This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. This leads to a more efficient and streamlined experience for users.
This means that Dynatrace continues full operation when a majority of nodes are up and a maximum of two nodes are down at a time. The network latency between cluster nodes should be around 10 ms or less. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. As a bonus, operations staff never needs to update operatingsystems or hardware, because AWS manages servers with no stoppage of application functionality. How does AWS Lambda work?
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers. I hope this helps!
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Failures are a given and everything will eventually fail over time: from routers to hard disks, from operatingsystems to memory units corrupting TCP packets, from transient errors to permanent failures. This is a given, whether you are using the highest quality hardware or lowest cost components. Primitives not frameworks.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. By implementing data replication strategies, distributed storage systems achieve greater.
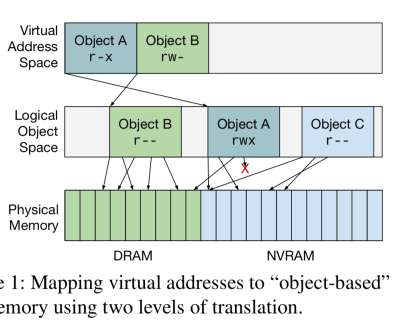
. …software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., This post is about a secondary performance characteristic — sustained memory bandwidth for a single thread running on a single core.
Software and hardware components are autonomous and execute tasks concurrently. Concurrency refers to the system’s ability to carry out multiple tasks in parallel and manage the access and usage of shared resources. This also includes latency, or the time it takes for data or a request to get through a network. Heterogeneity.
Whether it is to provide a base image with which to flash hardware in a hard reset, icons that get packaged with an application, or scripts that are intrinsically tied to the program at compilation time, there has always been a strong need to couple and ship binary data with an application. This can create variable latency during iteration.
This boils down to a single digit µs latency toleration in the tail for far memory, and in addition to security and privacy concerns, rules out remote memory solutions. Thus we’re fundamentally trading (de)-compression latency at access time for the ability to pack more data in memory.
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. When we work on a single machine, the operatingsystem takes care of managing the resources allocated to applications.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operatingsystems are designed, and the way applications operate on data. This means that the overheads of system calls become much more noticeable. in front of that memory , as we saw last week).
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. The paper focuses on two key use cases: A confined component running in its own security domain, connected to the rest of the system by explicit (e.g.
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. Most manufacturers' implementations immediately flush pending writes to physical disk during the restart operations. Important Always consult with your hardware manufacturer for proper stable media strategies.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., This post is about a secondary performance characteristic — sustained memory bandwidth for a single thread running on a single core.
In this blog post, we will discuss the best practices on the MongoDB ecosystem applied at the OperatingSystem (OS) and MongoDB levels. OperatingSystem (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100.
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. These may be performance, high availability, operational cost, management, capacity planning, scalability, security, monitoring, etc.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency.
Because of that big servers and other memory systems need to have another kind of memory in the hierarchy. SCM slots between DRAM and flash in terms of latency, cost, and density. Thus, despite both quoting 11 nines of durability against hardware failures, S3 is durable against failures that B2 is not, and is thus better.
Nowadays, the source code to old operatingsystems can also be found online. For everyone familiar with other operatingsystems and their CPU load averages, including this state is at first deeply confusing. **Why?** Here's an example: on an idle 8 CPU system, I launched tar to archive some uncached files.
Subsystem / Path The I/O subsystem or path includes those components that are used to support an I/O operation. Also, it is generally impractical on a production system.
A learning organization, disaster recovery testing, game days, and chaos engineering tools are all important components of a continuously resilient system. This discussion focuses on hardware, software and operational failure modes. Try to measure your mean time to respond (MTTR) for incidents.
A learning organization, disaster recovery testing, game days, and chaos engineering tools are all important components of a continuously resilient system. This discussion focuses on hardware, software and operational failure modes. Try to measure your mean time to respond (MTTR) for incidents.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Parsing and executing times vary significantly depending on the hardware of a device.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content