This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. And now you do.
In this post I want to look at how CSS can prove to be a substantial bottleneck on the network (both in itself and for other resources) and how we can mitigate it, thus shortening the Critical Path and reducing our time to Start Render. Employ Critical CSS. If you’re working with a large or legacy codebase, things get even more difficult….
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. by Google Core Web Vitals is?certainly?valuable,?it?leaves
There are a lot of cool nuggets in Google's New Book: The Site Reliability Workbook. Prior to launch, they load-tested their software stack to process up to 5x their most optimistic traffic estimates. In addition, many engineers across Google provided their assis? Niantic launched Pokémon GO in the summer of 2016.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. When handling large amounts of complex data, or big data, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum Advantages.
Here’s why: Complex configuration management 30% of all cloud environment attacks during the first half of 2024 used misconfigurations as the initial access vector” – Google Cloud Threat Horizons report. Addressing these challenges proactively is critical to maintaining a secure and efficient cloud infrastructure.
How To Monitor And Optimize Google Core Web Vitals How To Monitor And Optimize Google Core Web Vitals Matt Zeunert 2024-04-16T10:00:00+00:00 2024-04-16T12:05:36+00:00 This article is sponsored by DebugBear Google’s Core Web Vitals initiative has increased the attention website owners need to pay to user experience.
Core Web Vitals are a Google search ranking factor. Given that Google continues to dominate search usage, you should care about Vitals alongside the other metrics you should be tracking. Image size is another issue, as excessive image weight hurts your SEO ranking in Google Image Search. How does page bloat hurt Core Web Vitals?
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls.
Simplified image management with our Harbor and Jenkins integration We’re excited to introduce our latest setup, aimed at streamlining the process of pushing images to Harbor. The setup can be further distributed to multiple other registries, like ECR or Azure/Google container registries.
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? This process enables you to continuously evaluate software against predefined quality criteria and service level objectives (SLOs) in pre-production environments.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA automates repetitive cloud operations tasks and streamlines the flow of analytics into decision-making processes.
Management processes make up the control plane, which coordinates the proxies’ behavior. The control plane also provides an API so operators can easily manage traffic control, network resiliency, security and authentication, and custom telemetry data for each service. Why do you need a service mesh?
With the significant growth of container management software and services, enterprises need to find ways to simplify the process. CaaS automates the processes of hosting, deploying, and managing container technologies. Process portability. IaaS provides direct access to compute resources such as servers, storage, and networks.
But managing the deployment, modification, networking, and scaling of multiple containers can quickly outstrip the capabilities of development and operations teams. Container orchestration is a process that automates the deployment and management of containerized applications and services at scale. What is container orchestration?
Annie leads the Chrome Speed Metrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty Speed Metrics team at Google. Nice job, everyone!
However, many teams struggle with knowing which ones to use and how to incorporate them into the processes. Below, several Dynatrace customers shared their SLO management journey and discussed the resulting dashboards they rely on daily to manage their mission-critical business processes and applications. What are SLOs? Saturation.
Historically, I’d maybe look at Google Analytics—or a RUM solution if the client had one already—but this is only useful for showing me particular outliers, and not necessarily any patterns across the whole project. against many other metrics as other milestones (except CLS) are network-bound and TBT is CPU-bound. See entry 6.
This, in turn, accelerates the need for businesses to implement the practice of software automation to improve and streamline processes. Consider how AI-enabled chatbots such as ChatGPT and Google Bard help DevOps teams write code snippets or resolve problems in custom code without time-consuming human intervention. Operations.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. Enter Google! Pony Express, as we saw earlier, is a ground-up implementation of networking primitives. SOSP’19.
Proactive cost alerting Proactive cost alerting is the practice of implementing automated systems or processes to monitor financial data, identify potential issues or anomalies, ensure compliance, and alert relevant stakeholders before problems escalate. This awareness is important when the goal is to drive cost-conscious engineering.
Keptn is currently leveraging Knative and installs Knative as well as other depending components such as Prometheus during the default keptn installation process. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes. There was no other process that showed any abnormal resource consumption.
For example, if one of your customers unexpectedly uploaded a 1 GB file instead of a 1 MB file, was there an error with the buffer overflowing, or was the network stack unable to handle the unexpected load? Even more importantly, how was the error handled, and did the process end successfully for the customer?
By automating and accelerating the service-level objective (SLO) validation process and quickly reacting to regressions in service-level indicators (SLIs), SREs can speed up software delivery and innovation. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity.
Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner. Orchestrate processes and workloads between environments. Governance of standardized processes.
The web of dependencies among affected platforms and services means patching can be a complex and possibly time-consuming process. In the consumer sector, Log4j 2 can also be found in network-enabled storage and smart home equipment, which users should disconnect from the Internet until updates are available.
at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., While the overall process may be more complicated in practice, this is the gist. One more embellishment is to use a graph neural network (GNN) trained on the documents. at Facebook—both from 2020.
What I got back were two artifacts, one of them being the following video of Akamai web performance expert Robin Marx speaking at We Love Speed in France a few weeks ago: The other artifact is a Google document originally published by Patrick Meenan in 2015 but updated somewhat recently in November 2023. js"></script> <!
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. Before starting any migration project, you must have a good overview of all your hosts, processes, services and technologies. Also accessible through the Smartscape API.
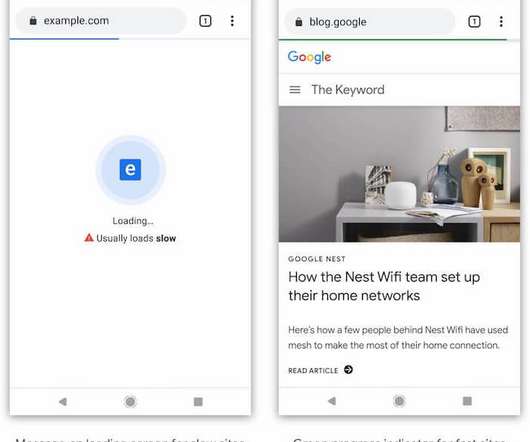
Google has announced plans for a new badging system that would let users know whether a website typically loads slowly. In a post detailing the thought process behind the planned feature, the Chrome team explains that “In the future, Chrome may identify sites that typically load fast or slow for users with clear badging ”.
It automates complex tasks during the container’s life cycle, such as provisioning, deployment, networking, scaling, load balancing, and more. DevOps and continuous delivery: A revolution in processes, and the way people and software delivery teams work. Who manages the networking aspects? How do you make it scalable?
While speeding up development processes and reducing complexity does make the lives of Kubernetes operators easier, the inherent abstraction and automation can lead to new types of errors that are difficult to find, troubleshoot, and prevent. 60 seconds to self-upgrading observability on Google Kubernetes Engine. Business layer.
The intelligent AI engine instantly processes billions of dependencies for precise answers, prioritizing them by business impact and including root-cause determination for issues. Then, the team set up the provisioning process to include this IAM role in any new AWS account. It also supports custom integrations for APIs.
Google’s Lighthouse is one of them, which shows information about PWA, SEO and more. presented in Google IO 2018 ( source ) These tools make it easier to determine where we need to put emphasis to improve our sites. Simulate bad network conditions and slow CPUs and make your project resilient. A screenshot of Lighthouse 3.0,
In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). Is it the WSO2-AM gateway itself, a networking issue, a sudden increase in demand, or something else entirely?
OneAgent implements network zones to create traffic routing rules and limit cross-data-center traffic. Dynatrace OneAgent also has built-in Adaptive Traffic Management to ensure high-fidelity data capture while keeping network traffic low. – Sergey Kanzhelev (Google). Your feedback is highly appreciated. What’s next.
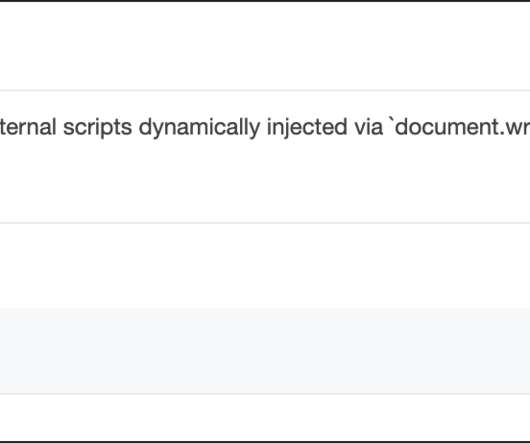
The Preload Scanner and the primary parser begin processing the HTML at more-or-less the same time, so the Preload Scanner doesn’t really get much of a head start. As well as exhibiting unpredictable and buggy behaviour as keenly stressed in the MDN and Google articles , document.write() is slow. Avoid document.write().
Your next challenge is ensuring your DevOps processes, pipelines, and tooling meet the intended goal. Let’s start with the four most common metrics Google’s DevOps Research and Assessment (DORA) team established known as “ The Four Keys.” This metric gauges the stability and efficiency of your DevOps processes.
Cloud application security is a combination of policies, processes, and controls that aim to reduce the risk of exposing cloud-based applications to compromise or failure from external or internal threats. This process can delay deployments or cause developers to skip security testing completely to meet project deadlines.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
DevOps and Continuous delivery: R evolution in the process, the way people and organizations delivering software work . Who manage s the networking aspects? I f there was any company that was positioned to understand those problems and limitations of containers before anyone else, it was Google. . ? Cloud-native?
To once again push the boundaries of automatic, AI-based Kubernetes monitoring, we’ve extended Smartscape, the Dynatrace real-time topology model, with visibility into how processes and containers communicate with each other in Kubernetes. process has shown up in the detected dependency graph. A new Node.js
When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore. Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. link] GetProduction returns a Production message by its unique ID.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content