule on nodes with specialized hardware like GPU, memory-optimised, I/O optimised etc. Native frameworks.
Site reliability engineers are focused with creating scalable and reliable software systems, so this also includes ensuring that development work is efficient and reliable, so when the finished product is ready for production, there are no surprises. It is at this junction where the site reliability engineer role comes in.
Quantitative performance testing looks at metrics like response time while qualitative testing is concerned with scalability, stability, and interoperability. Bottlenecks are just one of many problems that can occur when your website isn’t scalable. If you don’t test, then you’ll have to learn about them the hard way.
Hardware Optimizers” want to get the maximum utilization out of hardware. These systems were designed to have a lifetime of half a decade or more, and rapidly changing hardware meant that the initial deployment had to be sized for 5-7 years out. Latency Optimizers” – need support for very large federated deployments.
While Wi-Fi theoretically can achieve 5G-like speeds, it falls short in providing the consistent performance and reliability that 5G offers, including low latency, higher speeds, and increased bandwidth. Additionally, frequent handoffs between access points can lead to delays and connection drops.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content