This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable. Get to the root cause of issues Most AI today uses machine learning models like neural networks that find correlations and make predictions based on them.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. Networking.
According to the Kubernetes in the Wild 2023 report, “Kubernetes is emerging as the operating system of the cloud.” ” In recent years, cloud service providers such as Amazon Web Services, Microsoft Azure, IBM, and Google began offering Kubernetes as part of their managed services. Networking. Ease of use.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls. Potential for decreased reliability.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls. Potential for decreased reliability.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks?
Containers enable developers to package microservices or applications with the libraries, configuration files, and dependencies needed to run on any infrastructure, regardless of the target system environment. This orchestration includes provisioning, scheduling, networking, ensuring availability, and monitoring container lifecycles.
Decentralized systems will continue to lose to centralized systems until there's a driver requiring decentralization to deliver a clearly superior consumer experience. For all the idealistic technical reasons I laid out long ago in Building Super Scalable Systems: Blade Runner Meets Autonomic Computing In The Ambient Cloud.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. NoSQL database.
The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel. Typically an MPP system has one leader node and one or many compute nodes. This allows Greenplum to distribute the load between their different segments and use all of the system’s resources parallely to process a query.
When I worked at Google, fleet-wide profiling revealed that 25-35% of all CPU time was spent just moving bytes around: memcpy, strcmp, copying between user and kernel buffers in network and disk I/O, hidden copy-on-write in soft page faults, checksumming, compressing, decrypting, assembling/disassembling packets and HTML pages, etc.
As the most widely used logging framework on the internet, Apache Log4j 2 is integrated into myriad applications, used on major cloud services such as Apple, Google, Microsoft and Cloudflare, as well as platforms like Twitter and Stream. How Log4j 2 can be exploited depends on the specifics of the affected system.
Every organization’s goal is to keep its systems available and resilient to support business demands. Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Dynatrace news. A world of misunderstandings.
The control plane also provides an API so operators can easily manage traffic control, network resiliency, security and authentication, and custom telemetry data for each service. A service mesh enables DevOps teams to manage their networking and security policies through code. Why do you need a service mesh?
These containers are software packages that include all the relevant dependencies needed to run software on any system. Container-based software isn’t tied to a platform or operating system, so IT teams can move or reconfigure processes easily. Process portability. Faster deployment. CaaS vs. IaaS. CaaS vs. FaaS.
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. When an application runs on a single large computing element, a single operating system can monitor every aspect of the system. Dynamic applications with ephemeral services.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. It provides valuable insight into complex public, private, and hybrid cloud IT structures, systems, and frameworks.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Infrastructure as a service (IaaS) handles compute, storage, and network resources. How does function as a service work? But how does FaaS fit in?
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. Enter Google! Pony Express, as we saw earlier, is a ground-up implementation of networking primitives. SOSP’19.
Google built BigTable, Amazon built Dynamo, Facebook built Cassandra, LinkedIn came up with Voldemort. From Udi Dahan's free Distributed Systems Design Fundamentals video course Semantic interoperability The true challenge of non-homogenous networks lies in semantic interoperability. How do we integrate these two systems?
Malicious attackers have gotten increasingly better at identifying vulnerabilities and launching zero-day attacks to exploit these weak points in IT systems. A zero-day exploit is a technique an attacker uses to take advantage of an organization’s vulnerability and gain access to its systems. half of all corporate networks.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity. Make SLOs realistic.
According to Forrester Research, the COVID-19 pandemic fueled investment in “hyperscaler public clouds”—Amazon Web Services (AWS), Google Cloud Platform and Microsoft Azure. According to a data from Dimensional Research, 95% of respondents say visibility problems have prompted an application or network performance issue.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. The Kubernetes experience.
at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings. One more embellishment is to use a graph neural network (GNN) trained on the documents.
Although Kubernetes simplifies application development while increasing resource utilization, it is a complex system that presents its own challenges. It automates complex tasks during the container’s life cycle, such as provisioning, deployment, networking, scaling, load balancing, and more. Who manages the networking aspects?
Containers and Microservices: R evolution in the architecture of distributed systems . ? refers to cloud-based, containerized, distributed systems, made up of cooperating microservices, dynamically managed by automated infrastructure as code. . ? Who manage s the networking aspects? GKE (Google Cloud Platform) .
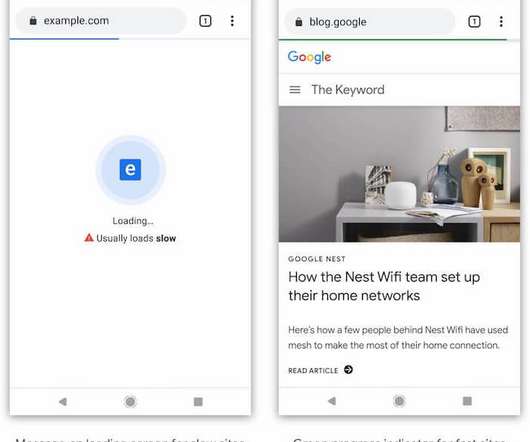
Google has announced plans for a new badging system that would let users know whether a website typically loads slowly. With its search engine being easily the most used on the internet, Google has an incredible influence on the web. Most stemmed from Google exercising too much power with this move.
Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner. The solution starts with observability, enabling organizations to measure the system states based on their logs, metrics, and traces.
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate. This awareness is important when the goal is to drive cost-conscious engineering.
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts.
After American Family completed its initial conversion to Dynatrace, they needed to automate how their system ingested Amazon CloudWatch metrics. Once the accounts are set up in Dynatrace, the system queries Amazon CloudWatch for new metrics every five minutes. Step 1: Automate AWS metrics ingestion with Dynatrace.
In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). Is it the WSO2-AM gateway itself, a networking issue, a sudden increase in demand, or something else entirely?
As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. For most systems, an optimum MTTR could be less than one hour while others have an MTTR of less than one day.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Google Core Web Vitals : Largest Contentful Paint, First Input Delay, and Cumulative Layout Shift (specifically for web). User experience score.
That happens for both vertical dependencies (host, processes, services, applications) as well as vertical dependencies (process to process through network monitoring, service to service through automated tracing). A quick google search reveals several articles on Prometheus performance optimizations we should look into.
This was caused by a config update by a security company for their widely used product that included a kernel driver on Windows systems. For Linux systems, the company behind this outage was already in the process of adopting eBPF, which is immune to such crashes. Meta, Isovalent, Google) and academia (e.g.,
Five years ago when Google published The Datacenter as a Computer: Designing Warehouse-Scale Machines it was a manifesto declaring the world of computing had changed forever. Since then the world has chosen to ride along with Google. If you like this kind of stuff, you might also like Google's New Book: The Site Reliability Workbook.
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. A big factor in good Digital Performance is the back-end system that powers your digitally offered use-cases.
Golang is a statically, strongly typed, compiled, concurrent, and garbage-collecting programming language developed by Google. Its concurrency mechanism makes it easy to write programs that maximize the use of multicore and network machines, and its innovative type system enables flexible and modular program construction.
Google’s Lighthouse is one of them, which shows information about PWA, SEO and more. presented in Google IO 2018 ( source ) These tools make it easier to determine where we need to put emphasis to improve our sites. Simulate bad network conditions and slow CPUs and make your project resilient. A screenshot of Lighthouse 3.0,
Never inflict a distributed system on yourself unless you have too." vl : I have a hilarious story about this from Google: I wanted second 30" monitor, so I filed a ticket. seconds with the system. Hey, it's HighScalability time: @danielbryantuk : "A LAMP stack is a good thing. mipsytipsy #CloudNativeLondon. There more.
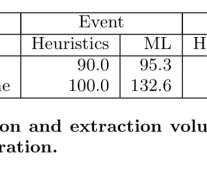
Migrating a privacy-safe information extraction system to a software 2.0 This is a comparatively short (7 pages) but very interesting paper detailing the migration of a software system to a ‘Software 2.0’ we spend the majority of our effort on writing code, expressing how the system achieves its goals.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content