This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As of September 2020, we run 51 clusters on 1100 EC2 instances distributed across six AWS Regions ensuring that all our users can leverage the Dynatrace Software Intelligence Platform to monitor their hybrid-multi cloud environments. Sydney, we have a disk write latency problem!
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency.
The network latency between cluster nodes should be around 10 ms or less. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios.
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams.
Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads. Monitoring the cluster nodes preemptively addresses potential issues, ensuring the system operates smoothly.
But with the benefits also come concerns about observability, and how to monitor and manage ever-expanding cloud software stacks. As a bonus, operations staff never needs to update operating systems or hardware, because AWS manages servers with no stoppage of application functionality. How do AWS Lambda functions impact monitoring?
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. When an application is triggered, it can cause latency as the application starts. This creates latency when they need to restart.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Computer operations manages the physical location of the servers — cooling, electricity, and backups — and monitors and responds to alerts. Functionality. Performance.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis, a powerful in-memory data store, is no exception.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. What is the difference between monitoring and observability? Is observability really monitoring by another name? In short, no.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Redis®, a powerful in-memory data store, is no exception.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN. million elements.
To make things worse, they’re also usually unsure whose responsibility performance measuring and monitoring is. You’re out on the world wide web—you have no idea who is turning up to the site, what their context is, what hardware, software, or infrastructure they’re using, or anything. How: RUM tooling, analytics, monitoring.
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with!
Setting up and monitoring these systems was pretty easy compared to today’s standards. There were no dynamic web applications or complex user scenarios to have to monitor. monitoring distributed systems becomes much more difficult to carry out and manage. Onto the next project. Gone are the days of monolithic architecture.
An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. This makes the whole system latency sensitive. Regular expression matching is well studied, but state of the art hardware algorithms don’t reach the performance and memory targets needed for Pigasus.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. All DBaaS management, monitoring, and maintenance tools are included in both plans, along with 24/7 support. Where to host your cloud database?
The agent allows Amazon ECS to communicate with the EC2 instances in the cluster to start, stop, and monitor containers as requested by a user or scheduler. To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures.
Website and Web Application Monitoring. Web monitoring is a comprehensive term that describes the activity of testing a website or web application for its availability and performance. HTTP Monitoring. HTTP monitoring allows you to test availability and performance from around the world. Network latency.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance. In this blog, we will explore various MySQL KPIs that are basic and essential to track using monitoring tools like PMM.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Monitoring. Benefits of a Serverless Model.
Last week we learned about the [increased tail-latency sensitivity of microservices based applications with high RPC fan-outs. Seer uses estimates of queue depths to mitigate latency spikes on the order of 10-100ms, in conjunction with a cluster manager. So what we have here is a glimpse of the limits for low-latency RPCs under load.
In traditional database architectures, database engines often run a small search engine or data warehouse engines on the same hardware as the database. No matter which mechanism you choose to use, we make the stream data available to you instantly (latency in milliseconds) and how fast you want to apply the changes is up to you.
Improved performance : MongoDB continually fine-tunes its database engine, resulting in faster query execution and reduced latency. You should also review your hardware resources, how you use MongoDB, and any custom configurations.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. By implementing data replication strategies, distributed storage systems achieve greater.
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. The following figure highlights how just one of these variables, batch size, impacts throughput and latency on ResNet50.
It is also important to monitor your server’s memory usage regularly to ensure that it is not being exhausted by the buffer pool. However, it’s important to note that the optimal value may vary depending on your specific workload and hardware configuration. 16) and monitoring the server’s performance.
Software services still require physical devices and hardware for them to function. An organization’s response to an incident, whether we are talking about downtime, security breaches or cyber-attacks, or even prolonged latency and repeated errors, is critical to the continued success of the business and trust from the customer or end user.
This boils down to a single digit µs latency toleration in the tail for far memory, and in addition to security and privacy concerns, rules out remote memory solutions. Thus we’re fundamentally trading (de)-compression latency at access time for the ability to pack more data in memory.
In addition, Kubernetes provides features like continuous monitoring, self-healing capabilities ( automatically replacing containers if they happen to fail ), and rolling updates ( gradual updates of your applications ), ensuring that your applications are always available — even in the face of failures or updates.
This article is from my friend Ben who runs Calibre , a tool for monitoring the performance of websites. Estimated Input Latency. Estimated Input Latency. Monitoring Time to Interactive. To successfully uncover significant differences in user experience, we suggest using a performance monitoring system (like Calibre !)
In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. degraded hardware, transient networking problem) or, more often, because of some change deployed by Netflix engineers that did not have the intended effect.
Let's talk about the elephant in the room; Serverless doesn't really mean that there are no Software or Hardware servers. Performance - Serverless Functions that are used less frequently may suffer from warmup response latency, where the infrastructure needs some time to deploy the function.
It is built as part of the platform-as-a-service environment which provides customers with additional monitoring and security for the product. Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. New Hardware Configuration for Provisioned Compute Tier. GB per vCore.
trying to reduce the amount of manual work and ensuring all the components (infrastructure/hardware, middleware, software, etc.) Monitoring. As part of the responsibility of an SRE, monitoring and observability are a key component of their duties. that are required to keep the software deployments live are running efficiently.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. About CXL hardware availability with academia.
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
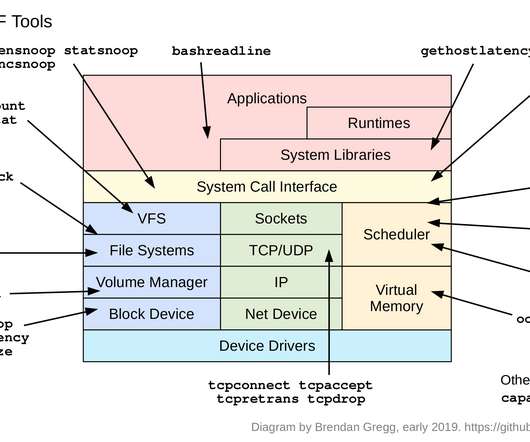
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. hardwareHardware counter-based instrumentation. Block I/O latency as a histogram.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. idle%-99.97
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Query plan analysis can also provide valuable insights.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content