This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
In the webinar “ Intelligent Kubernetes observability and automation ,” Dynatrace expert Henrik Rexed and GCP experts Gari Singh and Alisha Stull provide insights into leveraging AI-powered observability and automation to gain granular insights into Kubernetes environments on Google Cloud Platform at an enterprise scale.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. Built-in monitoring. What is Docker?
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
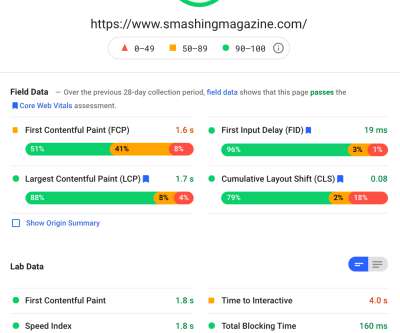
How To Monitor And Optimize Google Core Web Vitals How To Monitor And Optimize Google Core Web Vitals Matt Zeunert 2024-04-16T10:00:00+00:00 2024-04-16T12:05:36+00:00 This article is sponsored by DebugBear Google’s Core Web Vitals initiative has increased the attention website owners need to pay to user experience.
Complex syslog ecosystems can be challenging Monitoring devices and applications that provide output via the syslog protocol is a must-have for many organizations. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
For example, to handle traffic spikes and pay only for what they use. These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Scale automatically based on the demand and traffic patterns.
A website needs to be constantly tested and optimized to be in line with Google's web and SEO guidelines. As a result, it has an advantage over others in terms of visibility, brand image, and driving traffic. However, to tactically assess the website's performance , it needs to be measured in a well-thought-out manner.
Although the APIs were all managed by the Google API manager Apigee, the bank group was not getting consistent data types from the output. This restriction made it impossible to totally export all traces from Apigee unless the sampling rate was below the maximum, in which case they could use Google Cloud Trace.
Let’s start with the four most common metrics Google’s DevOps Research and Assessment (DORA) team established known as “ The Four Keys.” Anything that takes more than a day could indicate poor alerting or poor monitoring and can result in a larger number of affected systems. Application usage and traffic.
Such monitoring data is critical to providing satisfying digital experiences and services to customers. OpenTelemetry complements OneAgent by enabling you to: Enrich local monitoring data with project-specific additions (for example, using custom instrumentation to add business data or capture developer-specific diagnostics points).
SLOs cover a wide range of monitoring options for different applications. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. One template explicitly targets service performance monitoring.
The key to accomplishing both these goals is having effective mobile app monitoring that quickly identifies the root cause of performance issues. However, because organizations typically use multiple mobile monitoring tools, this process is often far more difficult than it should be. Organizations use multiple mobile monitoring tools.
Typically, organizations might experience abnormal scanning activity or an unexpected traffic influx that is coming from one specific client. Techniques such as statistics-based monitoring and behavior-based monitoring are also possible. Zero-day attacks can manifest in various subtle forms and are often difficult to detect.
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. Istio is a popular Kubernetes-native mesh developed by Google, IBM, and Lyft that helps manage deployments, breeds resilience, and improves security in Kubernetes.
Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand. The Apdex score of 0.85 This means that 99.5%
based sample service in a staging and production namespace, a Jenkins instance and execute some moderate load to “simulate constant production traffic”. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes. And it even monitors Prometheus and tells me what’s wrong with that deployment!
The Business Insights team at Dynatrace has been working with our largest Digital Experience Monitoring customers to help them turn the Core Web Vitals data they’re collecting with Dynatrace into actionable insights they can use to optimize pages ahead of this June 2021 change in Google’s search ranking algorithm.
Kubernetes (k8s) provides basic monitoring through the Kubernetes API and you can find instructions like Top 9 Open Source Tools for Monitoring Kubernetes as a “do it yourself guide”. End-user monitoring. Dynatrace news. For EKS – Amazon’s Kubernetes Service – you can get a preview of CloudWatch Container Insights.
In what follows, we explore some of these best practices and guidance for implementing service-level objectives in your monitored environment. First, it helps to understand that applications and all the services and infrastructure that support them generate telemetry data based on traffic from real users. Define SLOs for each service.
Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operate systems, and develop new functionality. The monitoring team set up the dashboard, so who owns violations? In this case, the customer offers a managed service that runs on Amazon Web Services, Microsoft Azure, and Google.
The practice uses continuous monitoring and high levels of automation in close collaboration with agile development teams to ensure applications are highly available and perform without friction. At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems.
The Dynatrace Software Intelligence Platform delivers all the necessary Service-Level Indicators (SLIs) for defining your Service-Level Objectives (SLOs) and monitors the status and error budgets of those objectives. The SLO wizard gives you guidance on creating SLOs based on the metrics (SLIs) Dynatrace monitors for your environment.
Almost two decades ago, a Google experiment showed that fast-loading transactions are more important to customers than content quality—even small increases in transaction delay result in substantially more abandoned sessions. IT teams spend months preparing for the peak traffic they anticipate will arrive with holiday shopping.
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
With Cloud, we are leveraging the largest cloud providers’ locations, including AWS, Azure, Alibaba and Google coming very soon. With most traffic coming from mobile for many of our customers, and the complexity of the “last mile,” do we really need to be troubleshooting core backbone ISP routing paths? Clearly that is the cloud.
Methods include the observability capabilities of the platforms their applications run on; monitoring tools, OpenTelemetry, OpenTracing, OpenMonitor, OpenCensus, Jaeger, Zipkin, Log, CloudWatch, and more. Just one command instruments your entire application environment for monitoring. Automatic topology analysis.
In such circumstances, it’s challenging to investigate the reasons for unexpected behavior or traffic between pods. Dynatrace is the only Kubernetes monitoring solution that provides continuous automation and full-stack automated observability without changing code, container images, or deployments. Seeing is believing.
Traffic The traffic SLO example measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand. The Apdex score of 0.85
How do you monitor and maintain a perfect digital experience for your customers when even a single interaction can touch hundreds of technologies? In their case, this is specifically about the pensions element of their platform which had seen 6-7x as much traffic during the pandemic. Dynatrace news. What is the next set of challenges?
vl : I have a hilarious story about this from Google: I wanted second 30" monitor, so I filed a ticket. . $2 billion : Pokémon GO revenue since launch; 10 : say happy birthday to StackOverflow; $148 million : Uber data breach fine; 75% : streaming music industry revenue in the US; 5.2 There more.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. Monitoring Performance.
Dynatrace’s Real User Monitoring (RUM) offering provides observability to every end-user that uses your mobile or web applications. This allows pulling or pushing mobile app ratings through the APIs that Google and Apple offer into Dynatrace. For availability, I always propose to use Dynatrace Synthetic vs looking at real user traffic.
Earlier this year, Google announced that Interaction to Next Paint (INP) is no longer an experimental metric. Because INP measures actual user interactions, it can only be monitored using a real user monitoring (RUM) tool. Safari users currently account for roughly 20% of global traffic. What is a 'good' INP number?
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. Dynatrace gave them automated insights into traffic behavior and the impact of queued up requests to the end-users (up to 3s queue time).
Google’s Lighthouse is one of them, which shows information about PWA, SEO and more. presented in Google IO 2018 ( source ) These tools make it easier to determine where we need to put emphasis to improve our sites. Performance monitoring should be effortless. A screenshot of Lighthouse 3.0, Calibre’s integration with Slack.
Increase the Google rankings of your web pages. Usage. This monitors certificate usage to verify that intermediate certificates are not misused. . While slow websites do not go down well with the users, in order to improve website traffic, security is also an important factor. This could result in a loss in site traffic.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
Linux: Google Container-Optimized OS 77 LTS. Resolved issue with deep monitoring of Go process because of incompatible ABI (added support for monitoring Go applications containing C code that uses TLS). Incorrectly merged PaaS hosts are now separated from monitored StatefulSets on OpenShift. x86 (64bit-only). ONE-42283).
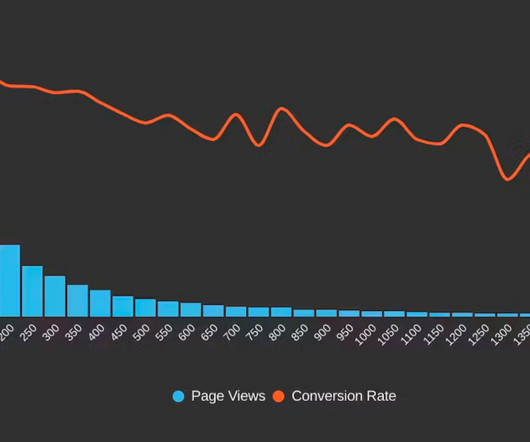
Correlation charts are generated using real user monitoring (RUM) data. They give you a histogram view of all your user traffic, broken out into cohorts based on performance metrics, such as Start Render, Largest Contentful Paint, Interaction to Next Paint, and more. That's a huge drop! For this site, the conversion rate plateaus at 2.8
We started seeing signs of scale issues, like: Slowness during peak traffic moments like 12 AM UTC, leading to increased operational burden. The scheduler on-call has to closely monitor the system during non-business hours. At Netflix, the peak traffic load can be a few orders of magnitude higher than the average load.
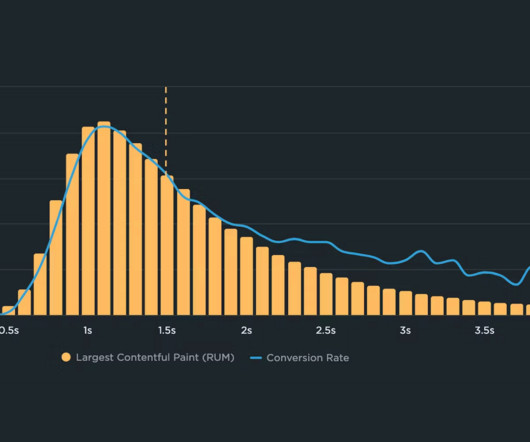
If your website is loading slowly, thats bad for user experience and can also cause your site to rank lower in Google. Google has been working to address that recently by introducing LCP subparts , which tell you where page load delays are coming from. According to Google, you should aim to eliminate resource load delay entirely.
This article is from my friend Ben who runs Calibre , a tool for monitoring the performance of websites. Now that Google uses page speed as a ranking factor, many organizations have become laser-focused on performance. What is Google Lighthouse? Lighthouse is an open source project run by a dedicated team from Google Chrome.
Google has announced that from 1st May, they will start to consider “Page Experience” as part of Search ranking , as measured by a set of metrics called Core Web Vitals. even the Google tools like PageSpeed Insights and the Core Web Vitals report in Google Search Console seem to give confusing information. Barry Pollard.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content