This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
First, it helps to understand that applications and all the services and infrastructure that support them generate telemetry data based on traffic from real users. Latency is the time that it takes a request to be served. So how can teams start implementing SLOs? This telemetry data serves as the basis for establishing meaningful SLOs.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
For example, to handle traffic spikes and pay only for what they use. These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Scale automatically based on the demand and traffic patterns.
In their new dashboard, they added dimensions for load, latency, and open problems for each component. To ensure their global service levels, they fully embraced the best practices outlined in Google’s SRE handbook , called the “Four Golden Signals,” to standardize what they show on their SRE dashboards. Saturation.
At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems. It detects regressions and deviations from previously observed behavior across metrics such as latency, traffic, error rates, saturation, security coverage, vulnerability risk levels, and memory consumption.
Prodicle Distribution Our service is required to be elastic and handle bursty traffic. It also needs to handle third-party integration with Google Drive, making copies of PDFs with watermarks specific to each recipient, adding password protection, creating revocable links, generating thumbnails, and sending emails and push notifications.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
That’s a significant amount and certainly more than is necessary relative to the traffic on most clusters. More acutely, if a traffic spike occurs and Zuul instances scale up, it exponentially increases connections open to origins. Subsetting was also top of mind after reading a recent ACM paper published by Google.
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Centralized data will be moved to third party services such as Google Sheets and Airtable for the stakeholders.
Now that Google uses page speed as a ranking factor, many organizations have become laser-focused on performance. Last year, Google made two significant changes to their search indexing and ranking algorithms : In March, indexing became based on the mobile version of a page , rather than desktop. What is Google Lighthouse?
A typical example of modern "microservices-inspired" Java application would function along these lines: Netflix : We observed during experimentation that RAM random read latencies were rarely higher than 1 microsecond whereas typical SSD random read speeds are between 100–500 microseconds.
Snappy is a compression library developed by Google. This is the outbound data traffic without any compression method Here we can see data transmitted is around 2.33MB/s: Now, I’ve enabled zstd compression algorithm in both the server and client client = pymongo.MongoClient("mongodb://user:pwd@xx.xx.xx.xx:27017/?
At Google I/O 2014 , Lara Swanson and Paul Lewis discussed performance culture. Mobile networks add a tremendous amount of latency. Look at your traffic stats, load stats and render stats to better understand the shape of your site and how visitors are using it. We are not our end users. We need to build a performance culture.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. Ilya Grigorik. 2021-11-08T14:30:00+00:00. 2021-11-08T19:34:34+00:00. Commerce At Shopify Scale: Hydrogen Powered By Oxygen.
Meanwhile, on Android, the #2 and #3 sources of web traffic do not respect browser choice. Google's Search App and Facebook's various apps for Android undermine these choices in slightly different ways. [3] Developers also suffer higher costs and reduced opportunities to escape Google, Facebook, and Apple's walled gardens.
For some background, Kubernetes was created by Google and is currently maintained by the Cloud Native Computing Foundation (CNCF). Applications can be horizontally scaled with Kubernetes by adding or deleting containers based on resource allocation and incoming traffic demands.
Why do we need Lighthouse at all when Google also offers similar reports in PageSpeed Insights (PSI)? CrUX data is important because it is how web core vitals are measured, which, in turn, are a ranking factor for Google’s search results. Still, there’s nothing in there to tell us about the data Lighthouse is using to evaluate metrics.
Google was the first company to create, embrace, and put support behind the role of site reliability engineering. When Google first introduced the role of SRE, they set a goal that half of an SREs time should be focused on reducing future operational work or adding service features.
It increases our visibility and enables us to draw a steady stream of organic (or “free”) traffic to our site. While paid marketing strategies like Google Ads play a part in our approach as well, enhancing our organic traffic remains a major priority. The higher our organic traffic, the more profitable we become as a company.
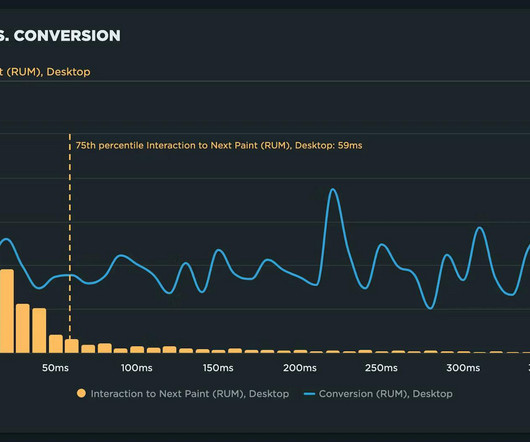
After years of development and testing, Google has added Interaction to Next Paint (INP) to its trifecta of Core Web Vitals – the performance metrics that are a key ingredient in its search ranking algorithm. According to Google, an INP of 200 milliseconds or less is ideal. Not sure what INP means or why it matters? for mobile.
A good SRE engineer will tell you your service is never down. A great SRE engineer will tell you that’s not what you should be measuring. In fact, they’ll tell you their job is customer service.
Modern web applications and pages, such as single-page applications, that put the user experience at its utmost priority are expected to be available 24/7, anywhere in the world, usable on any screen size, secure, flexible, scalable and be ready to meet traffic spikes on demand. Network latency. Network Latency. Connection time.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. TLS, TCP, and QUIC handshake durations ( Large preview ). itself directly.
Rather than buying racks and racks of servers that need to handle the maximum potential traffic and be idle most of the time, it seems that serverless’ method of paying by compute is proving to be beneficial to the bottom lines of organizations. latency, startup, mocking, etc.) Reduction of operational costs” was the No. Figure 13.
Artificial intelligence can automate tasks ranging from: data analysis resource provisioning system maintenance decision-making natural language processing This not only improves accuracy and reliability but also frees up valuable time for IT teams to focus on strategic tasks, such as resource management on platforms like Google Cloud.
those resources now belong to cloud providers, such as AWS Lambda, Google Cloud Platform, Microsoft Azure, and others. However, when the time comes for resources to be requested, there can be latency in the time it takes to for that code to start back up. The time it takes between an action and a response is latency.
Sadly, data on latency is harder to get, even from Google's perch, so progress there is somewhat more difficult to judge. CrUX data collection and first-party RUM analytics of these metrics require live traffic, meaning results can be predicted but only verified once deployed.
Finally, not inlining resources has an added latency cost because the file needs to be requested. mvfst (Facebook), MsQuic , (Microsoft), (Google), ngtcp2 , LSQUIC (Litespeed), picoquic , quicly (Fastly). Note that there is an Apache Traffic Server implementation, though.). Google Chrome (version 91+) : Enabled by default.
However, there is excitement around Starlink for other reasons – namely, the implications it might have for internet speed and latency – even by just a small amount (20 milliseconds on average). Starlink’s Goal: Reduce Internet Latency. What does Starlink and Reduced Latency have to do with me?
Examples include associations with Google Docs, Facebook chat group interactions, streaming live forex market feeds, and managing trading notices. The fundamental principles at play include evenly distributing the workload among servers for better application performance and redirecting client requests to nearby servers to reduce latency.
This is similar to the type of redirect used if you’ve registered multiple domains and you want to direct all of your traffic to your primary URL. In all of these instances, you should identify which URL garners the most traffic and then configure an HTTP 301 -type redirect for all of the lesser-used URLs to the most-trafficked.
Just because everything works perfectly during production testing doesn’t mean that will be the case when your website is flooded with traffic. Bottlenecks can occur, for example, if you have a sudden surge in traffic that your servers are not equipped to handle. What Are the Benefits of Performance Testing?
5G enthusiasts frequently say it’s an enabling technology for autonomous vehicles (AV), which will need high bandwidth to download maps and images, and perhaps even to communicate with each other: AV heaven is a world in which all vehicles are autonomous and can therefore collaboratively plan traffic. I have 30 or 40 GB of photos.
Google recommends that TTFB be 800ms at the 75th percentile. Latency – How much time does it take to deliver a packet from A to B. For example, processing of web application firewall (WAF) rules, detecting bots or other malicious traffic though security services, and growing in popularity, edge compute.
In contrast, tools like DebugBear and WebPageTest use more realistic throttling that accurately reflects network round trips on a higher-latency connection. For example, the data is limited to Chrome users who are logged into their Google account, so it’s not completely representative of all users.
Most existing adtech infrastructure simply can not achieve the required latency. VoltDB provides the necessary technology to achieve the latency required by header bidding. DSPs need to find out the best route to an impression, and will steer traffic towards the best pricing available. Spinning up more servers just won’t cut it.
Most existing adtech infrastructure simply can not achieve the required latency. VoltDB provides the necessary technology to achieve the latency required by header bidding. DSPs need to find out the best route to an impression, and will steer traffic towards the best pricing available. Spinning up more servers just won’t cut it.
Test how user-friendly an application is: Google search engine gives high priority to websites in comparison to desktop apps. Google ranks applications based on how user friendly it is. Google uses mobile-friendly features of websites as a ranking factor. Prioritize browser testing based on usage, market demand, highest traffic.
While this may not seem significant for websites with low traffic, as traffic to the site begins to increase, so does the amount of energy consumed. Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user.
While this may not seem significant for websites with low traffic, as traffic to the site begins to increase, so does the amount of energy consumed. Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user.
While this may not seem significant for websites with low traffic, as traffic to the site begins to increase, so does the amount of energy consumed. Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content