This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. RUM, however, has some limitations, including the following: RUM requires traffic to be useful. Complex transaction and process monitoring that might have deeper dependencies.
Here’s what we discussed so far: In Part 1 we explored how DevOps teams can prevent a process crash from taking down services across an organization. In doing so, they automate build processes to speed up delivery, and minimize human involvement to prevent error. Response time for blue/green environment traffic.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
Functional Testing Functional testing was the most straightforward of them all: a set of tests alongside each path exercised it against the old and new endpoints. In this step, a pipeline picks our candidate change, deploys the service, makes it publicly discoverable, and redirects a small percentage of production traffic to this new service.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. But we can discuss common bottlenecks, how to assess them, and have a better understanding as to why proactive monitoring is so important when it comes to responding to traffic growth.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
The scenario Service considerations In this exercise, we wanted to perform a major version upgrade from PostgreSQL v12.16 Then, we need a small downtime window just to move the traffic from the original instance to the upgraded one. Perform pg_upgrade Execute the pg_upgrade process. to PostgreSQL v15.4. and a v15.4.
Taiji: managing global user traffic for large-scale internet services at the edge Xu et al., It’s another networking paper to close out the week (and our coverage of SOSP’19), but whereas Snap looked at traffic routing within the datacenter, Taiji is concerned with routing traffic from the edge to a datacenter. SOSP’19.
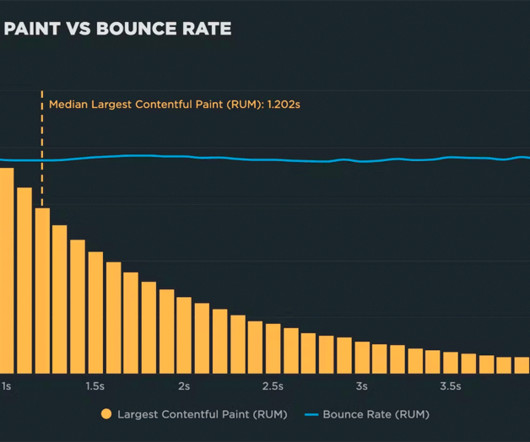
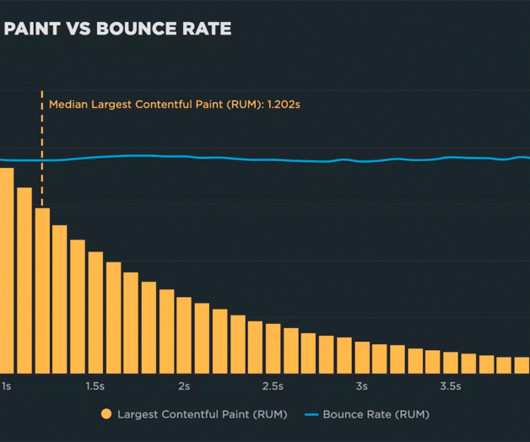
Background For this new investigation, I selected four sites that experience a significant amount of user traffic. Fortunately, the process for identifying the low end of your site’s performance threshold is fairly straightforward. You need to look at your own real user data. (If
Amazon ElastiCache embodies much of what makes fast data a reality for customers looking to process high volume data at incredible rates, faster than traditional databases can manage. Developers love the performance, simplicity, and in-memory capabilities of Redis, making it among the most popular NoSQL key-value stores.
They use a combination of timeouts, retries, and fallbacks to try to mitigate the effects of these failures, but these don’t get exercised as often as the happy path, so how can we be confident they’ll work as intended when called upon? If ChAP detects excessive customer impact during an experiment, the experiment is stopped immediately.
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. A resilient system continues to operate successfully in the presence of failures.
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. A resilient system continues to operate successfully in the presence of failures.
This month and the next I’m going to cover the physical processing aspects of derived tables. That is, does SQL Server perform a substitution process whereby it converts the original nested code into one query that goes directly against the base tables? And if so, is there a way to instruct SQL Server to avoid this unnesting process?
This month and the next I’m going to cover the physical processing aspects of derived tables. That is, does SQL Server perform a substitution process whereby it converts the original nested code into one query that goes directly against the base tables? And if so, is there a way to instruct SQL Server to avoid this unnesting process?
These can be useful exercises, certainly to the business leaders who’ve got to find their customers or compete against rivals with slimmed down cost structures. But the ability to study, process, absorb, investigate and prove ways of exploiting heretofore unrealizable opportunities is priceless. These are less useful.
Buying became an exercise in sourcing for the lowest unit cost any vendor was willing to supply for a particular skill-set. We look to process and organization, coaches and rules. We're not a few coaches and a little bit of process removed from salvation. Selling became a race to the bottom in pricing.
Background For this new investigation, I selected four sites that experience a significant amount of user traffic. Fortunately, the process for identifying the low end of your site’s performance threshold is fairly straightforward. You need to look at your own real user data. (If
I started with a cmd file script exercising the connection path. Running along and all the sudden no traffic occurring at the SQL Server for a few seconds, then stress kicked back in. If the login was in the middle of processing pre-login the ring buffer entry may show time spent in SSL, reads, etc and the disconnect. ·
For example, ghost code - code that is not commented out but will conditionally never be executed - is likely to be confused for real code in a reverse-engineering exercise. A clone of something extinct - our lost business knowledge - runs the risk of suffering severe defects. The facts are fantastic to have, but facts are not knowledge.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Instead, we should process and serve events one at a time as they arrive. Operational use cases are inherently time sensitive by nature.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Instead, we should process and serve events one at a time as they arrive. Operational use cases are inherently time sensitive by nature.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Instead, we should process and serve events one at a time as they arrive. Operational use cases are inherently time sensitive by nature.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content