This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
See into cloud blind spots Versatile, feature-rich cloud computing environments such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform have been a game-changer, enabling DevOps teams to deliver greater capabilities on a wider scale.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. by Google Core Web Vitals is?certainly?valuable,?it?leaves
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
You’ve fired up Google Lighthouse from Chrome’s DevTools because everyone and their uncle uses it to evaluate performance. Except, don’t — at least not using Google Lighthouse as your sole proof. Google Lighthouse is merely one tool in a complete performance toolkit. That’s what we’re aiming for, after all!
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. Networking. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces.
Annie leads the Chrome Speed Metrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty Speed Metrics team at Google.
Thats why the Time to First Byte (TTFB) metric is important: it measures how soon after navigation the browser starts receiving the HTML response. But actually, theres a lot more to optimizing this metric. What Components Make Up The Time To First Byte Metric? TTFB stands for Time to First Byte. But where does it measure from ?
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business? SRG validates the status of the resiliency SLOs for the experiment period.
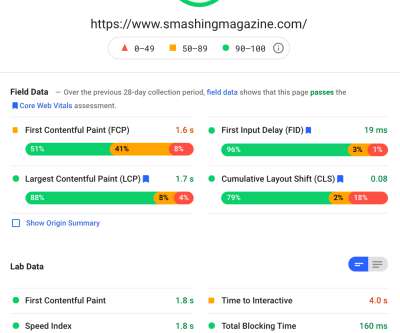
How To Monitor And Optimize Google Core Web Vitals How To Monitor And Optimize Google Core Web Vitals Matt Zeunert 2024-04-16T10:00:00+00:00 2024-04-16T12:05:36+00:00 This article is sponsored by DebugBear Google’s Core Web Vitals initiative has increased the attention website owners need to pay to user experience.
This greatly reduced the number of metrics to manage and provided a more comprehensive picture of what was behind their primary reliability service-level objective. This represents the total number of requests across the network. This refers to the load on your network and servers. This is the number of requests that fail.
In the latest enhancements of Dynatrace Log Management and Analytics , Dynatrace extends coverage for Native Syslog support: Use Dynatrace ActiveGate to automatically add context and optimize network traffic to your Syslog messages.
” In recent years, cloud service providers such as Amazon Web Services, Microsoft Azure, IBM, and Google began offering Kubernetes as part of their managed services. The managed service runs on public clouds such as Amazon Web Services and Google Cloud. Networking. Kubernetes provides a basic networking model.
As a result, site reliability has emerged as a critical success metric for many organizations. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). Is it the WSO2-AM gateway itself, a networking issue, a sudden increase in demand, or something else entirely?
Automated Metric Anomaly Detection. Thanks to the automated dependency information (=Dynatrace Smartscape), Dynatrace’s AI Davis automatically analyzes every single metric along the dependency tree. From here we also get access to all other pod & process relevant metrics, e.g. memory, threads, … or accessing the container logs.
The control plane also provides an API so operators can easily manage traffic control, network resiliency, security and authentication, and custom telemetry data for each service. A service mesh enables DevOps teams to manage their networking and security policies through code. Why do you need a service mesh?
You have to be aware that at any of your digital touchpoints, the digital experience is measured against the best-in-class available coming from Google, Facebook and other digital leaders. If you fail, you are confronted with a complaint on the Google Play store like in the example below. But what happens when it works out differently?
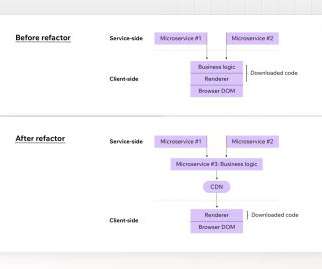
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls. Potential for decreased reliability.
Microservices are run using container-based orchestration platforms like Kubernetes and Docker or cloud-native function-as-a-service (FaaS) offerings like AWS Lambda, Azure Functions, and Google Cloud Functions, all of which help automate the process of managing microservices. Simple network calls. Potential for decreased reliability.
Setting up and monitoring alerts for various metrics—such as resource usage, cost trends, budget thresholds, or deviations from expected spending patterns—can help FinOps teams stay ahead of unexpected expenses or budget overruns. Hyperscaler cloud service providers such as AWS, Microsoft Azure, and Google Cloud Platform can do this, too.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. Define core metrics.
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Infrastructure as a service (IaaS) handles compute, storage, and network resources. In-depth, AI-driven metrics can help to manage this simplicity.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Without agreeing on the single source of truth, you’ll end up in meetings arguing about metrics instead of helping your users. No constraints in form input fields.
After American Family completed its initial conversion to Dynatrace, they needed to automate how their system ingested Amazon CloudWatch metrics. Step 1: Automate AWS metrics ingestion with Dynatrace. Once the accounts are set up in Dynatrace, the system queries Amazon CloudWatch for new metrics every five minutes.
When using managed environments like Google Kubernetes Engine (GKE) , Amazon Elastic Kubernetes (EKS) , or Azure Kubernetes Service it’s easy to spin up a new cluster. metrics, traces, and logs) to gain a better understanding of the behavior of their code during runtime. Metrics are a numeric representation of intervals over time.
To effectively address such warning signs, organizations need to focus on putting observability data into context—mapping and visualizing relationships and dependencies within all collected telemetry data—not only traces, metrics, and logs. OneAgent implements network zones to create traffic routing rules and limit cross-data-center traffic.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. You can’t change that someone was from Nigeria, you can’t change that someone was on a mobile, and you can’t change their network conditions. RTT data should be seen as an insight and not a metric.
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. Modern operating systems provide capabilities to observe and report various metrics about the applications running. The last aspect is the centralization of compute.
Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner. The solution starts with observability, enabling organizations to measure the system states based on their logs, metrics, and traces.
Google has announced that from 1st May, they will start to consider “Page Experience” as part of Search ranking , as measured by a set of metrics called Core Web Vitals. even the Google tools like PageSpeed Insights and the Core Web Vitals report in Google Search Console seem to give confusing information. Barry Pollard.
With so many different metrics available to measure dozens of different aspects of a web page, it can be a struggle to know how best to quantify that page’s overall web performance. Metrics – Thick as Pea Soup. In the early days of performance monitoring, there were far fewer metrics than we have today.
Having the right metrics available on demand and at a high resolution is key to understanding how a system behaves and helps to quickly troubleshoot performance issues. Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? or “are there noisy neighbors affecting my container task?”.
at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., While RAG leverages nearest neighbor metrics based on the relative similarity of texts, graphs allow for better recall of less intuitive connections. at Facebook—both from 2020.
It automates complex tasks during the container’s life cycle, such as provisioning, deployment, networking, scaling, load balancing, and more. Who manages the networking aspects? Kubernetes forged by the rise of Google. Google has been running production workloads in containers longer than any other organization.
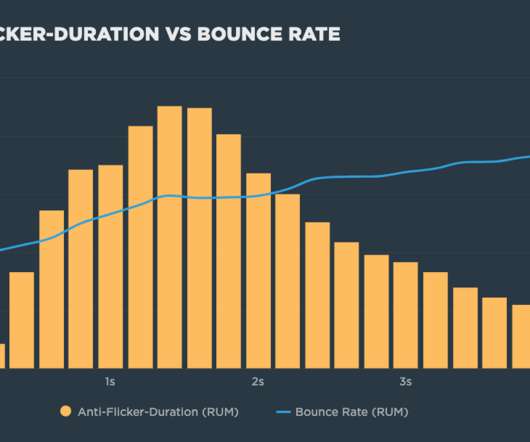
Experimentation tools that use asynchronous scripts – such as Google Optimize, Adobe Target, and Visual Web Optimizer – recommend using an anti-flicker snippet to hide the page until they've finished executing. Google Optimize) has finished applying its experiments. In Google Optimize's default case is the whole document.
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts.
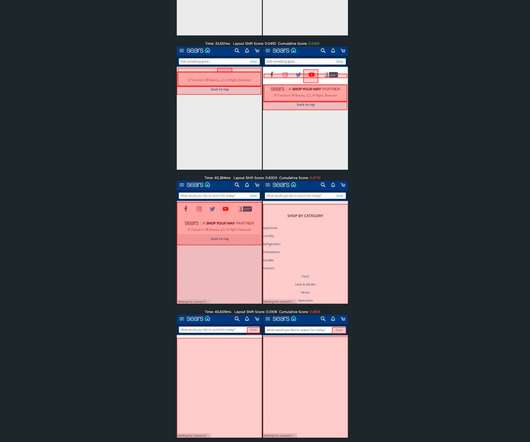
A website’s performance can make or break its success, yet in August 2020, despite many improvements we had previously made, such as implementing Server-Side Rendering (SSR), the ratio of Wix websites with good Google Core Web Vitals (CWV) scores was only 4%. Google search ranking. Large preview ). The Wix Challenge. Heavier websites.
But pages keep getting bigger and more complex year over year – and this increasing size and complexity is not fully mitigated by faster devices and networks, or by our hard-working browsers. How does page bloat affect other metrics, such as Google's Core Web Vitals? This falls short of Google's threshold of 2.5
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. With this objective, the app ensures that users experience real-time feedback and immediate updates when logging workouts, recording sets and reps, or tracking performance metrics.
Essentially, a web vital is a quality standard for UX and web performance set by Google. It can be measured based on real data from users visiting your sites ( field metric ) or in a lab environment ( lab metric ). In fact, several user-centric metrics are used to quantify web vitals. PageSpeed Compare. Large preview ).
Nines are not enough: meaningful metrics for clouds Mogul & Wilkes, HotOS’19. The authors of today’s paper should know a thing or two about that: Jeffrey Mogul and John Wilkes at Google 1 ! It’s hard to define good SLOs, especially when outcomes aren’t fully under the control of any single party.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content