This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
5 FedRAMP (Federal Risk and Authorization Management Program) is a government program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services for U.S. Understanding FedRAMP Moderate and transition to Rev.5 state and federal agencies. FedRAMP Rev.5
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
When tools like GitHub Copilot first appeared, it was received wisdom that AI would make programming easier. It would be a boon to new programmers at the start of their careers, just learning a few new programming languages. As we grow into AI, were growing beyond this makes programming easier. But theyre not here yet.
Using environment automation from both AWS and Dynatrace, supported by the AWS Infrastructure Event Management program , Dynatrace University successfully delivered the required environments – these were three times more than the conference the year before. AWS Infrastructure Event Management program. Quite impressive!
I recently joined two industry veterans and Dynatrace partners, Syed Husain of Orasi and Paul Bruce of Neotys as panelists to discuss how performance engineering and test strategies have evolved as it pertains to customer experience. Dynatrace news. This blog summarizes our great conversation for the posed questions.
Improving Testing and Fuzz Development with Coverage Analysis. In my previous post, we covered using bncov to do open-ended coverage analysis tasks to inform our testing. If we want to improve our confidence, we can add steps to exercise more of the code. Did someone say fuzzy?
Programming Languages , Codewars. CSS Selectors Cheatsheet is an interactive exercise to test your understanding of CSS selectors. The first few are fairly easy but the exercises increase in difficulty as you get into more advanced selectors like lesser-used pseudo-classes. TypeScript Exercises. Service Workers.
Hosted and moderated by Amazon, AWS GameDay is a hands-on, collaborative, gamified learning exercise for applying AWS services and cloud skills to real-world scenarios. Major cloud providers such as AWS offer certification programs to help technology professionals develop and mature their cloud skills.
Don’t assume that applications are free of vulnerabilities because your organization has tooling — such as application security testing — and processes in place. Incorporate planned exercises and workshops to examine and enhance your organization’s readiness through feedback loops.
As patient care continues to evolve, IT teams have accelerated this shift from legacy, on-premises systems to cloud technology to more build, test, and deploy software, and fuel healthcare innovation. Amid so much change, teams can no longer rely on time-consuming, manual approaches for building, testing, operating, and upgrading software.
This is because they are able to leverage free AWS or Azure startup hosting credits secured through their incubator, accelerator, or startup community program, and can apply their free credits to their database hosting costs as ScaleGrid. Expert Tip. Security Groups. Interested in BYOC, but don’t want SSH access? No problem.
Basis path testing in software testing is a white box method where the tester examines the codebase to identify all possible paths that could be taken by the user to achieve their aims. These paths are then written as test cases to ensure all the different identified scenarios in the main branches are covered.
There is a decades-long tradition of data-centric programming : developers who have been using data-centric IDEs, such as RStudio, Matlab, Jupyter Notebooks, or even Excel to model complex real-world phenomena, should find this paradigm familiar. This approach is not novel. Two important trends collide in these lists.
You can always ask a question live , you can share your screen and get immediate feedback, and you can work on group exercises with people around the world. In fact, that’s why we’ve fallen in love with online workshops — and have a full program scheduled for the months to come. Here’s what our workshops are like. Black Belt ??
Tech pundits still seem to commonly assume that UB is so fundamentally entangled in C++s specification and programs that C++ will never be able to address enough UB to really matter. Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues.
See also: ‘ Simple testing can prevent most production failures ‘ and ‘[What bugs cause cloud production incidents?][]’ 48% of partial failures result in some part of the system being unable to make progress (‘stuck’). Generating the watchdogs takes from 5 to 17 minutes depending on the size of the system.
It also generated a short program that implemented the widely used Miller-Rabin primality test. After fixing some obvious errors, I ran the program–and while it told me (correctly) that my number was non-prime, when compared to a known good implementation of Miller-Rabin, ChatGPT’s code made many mistakes.
An assertion documents the expected state of specific program variables at the point where the assertion is written, in a testable way so that we can find program bugs — logic errors that have led to corrupted program state. Assertions are only about finding bugs, not doing program work.
Mar 16, 2024), new things include: A “tersest” function syntax, e.g.: :(x,y) x>y Support all C++23 and draft C++26 headers that have feature test flags Tracked contracts changes in WG21 (e.g., Support all C++23 and draft C++26 headers that have feature test flags. Jul 10, 2024), new things include: Added.
That’s true whether we’re enabling checking at test time (e.g., Some conditions are so expensive that we may never check them without a good reason, even in testing. In GotW #97 question 3, part of the solution says that “if an assertion fails” then… … there is a program bug, possibly in the assertion itself.
This was no small task given the mismatch between a fine granularity of rules on the one hand and a coarse granularity of test cases on the other. The rules were implemented as IFTTT statements in a low-code language that did not allow them to be tested in isolation. In just about every circumstance, it was false results.
Briefly, what is the difference among: (a) undefined behavior Undefined behavior is what happens when your program tries to do something whose meaning is not defined at all in the C++ standard language or library (illegal code and/or data). its results if call sites call it in a way that violates the precondition the assertion is testing.
This can be changed later using the pg_checksums utility, but that will be a painful exercise on a big database. Object-level settings PostgreSQL allows us to specify the parameter specific to a program block, like a PL/pgSQL function. Here is an example of the function definition to test the function-level settings.
It’s also awkward, an exercise of the blindfolded people describing the pachyderm. Some of this is likely a function of professional programming: if, for the totality of your career, the boss has supplied you with the reason why you do the things that you do, it isn’t natural to start a new initiative by asking “why”. And that’s ok.
This ruling in itself raises many questions: how much creativity is needed, and is that the same kind of creativity that an artist exercises with a paintbrush? I can also ask for a reading list about plagues in 16th century England, algorithms for testing prime numbers, or anything else.
Otherwise, you’ll either get the implicitly generated move functions, or else requests to move will automatically just do a copy instead, since copy is always a valid implementation of move (it just doesn’t exercise the non- const option). With IEEE 754 signaling relational comparison, they’re as hard to use as IndirectInt.
Software today is not typically a single program—something that is executed by an operator or user, producing a result to that person—but rather a service : something that runs for the benefit of its consumers, a provider of value. The most common programming task in the world. Let’s dive into this concept for a bit.
Examples like the following now work… see test file pure2-break-continue.cpp2 for more examples. Examples like the following now work… see test file pure2-break-continue.cpp2 for more examples. For example, see the test case pure2-types-order-independence-and-nesting.cpp2. this defaults to the current type.
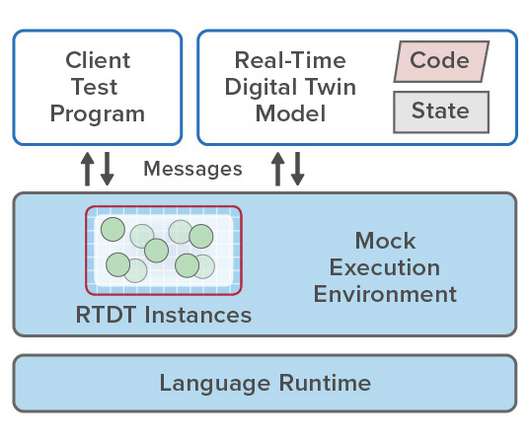
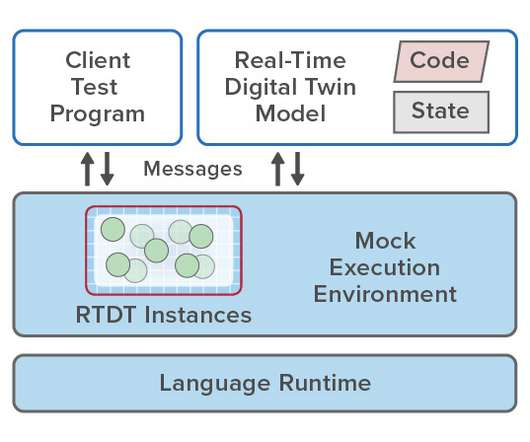
Development is fast and straightforward using standard object-oriented techniques, and the test/debug cycle is kept short by making use of a mock environment running on the developer’s workstation. This exercises the model’s code and surfaces issues and exceptions, which can be readily examined and resolved in a controlled environment.
Development is fast and straightforward using standard object-oriented techniques, and the test/debug cycle is kept short by making use of a mock environment running on the developer’s workstation. This exercises the model’s code and surfaces issues and exceptions, which can be readily examined and resolved in a controlled environment.
Regression testing comprises re-running the test cases of already stable features and finding out if the new code changes attributed to the new release led to any negative impacts on the existing functionalities. When is Regression Testing done? Regression tests should be performed just after the sanity testing is complete.
Traditional IT projects are mass economy-of-scale exercises: once development begins, armies of developers are unleashed. Traditionally in IT, our gatekeepers are typically several different waves of requirements and specification documents, then software, then test results, then a production event.
Large projects like browser engines also exercise governance through a hierarchy of "OWNER bits," which explicitly name engineers empowered to permit changes in a section of the codebase. Differences in uptake rates matter because it's only by updating a program on the user's devices that fixes can begin to protect users.
Testing and grading their solutions is another! Although we added tests to catch specific issues as we learned of them, we found it difficult to keep up with the diversity of possible student errors. Testing and model checking. It’s hard to exhaustively test a distributed system with traditional testing techniques.
The exercise of assessing, modeling and dispositioning the landscape does offer valuable new ways of looking at legacy assets. Tight coupling of code to data (think COBOL programs to VSAM files, or ABAP programs to customized tables in SAP) makes code difficult to recompose into new structures.
Program Management Offices (PMOs) are at the nexus of this. Those individually-performed tasks need to be integrated and then tested from end-to-end. End-to-end testing - the best indicator of success - can't take place until integration is complete. This is nothing new to IT, as projects suddenly crater all the time.
Some of these are exercised by the “wrong order” permutations above, but even call sites that remember the right argument order can make mistakes about the actual values. P0542: Support for contract based programming in C++” (WG21 paper, June 2018). is_reachable? Dos Reis, J. Meredith, N. Myers, and B. Stroustrup.
The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. Tests on one TACC development node gave slightly higher results — 2148 GFLOPS to 2254 GFLOPS (average = 2235 GFLOPS), for a set of 180 trials of a DGEMM test with M=N=K=8000 and using all 68 cores.
There was no deep goal — just a desire to see the maximum GFLOPS in action. The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. Single-core testing with the same DGEMM routine showed maximum values of just under 72% of the nominal peak (about 90% of “adjusted peak”).
Assessment is a necessity, and it’s something corporations take very seriously, at least for in-house training programs. Some other topics with high completion rates are ggplot (for data-driven graphics in R), GitHub, and Selenium (a software testing framework). What are people studying? But is training available on the job?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content