This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Thats why Dynatrace will make its AI-powered, unified observability platform generally available on Google Cloud for all customers later this year. Starting in May, selected customers will get to experience all the latest Dynatrace platform features, including the Grail data lakehouse, Davis AI, and unrivaled log analytics, on Google Cloud.
The annual Google Cloud Next conference explores the latest innovations for cloud technology and Google Cloud. This year, Google’s event will take place from April 9 to 11 in Las Vegas. Google Cloud users will come together to learn from Google experts and partners on topics from generative AI to cloud operations and security.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Recently, we’ve expanded our digital experience monitoring to cover the entire customer journey, from conversion to fulfillment. Google or Adobe Analytics).
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
As a leader in cloud infrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. However, as businesses migrate to the Google Cloud Platform, they’re faced with even more complex, distributed environments that are inherently difficult to observe and operate.
In the webinar “ Intelligent Kubernetes observability and automation ,” Dynatrace expert Henrik Rexed and GCP experts Gari Singh and Alisha Stull provide insights into leveraging AI-powered observability and automation to gain granular insights into Kubernetes environments on Google Cloud Platform at an enterprise scale.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. What is Google Cloud Functions? Google Cloud Functions is a serverless compute service for creating and launching microservices.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Synthetic monitors help you find issues before they affect your customers.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. First, we create a small Kubernetes cluster in the Google Cloud Console.
In October 2021, Dynatrace announced the availability of the Dynatrace Software Intelligence Platform on Google Cloud as a software as a service (SaaS) solution. Dynatrace and Google Cloud play a critical role in helping customers accelerate their digital transformation initiatives. Instance-level visibility for GCP services.
Our procurement decisions were based on trace data that was pulled from a handful of fragmented monitoring solutions. Dynatrace industry-leading tracing, metrics, and log ingestion provide the level of high fidelity data that teams need to make accurate predictions about capacity. Rapid OneAgent rollouts on Google Kubernetes Engine.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
DevOps metrics and digital experience data are critical to this. Bringing teams together around DevOps metrics made it easier for M&B to identify how it could create better digital experiences for its customers and optimize revenue. Dynatrace news. Beginnings of BizDevOps. Why stop at your own virtual walls?
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. by Google Core Web Vitals is?certainly?valuable,?it?leaves
Google has released a new book: The Site Reliability Workbook — Practical Ways to Implement SRE. David Rensin, a SRE at Google, says : It's a whole new book. Monitoring. It's the second book in their SRE series. How is it different than the previous Site Reliability Engineering book? Implementing SLOs. Alerting on SLOs.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
With the platform boasting over 3,000 technical users and millions of end users, Dimitris sheds some light on his experience with SRE, User Experience, and Service Monitoring. Listen in to learn about the innovative steps that the USPTO has taken to develop new ways of working.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Monitoring begins here. Logs, metrics, and traces make up the bulk of all telemetry data. The project released v1.0
If we think back to just a few years ago when most application workloads were primarily monolithic and deployed on-premise, it was fairly simple to gain observability by collecting some logs, metrics and traces, since all the infrastructure was self-owned and the scale was manageable. cloud services and third parties).
How To Monitor And Optimize Google Core Web Vitals How To Monitor And Optimize Google Core Web Vitals Matt Zeunert 2024-04-16T10:00:00+00:00 2024-04-16T12:05:36+00:00 This article is sponsored by DebugBear Google’s Core Web Vitals initiative has increased the attention website owners need to pay to user experience.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Dynatrace Visually complete is a point-in-time web performance metric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: .
You’ve fired up Google Lighthouse from Chrome’s DevTools because everyone and their uncle uses it to evaluate performance. Except, don’t — at least not using Google Lighthouse as your sole proof. Google Lighthouse is merely one tool in a complete performance toolkit. That’s what we’re aiming for, after all!
These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Observability is typically achieved by collecting three types of data from a system, metrics, logs and traces.
Just as people use Xerox as shorthand for paper copies and say “Google” instead of internet search, Docker has become synonymous with containers. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. Built-in monitoring.
Complex syslog ecosystems can be challenging Monitoring devices and applications that provide output via the syslog protocol is a must-have for many organizations. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
Monitor your cloud OpenPipeline ™ is the Dynatrace platform data-handling solution designed to seamlessly ingest and process data from any source, regardless of scale or format. Kubernetes log monitoring with Fluent Bit In an effort to further democratize data, Dynatrace provides a curated and supported OpenTelemetry collector.
Automated Metric Anomaly Detection. Thanks to the automated dependency information (=Dynatrace Smartscape), Dynatrace’s AI Davis automatically analyzes every single metric along the dependency tree. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes.
With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes. Next-gen Infrastructure Monitoring. Next up, Steve introduced enhancements to our infrastructure monitoring module.
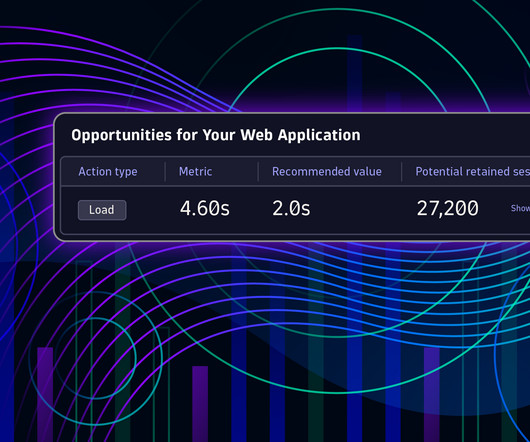
When a page is slow to load, users are quick to abandon the site; research by Google , Vodafone , Akamai , and others has repeatedly shown that even small (~100 ms) degradations in page performance can increase abandonment, lost revenue, and lead to persistent changes in user behavior.
Organizations are constantly being measured against the best available digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Monitoring digital experiences has become increasingly critical for organizations to maintain their competitive edge. Was their operation successful? Break down silos.
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business? which shows your operational efficiency in your software delivery pipeline.
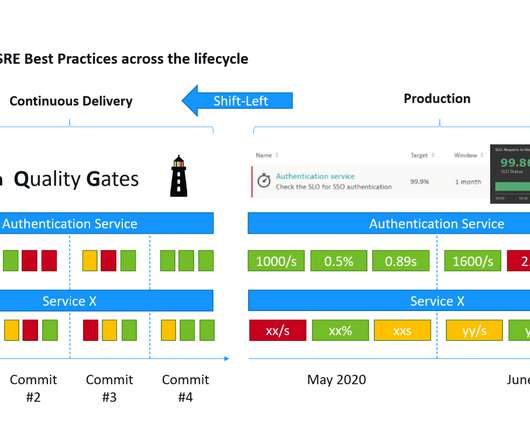
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. In what follows, we explore some of these best practices and guidance for implementing service-level objectives in your monitored environment. Best practices for implementing service-level objectives.
In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). Save hours of bug hunting with out-of-the-box WSO2 API Manager monitoring. Soaring number of active connections.
If you’re not familiar with Site Reliability Engineering (SRE) and the concepts of Service Level Indicators (SLIs), Service Level Objectives (SLOs) and Service Level Agreements (SLAs) I recommend watching the YouTube Video from Google Engineers called SLIs, SLOs, SLAs, oh my! class SRE implements DevOps) !
Leveraging cloud-native technologies like Kubernetes or Red Hat OpenShift in multicloud ecosystems across Amazon Web Services (AWS) , Microsoft Azure, and Google Cloud Platform (GCP) for faster digital transformation introduces a whole host of challenges. Dynatrace news. Collecting data requires massive and ongoing configuration efforts.
Which metrics are relevant for your business, anyway? Modern observability tools provide many metrics, but which ones are really important for your business? Dynatrace offers more than 2000 different metrics that are ready for use as dedicated SLIs. Read more about the basics of Site Reliability Engineering below.).
Empowering teams to manage their FinOps practices, however, requires teams to have access to reliable multicloud monitoring and analysis data. Hyperscaler cloud service providers such as AWS, Microsoft Azure, and Google Cloud Platform can do this, too. They can send a notification saying, “This server is oversized.”
A website needs to be constantly tested and optimized to be in line with Google's web and SEO guidelines. Core Web Vitals is a key performance metric that analyzes the website's performance by investigating the data and provides a strategic platform to scale up the website's user experience. What Is Web Performance Testing?
While microservices vs. monolithic architecture is a common debate, organizations have other considerations, like service-oriented architecture (SOA), tools, monitoring solutions, and potential migration issues. In fact, giants like Google and Microsoft once employed monolithic architectures almost exclusively. Service mesh.
SLOs cover a wide range of monitoring options for different applications. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. One template explicitly targets service performance monitoring.
I was browsing Tim Kadlec’s website and I noticed he had added page load time metrics in the footer. If your browser supports the Paint Timing API you will see a couple of extra metrics: First Paint and First Contentful Paint. First Paint and First Contentful Paint Page load time is a metric that tells us part of the story.
At this year’s Perform, we are thrilled to have our three strategic cloud partners, Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), returning as both sponsors and presenters to share their expertise about cloud modernization and observability of generative AI models.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content