This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. When an application is triggered, it can cause latency as the application starts. This creates latency when they need to restart.
This is where Lambda comes in: Developers can deploy programs with no concern for the underlying hardware, connecting to services in the broader ecosystem, creating APIs, preparing data, or sending push notifications directly in the cloud, to list just a few examples. AWS continues to improve how it handles latency issues.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. We formulate the problem as a Mixed Integer Program (MIP).
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. Deploying your application and database on the same VPC also provides the lowest possible latency path. Where to host your cloud database?
We believe that making these GPU resources available for everyone to use at low cost will drive new innovation in the application of highly parallel programming models. For example, the most fundamental abstraction trade-off has always been latency versus throughput. General Purpose GPU programming. From CPU to GPU.
SCM slots between DRAM and flash in terms of latency, cost, and density. Thus, despite both quoting 11 nines of durability against hardware failures, S3 is durable against failures that B2 is not, and is thus better. Because of that big servers and other memory systems need to have another kind of memory in the hierarchy.
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. As a result, IT teams picked hardware somewhat blindly but with a strong bias towards oversizing for the sake of expanding the budget, leading to systems running at 10-15% of maximum capacity.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency.
In traditional database architectures, database engines often run a small search engine or data warehouse engines on the same hardware as the database. No matter which mechanism you choose to use, we make the stream data available to you instantly (latency in milliseconds) and how fast you want to apply the changes is up to you.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Relatedly, P1494R4 Partial program correctness by Davis Herring adds the idea of observable checkpoints that limit the ability of undefined behavior to perform time-travel optimizations. Note: This is the second time contracts has been voted into draft standard C++. It was briefly part of draft C++20, but was then removed for further work.
Shredder is " a low-latency multi-tenant cloud store that allows small units of computation to be performed directly within storage nodes. " If you want a lightweight, fast-starting, easy to program for, embeddable application runtime that also offers isolation, then a natural choice is V8 isolates. High performance.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. The call for participation ends on March 2nd 23:59 SGT! Ford, et al., “TCP
They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more. In 2013, AWS launched the AWS Activate program to provide Nordic startups access to guidance and one-on-one time with AWS experts.
With the rapid advancements in web application technologies, programming languages, cloud computing services, microservices, hybrid environments, etc., This complexity is “hidden” to the end user, like how an API (Application Programming Interface) operates, whether that is an actual user or another computer. Concurrency.
Your workloads, encapsulated in containers, can be deployed freely across different clouds or your own hardware. Role-Based Access Control (RBAC) : RBAC manages permissions to ensure that only individuals, programs, or processes with the proper authorization can utilize particular resources.
Different browsers running on different platforms and hardware, respecting our user preferences and browsing modes (Safari Reader/ assistive technologies), being served to geo-locations with varying latency and intermittency increase the likeness of something not working as intended. More after jump! Responding to Errors.
90491 N|rnberg (Germany) Consulting+Networking+Programming+etc'ing 42. They are demand on the system, albeit for software resources rather than hardware resources. ## Decomposing Linux load averages Can the Linux load average value be fully decomposed into components? Latency was acceptable and no one complained.
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. The probe is BEGIN , a special probe that runs at the beginning of the program (like awk). There's no filter.
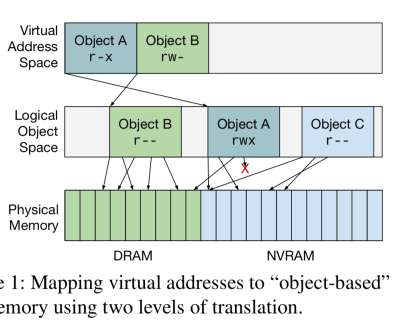
using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. Figure 2: Latency characteristics of memory technologies (source: Maruf et al.,
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Was there some other program consuming CPU, like a misbehaving Ubuntu service that wasn't in CentOS? As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
. …software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
Provides support for "unread counts", e.g. for email and chat programs. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. is access to hardware devices. Some commenters appear to confuse unlike hardware for differences in software. Media Session API.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? MPI is a commonly used standard to implement message-passing programs on computer clusters. The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? MPI is a commonly used standard to implement message-passing programs on computer clusters. The MPI runtime library. in ways that are seldom transparent.
On the last morning of the conference Daniel Bittman presented some of the work being done in the context of the Twizzler OS project to explore new programming models for NVM. The starting point is a set of three asumptions for an NVM-based programming model: Compared to traditional persistent media, NVM is fast.
Now welcome to the hardware jungle. I should have remembered that describing a PC as a “heterogeneous cluster in a box” is a big red button for people, in particular because “cluster” implies “parts can fail and program should continue.” — The free lunch is over. The slides are available here.
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. The low-level streaming implementations of the mentioned engines require specialized knowledge in order to program new applications.
3] Oh, and it should be imperatively programmed with Lisp-in-C's-clothing. Recall that browsers arose atop platforms that universally provided a host of services by the late 90's: system fonts (to support layout programs, including WYSIWYG editing). multi-tasking & concurrent programming. high-color image raster.
I even contributed my own hot take last year with my O’Reilly Radar article Real-Real-World Programming with ChatGPT.) software” rather than “hardware” in our brains). What more is left to say by now? Well, I bet very few of those people have actually chatted with ChatGPT.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. It was a great privilege. That's about 24 hours from now!
Amazon’s Ring partnership with one in ten US police departments troubles many privacy groups because it creates a vast surveillance program. Until we acknowledge that hardware put in a home is different from a cloud service, we will never get it right. What if you don’t want to be a part of the police state? Lots of problems, now what?
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. This is an uninspiring fraction of peak performance that would normally suggest significant inefficiencies in either the hardware or software.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. This is an uninspiring fraction of peak performance that would normally suggest significant inefficiencies in either the hardware or software.
Hardware access APIs, notably: Geolocation. This might not be objectionable in programs that also offer themselves as browsers, but the WebView IAB sleight of hand is to act as a browser when users least expect it, but never to cop to the power and privacy implications of the awesome responsibilities that real-boy browsers solemnly accept.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Was there some other program consuming CPU, like a misbehaving Ubuntu service that wasn't in CentOS? I've shared many posts about superpower observability tools, but often humble hacking is just as effective. in total.
In addition to hardware and software expenses, costs also include the infrastructure needed to support these systems — like sensors, IoT devices, upgraded network capabilities, and robust cybersecurity measures.
In the latest (October 2016) revision of Intel’s Instruction Extensions Programming Reference , Intel has disclosed a fairly dramatic departure from these “traditional” approaches. With 2 FMA units that have 5-cycle latency, the code must implement at least 2*5=10 independent accumulators in order to avoid stalls.
HTML, CSS, images, and fonts can all be parsed and run at near wire speeds on low-end hardware, but JavaScript is at least three times more expensive, byte-for-byte. If you or your company are able to generate a credible worldwide latency estimate in the higher percentiles for next year's update, please get in touch.
SQL provides a declarative programming interface, below which the system itself can figure out the most effective execution plans based on data size and statistics, layout, compute hardware etc. Be careful what you ask for (materialize). Recursive learning in SQL.
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. Example 1: Hardware failure (CPU board) Battery backup on the caching controller maintained the data. Important Always consult with your hardware manufacturer for proper stable media strategies.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Was there some other program consuming CPU, like a misbehaving Ubuntu service that wasn't in CentOS? As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content