This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
The methodology and algorithms were designed by Dynatrace with guidance from the Sustainable Digital Infrastructure Alliance (SDIA), expanding on formulas from the open source project Cloud Carbon Footprint. Green coding focuses on the software that is running on our digital infrastructure. Let’s take some of the mystery out of it.
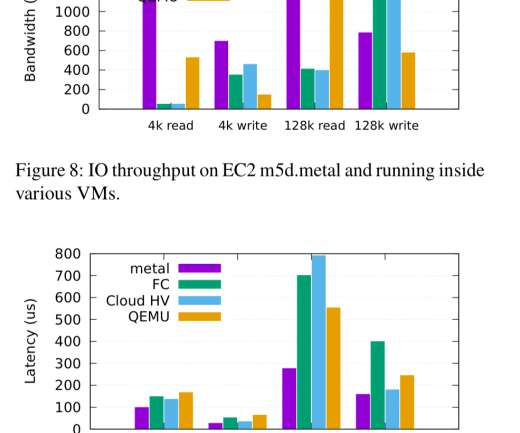
After years of optimizing traditional virtualization systems to the limit, we knew we had to make a dramatic change in the architecture if we were going to continue to increase performance and security for our customers.
With this solution, customers will be able to use Dynatrace’s deep observability , advanced AIOps capabilities , and application security to all applications, services, and infrastructure, out-of-the-box. This means you no longer have to procure new hardware, which can be a time-consuming and expensive process.
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
Instead, enterprises manage individual containers on virtual machines (VMs). Enterprises can deploy containers faster, as there’s no need to test infrastructure or build clusters. PaaS focuses on code stack infrastructure, while CaaS offers more customization and control over applications and services. CaaS vs. PaaS.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Accordingly, the remaining 27% of clusters are self-managed by the customer on cloud virtual machines.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. ITOps is an IT discipline involving actions and decisions made by the operations team responsible for an organization’s IT infrastructure.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
Dynatrace can help customers monitor, troubleshoot, and optimize application performance for workloads operating on AWS Outposts, in AWS Regions, and on customer-owned hardware for a truly consistent hybrid experience.”. All-in-one, AI-powered monitoring of AWS applications and infrastructure. What is AWS Outposts?
The IT infrastructure and services will reach $35.98 To address this need, the integration of cloud computing and virtualization has emerged as a groundbreaking solution as these technologies boast scalability and flexibility, entirely transforming the operational landscape. billion by 2025.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources.
Virtualization has emerged as a crucial tool for businesses looking to manage their IT infrastructure with greater efficiency, flexibility, and cost-effectiveness in today’s rapidly changing digital environment. Microsoft’s Hyper-V is a top virtualization platform that enables companies to maximize the use of their hardware resources.
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead.
Hyper-V, Microsoft’s virtualization platform, plays a crucial role in cloud computing infrastructures, providing a scalable and secure virtualization foundation. By leveraging Hyper-V, cloud service providers can optimize hardware utilization by running multiple virtual machines (VMs) on a single physical server.
Are you comfortable setting up your own cloud infrastructure through AWS or Azure? This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. Do you want to deploy in an AWS VPC or Azure VNET? Expert Tip.
As organizations expand their cloud footprints, they are combining public, private, and on-premises infrastructures. But modern cloud infrastructure is large, complex, and dynamic — and over time, this cloud complexity can impede innovation. Dynatrace news. As a result, VA had to rapidly scale its on-premises Citrix environment.
Understanding KVM Kernel-based Virtual Machine (KVM) stands out as a virtualization technology in the world of Linux. Embedded within the Linux kernel, KVM empowers the creation of VMs with their virtualizedhardware components, such as CPUs, memory, storage, and network cards, essentially mimicking a machine.
After years of optimizing traditional virtualization systems to the limit, we knew we had to make a dramatic change in the architecture if we were going to continue to increase performance and security for our customers.
One initial, easy step to moving your SQL Server on-premises workloads to the cloud is using Azure VMs to run your SQL Server workloads in an infrastructure as a service (IaaS) scenario. One important choice you will still have to make is what type and size of Azure virtual machine you want to use for your existing SQL Server workload.
For our migration projects, we simply roll out Dynatrace OneAgents on the existing infrastructure. Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. For that, it is sufficient to only know host-2-host dependencies.
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Message queue software options to consider.
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Message queue software options to consider.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. It also supports the flexibility and scalability of the database infrastructure.
This is a given, whether you are using the highest quality hardware or lowest cost components. When customers left the constraining, old world of IT hardware and datacenters behind, they started to develop systems with new and interesting usage patterns that no one had ever seen before. Primitives not frameworks. No gatekeepers.
Chatbots and virtual assistants Chatbots and virtual assistants are becoming more common on websites and web applications as they provide an efficient and convenient way for users to interact with a business. These technologies can answer questions, provide customer support, or even complete transactions.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. What about computing infrastructure?
We have been working closely with our customers on their requests to bring the power of the Amazon Web Services cloud closer to their existing on-premises compute infrastructures. The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable.
Authorization and Access Control In RabbitMQ, authorization dictates the operations a user may execute on given virtual hosts. Virtual Hosts and Resource Permissions In RabbitMQ, virtual hosts craft distinct isolated environments that upgrade security and resource segregation by restricting inter-vhost communication.
Instead of diving in arguing about specific points (which I partly did in my earlier post – start from The Future of Performance Testing if you are interested), I decided to talk to people who monetize on these “myths” So here is a virtual interview with Guillaume Betaillouloux , co-founder and Performance Director of OctoPerf.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtualhardware. Without enough infrastructure (physical or virtualized servers, networking, etc.), there cannot be high availability.
The immediate (working) goal and requirements of HA architecture The more immediate (and “working” goal) of an HA architecture is to bring together a combination of extensions, tools, hardware, software, etc., No single-point-of-failure (SPOF) : This is both an exclusion and an inclusion for the architecture.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) Tenant isolation is achieved by provisioning a separate virtual warehouse (VW) for each tenant. From shared-nothing to disaggregation. Elasticity.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
The layers of platforms start at the bottom with hardware choices such as which CPU architectures and vendors you want to use. The virtualization and networking platform could be datacenter based, with something like VMware, or cloud based using one of the cloud providers such as AWS EC2.
Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. of users) report that “infrastructure issues” are an issue. We’ll say more about this later.) of nonusers, 5.4%
HA in PostgreSQL databases delivers virtually continuous availability, fault tolerance, and disaster recovery. No single point of failure (SPOF): If the failure of a database infrastructure component could cause downtime, that component is considered an SPOF. It can be done by building the HA infrastructure within a single data center.
These systems can include physical servers, containers, virtual machines, or even a device, or node, that connects and communicates with the network. Software and hardware components are autonomous and execute tasks concurrently. State is distributed through the system. Concurrency. Heterogeneity. Fault Tolerance.
These services also require the ability to scale infrastructure incrementally to accommodate growth in request rates or dataset sizes. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer.
It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based. and we may have been flying close to the edge of hardware cache warmth, where adding a bit more instructions caused a big drop.
Both concepts are virtually omnipresent and at the top of most buzzword rankings. The management consultants at McKinsey expect that the global market for AI-based services, software and hardware will grow annually by 15-25% and reach a volume of around USD 130 billion in 2025. More room for optimism.
Vertical scaling is also often discussed, which involves increasing the resources of a single server, which can have limitations in hardware capabilities and become costly as demands grow. 2) Hardware limitations Disk and memory are inexpensive nowadays. An example is running MongoDB on Mesos.
To move as fast as they can at scale while protecting mission-critical data, more and more organizations are investing in private 5G networks, also known as private cellular networks or just “private 5G” (not to be confused with virtual private networks, which are something totally different). billion in 2022. billion, growing 48.2%
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content