This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ is an open-source message broker that supports multiple messaging protocols , including AMQP, STOMP, MQTT, and RabbitMQ Streams. Apache Kafka is an open-source event streaming platform for high-volume, event-driven data processing. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
This is where Lambda comes in: Developers can deploy programs with no concern for the underlying hardware, connecting to services in the broader ecosystem, creating APIs, preparing data, or sending push notifications directly in the cloud, to list just a few examples. AWS continues to improve how it handles latency issues.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. Open-source solutions, such as OpenTelemetry , provide a de facto standard for collecting telemetry data in cloud settings.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
This key/value store acts as the single source of truth for all information on the cluster (state, and all changes to state transitions) are entered and stored here. To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures.
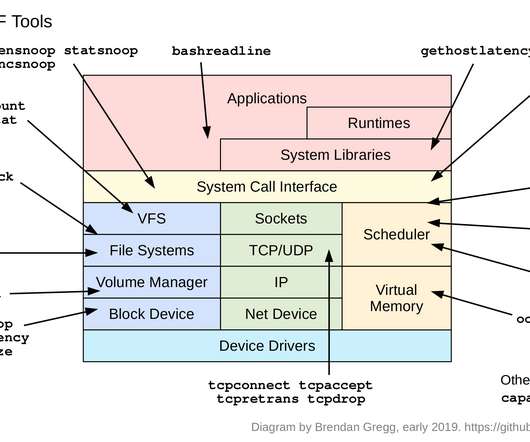
This was a chance to talk about other things I've been working on, such as the present and future of hardware performance. The video is on [youtube]: The slides are on [slideshare] or as a [PDF]: I work on many areas of performance, but recently I've had a lot of demand to talk about BPF. Ford, et al., “TCP
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. have been released since then with some major changes. Some servers may need a few GBs of RAM, while others may need hundreds of GBs or even terabytes of RAM.
At its core, Kubernetes (often abbreviated as K8s) is an opensource tool that automates the deployment, scaling, and management of containerized applications. Your workloads, encapsulated in containers, can be deployed freely across different clouds or your own hardware.
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among opensource options for effectively monitoring MySQL performance. Replication lag can occur due to various factors such as network latency, system resource limitations, complex transactions, or heavy write loads on the primary/master database.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Whether it is to provide a base image with which to flash hardware in a hard reset, icons that get packaged with an application, or scripts that are intrinsically tied to the program at compilation time, there has always been a strong need to couple and ship binary data with an application. This can create variable latency during iteration.
As noted previously the main developer of HammerDB is an Intel employee (#IAMINTEL) however HammerDB is a personal opensource project and any opinions are my own, specific to the context of HammerDB as an independent personal project and not representing Intel. hardware limits: 1000 MHz - 4.00 hardware limits: 1000 MHz - 4.00
Apple Corporate is at fault, not OpenSource engineers or the line managers who support them. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. is access to hardware devices. Some commenters appear to confuse unlike hardware for differences in software.
Breaking that assumption allowed Ceph to introduce a new storage backend called BlueStore with much better performance and predictability, and the ability to support the changing storage hardware landscape. But let’s take a quick look at the changing hardware landscape before we go on… The changing hardware landscape.
Lighthouse is an opensource project run by a dedicated team from Google Chrome. Estimated Input Latency. Estimated Input Latency. It’s time to come to terms that your customers aren’t using the same powerful hardware as you. What is Google Lighthouse? They are: Time to Interactive ( TTI ). Speed Index.
bpftrace is a new opensource tracer for Linux for analyzing production performance problems and troubleshooting software. For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. hardwareHardware counter-based instrumentation.
This was a chance to talk about other things I've been working on, such as the present and future of hardware performance. The video is on [youtube]: The slides are [here] or as a [PDF]: first prev next last / permalink/zoom I work on many areas of performance, but recently I've had a lot of demand to talk about BPF. Ford, et al., “TCP
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
Most existing adtech infrastructure simply can not achieve the required latency. VoltDB provides the necessary technology to achieve the latency required by header bidding. However, increasing hardware capacity doesn’t really solve the problem, and it introduces new ones. Another adtech infrastructure problem is capacity.
Most existing adtech infrastructure simply can not achieve the required latency. VoltDB provides the necessary technology to achieve the latency required by header bidding. However, increasing hardware capacity doesn’t really solve the problem, and it introduces new ones. Another adtech infrastructure problem is capacity.
The goal is to produce a low-energy hardware classifier for embedded applications doing local processing of sensor data. The resulting system can integrate seamlessly into a scikit-learn based development process, and dramatically reduces the total energy usage required for classification with very low latency. Introducing race logic.
To address this, the opensource community is now trying to develop Kubernetes custom schedulers specifically optimised for big data workloads. Using default scheduler's node affinity feature you can ensure that certain pods only schedule on nodes with specialized hardware like GPU, memory-optimised, I/O optimised etc.
software” rather than “hardware” in our brains). Unpredictable wait times : Wait times (latency) for ChatGPT’s responses are unpredictable, and there aren’t audio cues to help me establish an expectation for how long I need to wait before it responds.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Wait time: Sometimes called average latency, wait time refers the amount of time a request spends in a queue before it gets processed. Google Lighthouse Google Lighthouse is a free and opensource tool that is part of the Google Chrome DevTools family. Peak response time: The longest response time.
Additionally both commercial and opensource tools based on the specifications also continued to use TPC-C and TPC-H to describe these workloads. A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. But why is this important?
The CFQ works well for many general use cases but lacks latency guarantees. The deadline excels at latency-sensitive use cases ( like databases ), and noop is closer to no schedule at all. Percona’s opensource database monitoring tool monitors the health of your database infrastructure and helps you improve MongoDB performance.
Hardware access APIs, notably: Geolocation. iOS's security track record, patch velocity, and update latency for its required-use engine is not best-in-class. Opening these APIs to competing integrated browsers would pave the way to safer, faster, more capable computing for iPhone owners. Web OTP (for easier/faster sign-in).
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. Percona XtraBackup is a free, online, opensource, and complete database backup solution. Considering a Fully Managed DBaaS Offering For Your Business?
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency.
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
In each quantum of time, hardware and OS vendors press ahead, adding features. As OS and hardware deployed base integrate these components, the set of what most computers can do is expanded. This is often determined by hardware integration and device replacement rates.
This metric is important, but quite vague because it can include anything — starting from server rendering time and ending up with latency problems. All of this means that it will be more costly because of the growing hardware requirement and a little bit faster. And even then, you should keep in mind that because of the Node.js
This discussion focuses on hardware, software and operational failure modes. Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. Try to measure your mean time to respond (MTTR) for incidents.
This discussion focuses on hardware, software and operational failure modes. Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. Try to measure your mean time to respond (MTTR) for incidents.
dashboard (opensource), SpeedCurve and Calibre are just a few of them, and you can find more tools on perf.rocks. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. There are many tools allowing you to achieve that: SiteSpeed.io Large preview ).
dashboard (opensource), SpeedCurve and Calibre are just a few of them, and you can find more tools on perf.rocks. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Large preview ). There are many tools allowing you to achieve that: SiteSpeed.io
dashboard (opensource), SpeedCurve and Calibre are just a few of them, and you can find more tools on perf.rocks. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. There are many tools allowing you to achieve that: SiteSpeed.io Image credit: Addy Osmani ) ( Large preview ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content