This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the webinar “ Intelligent Kubernetes observability and automation ,” Dynatrace expert Henrik Rexed and GCP experts Gari Singh and Alisha Stull provide insights into leveraging AI-powered observability and automation to gain granular insights into Kubernetes environments on Google Cloud Platform at an enterprise scale.
Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
In this post, I wanted to share how I use Google Analytics together with Dynatrace to give me a more complete picture of my customers, and their experience across our digital channels. Google Analytics. Almost all marketers will be familiar with Google Analytics. Dynatrace – understanding customer experience. Thanks, Davis!
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. What is Docker? Networking.
These items are the fruits of those ideas, the items I deemed worthy from my Google Reader feeds. Making Google’s CalDAV and CardDAV APIs available for everyone ( Google Developers Blog). Improving testing by using real traffic from production ( Hacker News). History of Lisp ( Hacker News). Java EE 7 is Final.
For example, to handle traffic spikes and pay only for what they use. Observability is essential to ensure the reliability, security and quality of any software system. Scale automatically based on the demand and traffic patterns. The elasticity of serverless services helps organizations scale as needed.
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. Istio is a popular Kubernetes-native mesh developed by Google, IBM, and Lyft that helps manage deployments, breeds resilience, and improves security in Kubernetes.
As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. For most systems, an optimum MTTR could be less than one hour while others have an MTTR of less than one day.
Although the APIs were all managed by the Google API manager Apigee, the bank group was not getting consistent data types from the output. This restriction made it impossible to totally export all traces from Apigee unless the sampling rate was below the maximum, in which case they could use Google Cloud Trace.
You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events. One change to send syslog to Dynatrace You can now use the syslog ingestion endpoint on Dynatrace Environment ActiveGate for performant network and system monitoring.
Malicious attackers have gotten increasingly better at identifying vulnerabilities and launching zero-day attacks to exploit these weak points in IT systems. A zero-day exploit is a technique an attacker uses to take advantage of an organization’s vulnerability and gain access to its systems.
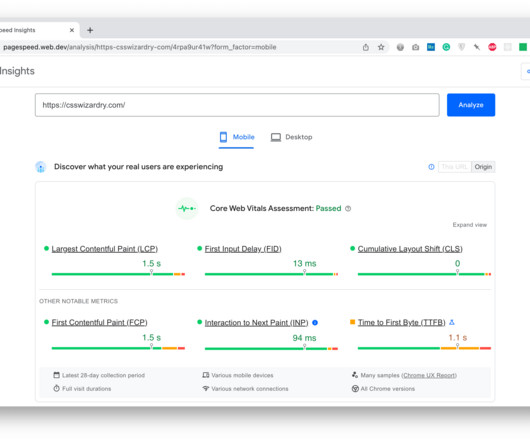
Google’s Core Web Vitals initiative was launched in May of 2020 and, since then, its role in Search has morphed and evolved as roll-outs have been made and feedback has been received. However, to this day, messaging from Google can seem somewhat unclear and, in places, even contradictory. Don’t have time to read 5,500+ words?
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. Five example SLOs for faster, more reliable apps 1. The Apdex score of 0.85
According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
Every organization’s goal is to keep its systems available and resilient to support business demands. Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Dynatrace news. A world of misunderstandings.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems. More than one in seven outages cost more than $1 million.
Almost two decades ago, a Google experiment showed that fast-loading transactions are more important to customers than content quality—even small increases in transaction delay result in substantially more abandoned sessions. IT teams spend months preparing for the peak traffic they anticipate will arrive with holiday shopping.
However, they are scattered across multiple systems, and there isn’t an easy way to tie related messages together. You’re joining tables, resolving status types, cross-referencing data manually with other systems, and by the end of it all you ask yourself why? Things got hairy. We wanted a scalable service that was near real-time, 2.
Due to its popularity, the number of workflows managed by the system has grown exponentially. We started seeing signs of scale issues, like: Slowness during peak traffic moments like 12 AM UTC, leading to increased operational burden. The scheduler on-call has to closely monitor the system during non-business hours.
In their case, this is specifically about the pensions element of their platform which had seen 6-7x as much traffic during the pandemic. The first thing the team did was make sure system performance and responsiveness were front of mind and visible to all stakeholders. What is the next set of challenges?
That’s a significant amount and certainly more than is necessary relative to the traffic on most clusters. More acutely, if a traffic spike occurs and Zuul instances scale up, it exponentially increases connections open to origins. Subsetting was also top of mind after reading a recent ACM paper published by Google.
First, it helps to understand that applications and all the services and infrastructure that support them generate telemetry data based on traffic from real users. With saturation, we try to measure overall system utilization, which you can obtain from host metrics such as CPU and memory usage. So how can teams start implementing SLOs?
based sample service in a staging and production namespace, a Jenkins instance and execute some moderate load to “simulate constant production traffic”. A quick google search reveals several articles on Prometheus performance optimizations we should look into. kubectl delete statefulset prometheus-system -n knative-monitoring.
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. A big factor in good Digital Performance is the back-end system that powers your digitally offered use-cases.
Synthetic CI/CD testing simulates traffic to add an outside-in view to the analysis. SREs visualize the state of the system they’re responsible for with powerful Dynatrace dashboards. DORA stands for the DevOps Research and Assessment team, a Google-headed project tasked with analyzing DevOps practices.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. Availability is typically expressed in 9’s, such as 99.9%. The Apdex score of 0.85
The top 1000 channels from each service are analysed using a custom-built crawling engine, and traffic is intercepted where possible using mitmproxy. Where possible the authors use mitmproxy to intercept traffic from the devices. On Roku TV, the most prevalent tracker is for Google’s doubleclick.net (975/1000 channels).
Never inflict a distributed system on yourself unless you have too." vl : I have a hilarious story about this from Google: I wanted second 30" monitor, so I filed a ticket. seconds with the system. Hey, it's HighScalability time: @danielbryantuk : "A LAMP stack is a good thing. mipsytipsy #CloudNativeLondon. There more.
Last month, TheNew York Times claimed that tech giants OpenAI and Google have waded into a copyright gray area by transcribing the vast volume of YouTube videos and using that text as additional training data for their AI models despite terms of service that prohibit such efforts and copyright law that the Times argues places them in dispute.
Systems are constantly changing, with pods existing only briefly to perform tasks before they’re terminated. In such circumstances, it’s challenging to investigate the reasons for unexpected behavior or traffic between pods. Online Boutique has been launched into a Kubernetes cluster that runs in Google Kubernetes Engine (GKE).
And the last thing you want to do with synthetic is introduce false positives (the bane of all synthetic testing) into the system, and yet this was happening too often. With Cloud, we are leveraging the largest cloud providers’ locations, including AWS, Azure, Alibaba and Google coming very soon. Some customers do but most do not.
Unwelcome Gaze is a triptych visualizing the publicly reachable web server infrastructure of Google, Facebook, Amazon and the routing graph(s) leading to them. Sheera Frenkel : “We’re not going to traffic in your personal life,” Tim Cook, Apple’s chief executive, said in an MSNBC interview. ” (Mr.
Over the past months, we’ve also worked very closely with Google to bring new SLO capabilities into our Software Intelligence Platform to enable all our users to scale their SRE practices. Read more: Google’s definition of the term Site Reliability Engineering. Release decision making with Service-Level Objectives (SLOs).
Site Reliability Engineering (SRE) has grown immensely popular with many of the world’s largest tech companies, like Netflix, LinkedIn and Airbnb employing SRE teams to keep their systems reliable and scalable.
Upcoming Operating systems support changes. The following operating systems will no longer be supported starting 01 February 2021. The following operating systems will no longer be supported starting 01 May 2021. The following operating systems will no longer be supported starting 01 May 2021. Linux: Ubuntu 19.10.
Meanwhile, on Android, the #2 and #3 sources of web traffic do not respect browser choice. Google's Search App and Facebook's various apps for Android undermine these choices in slightly different ways. [3] Developers also suffer higher costs and reduced opportunities to escape Google, Facebook, and Apple's walled gardens.
50 ways to leak your data: an exploration of apps’ circumvention of the Android permissions system Reardon et al., Side-channels are typically an unintentional consequence of a complicated system. Google, to their credit, have announced that they are addressing many of the issues that we reported to them. most apps).
Using Test My Site from Think with Google : Gives you an estimation of potential revenue increase for your site when saving loading time. It’s important to track these conversion events, and you can do it in your own system or leveraging tools like Google Analytics or Facebook Analytics. Screenshot of Google's Test My Site page.
Now that Google uses page speed as a ranking factor, many organizations have become laser-focused on performance. Last year, Google made two significant changes to their search indexing and ranking algorithms : In March, indexing became based on the mobile version of a page , rather than desktop. What is Google Lighthouse?
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. We will deep dive into Data Delivery and Data Consumption in the following sections.
According to StatCounter , as of December 2020, mobile traffic has surpassed desktop traffic with 55.73% of traffic coming from mobile devices. Originally created as an early fork of Angular by engineers at Google, Vue.js Angular Google's flagship JS framework, Angular , has been in development for quite some time.
Google’s Lighthouse is one of them, which shows information about PWA, SEO and more. presented in Google IO 2018 ( source ) These tools make it easier to determine where we need to put emphasis to improve our sites. They can be run as a one-off or integrated in our development and deployment pipelines. A screenshot of Lighthouse 3.0,
Top features to include in apps that are similar to Google Maps The most popular map and navigation app in the US in 2021 was Google Maps. Why is Google Maps the most widely used navigational tool? Google, a major player in technology, is where it starts. Is your program similar to Google Maps in certain ways?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content